 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization: A Tale of Two ERMs
Oct 06, 2025Domain generalization (DG) is the problem of generalizing from several distributions (or domains), for which labeled training data are available, to a new test domain for which no labeled data is available. A common finding in the DG literature is that it is difficult to outperform empirical risk minimization (ERM) on the pooled training data. In this work, we argue that this finding has primarily been reported for datasets satisfying a \emph{covariate shift} assumption. When the dataset satisfies a \emph{posterior drift} assumption instead, we show that ``domain-informed ERM,'' wherein feature vectors are augmented with domain-specific information, outperforms pooling ERM. These claims are supported by a theoretical framework and experiments on language and vision tasks.
CliniDial: A Naturally Occurring Multimodal Dialogue Dataset for Team Reflection in Action During Clinical Operation
Jun 15, 2025In clinical operations, teamwork can be the crucial factor that determines the final outcome. Prior studies have shown that sufficient collaboration is the key factor that determines the outcome of an operation. To understand how the team practices teamwork during the operation, we collected CliniDial from simulations of medical operations. CliniDial includes the audio data and its transcriptions, the simulated physiology signals of the patient manikins, and how the team operates from two camera angles. We annotate behavior codes following an existing framework to understand the teamwork process for CliniDial. We pinpoint three main characteristics of our dataset, including its label imbalances, rich and natural interactions, and multiple modalities, and conduct experiments to test existing LLMs' capabilities on handling data with these characteristics. Experimental results show that CliniDial poses significant challenges to the existing models, inviting future effort on developing methods that can deal with real-world clinical data. We open-source the codebase at https://github.com/MichiganNLP/CliniDial
Are Human Interactions Replicable by Generative Agents? A Case Study on Pronoun Usage in Hierarchical Interactions
Jan 25, 2025
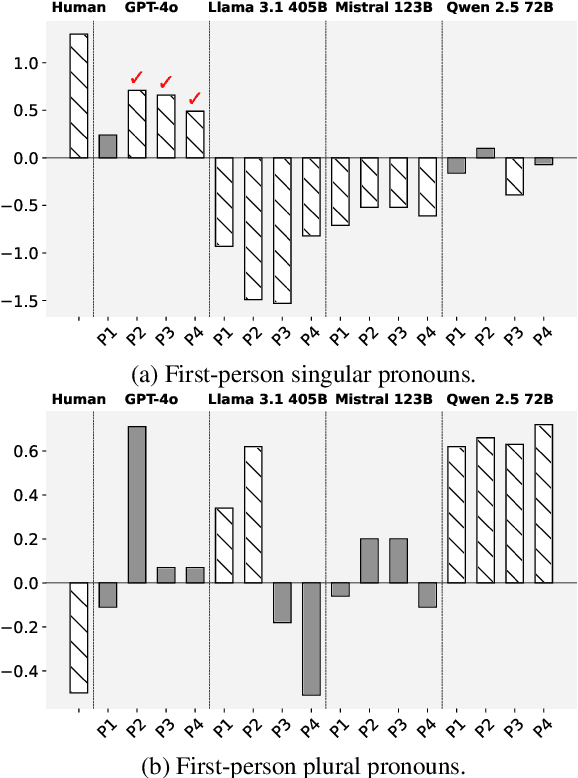
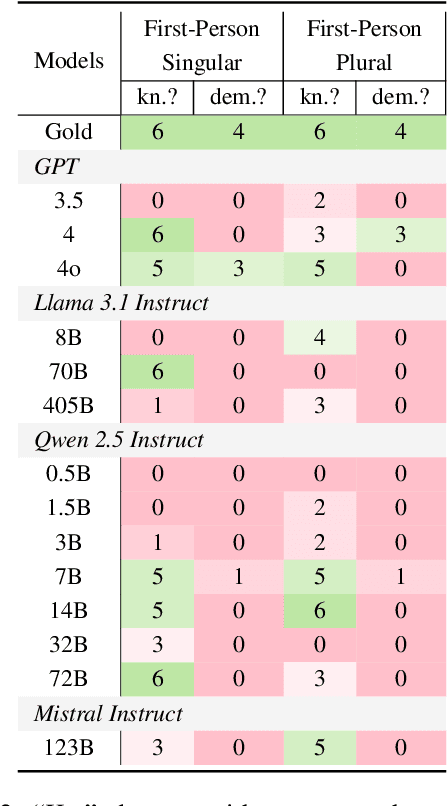
As Large Language Models (LLMs) advance in their capabilities, researchers have increasingly employed them for social simulation. In this paper, we investigate whether interactions among LLM agents resemble those of humans. Specifically, we focus on the pronoun usage difference between leaders and non-leaders, examining whether the simulation would lead to human-like pronoun usage patterns during the LLMs' interactions. Our evaluation reveals the significant discrepancies between LLM-based simulations and human pronoun usage, with prompt-based or specialized agents failing to demonstrate human-like pronoun usage patterns. In addition, we reveal that even if LLMs understand the human pronoun usage patterns, they fail to demonstrate them in the actual interaction process. Our study highlights the limitations of social simulations based on LLM agents, urging caution in using such social simulation in practitioners' decision-making process.
Towards Better Understanding Table Instruction Tuning: Decoupling the Effects from Data versus Models
Jan 24, 2025



Recent advances in natural language processing have leveraged instruction tuning to enhance Large Language Models (LLMs) for table-related tasks. However, previous works train different base models with different training data, lacking an apples-to-apples comparison across the result table LLMs. To address this, we fine-tune base models from the Mistral, OLMo, and Phi families on existing public training datasets. Our replication achieves performance on par with or surpassing existing table LLMs, establishing new state-of-the-art performance on Hitab, a table question-answering dataset. More importantly, through systematic out-of-domain evaluation, we decouple the contributions of training data and the base model, providing insight into their individual impacts. In addition, we assess the effects of table-specific instruction tuning on general-purpose benchmarks, revealing trade-offs between specialization and generalization.
Rethinking Table Instruction Tuning
Jan 24, 2025



Recent advances in table understanding have focused on instruction-tuning large language models (LLMs) for table-related tasks. However, existing research has overlooked the impact of hyperparameter choices and lacks a comprehensive evaluation of the out-of-domain table understanding ability and the general capabilities of these table LLMs. In this paper, we evaluate these abilities in existing table LLMs, and reveal significant declines in both out-of-domain table understanding and general capabilities compared to their base models. Through systematic analysis, we show that hyperparameters, such as learning rate, can significantly influence both table-specific and general capabilities. Contrary to the existing table instruction-tuning works, we demonstrate that smaller learning rates and fewer training instances can enhance table understanding while preserving general capabilities. Based on our findings, we introduce TAMA, a TAble LLM instruction-tuned from LLaMA 3.1 8B Instruct, which achieves performance on par with, or surpassing GPT-3.5 and GPT-4 on table tasks, while maintaining strong out-of-domain generalization and general capabilities. Our findings highlight the potential for reduced data annotation costs and more efficient model development through careful hyperparameter selection.
Table as Thought: Exploring Structured Thoughts in LLM Reasoning
Jan 04, 2025Large language models' reasoning abilities benefit from methods that organize their thought processes, such as chain-of-thought prompting, which employs a sequential structure to guide the reasoning process step-by-step. However, existing approaches focus primarily on organizing the sequence of thoughts, leaving structure in individual thought steps underexplored. To address this gap, we propose Table as Thought, a framework inspired by cognitive neuroscience theories on human thought. Table as Thought organizes reasoning within a tabular schema, where rows represent sequential thought steps and columns capture critical constraints and contextual information to enhance reasoning. The reasoning process iteratively populates the table until self-verification ensures completeness and correctness. Our experiments show that Table as Thought excels in planning tasks and demonstrates a strong potential for enhancing LLM performance in mathematical reasoning compared to unstructured thought baselines. This work provides a novel exploration of refining thought representation within LLMs, paving the way for advancements in reasoning and AI cognition.
Chumor 2.0: Towards Benchmarking Chinese Humor Understanding
Dec 23, 2024



Existing humor datasets and evaluations predominantly focus on English, leaving limited resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, the first Chinese humor explanation dataset that exceeds the size of existing humor datasets. Chumor is sourced from Ruo Zhi Ba, a Chinese Reddit-like platform known for sharing intellectually challenging and culturally specific jokes. We test ten LLMs through direct and chain-of-thought prompting, revealing that Chumor poses significant challenges to existing LLMs, with their accuracy slightly above random and far below human. In addition, our analysis highlights that human-annotated humor explanations are significantly better than those generated by GPT-4o and ERNIE-4-turbo. We release Chumor at https://huggingface.co/datasets/dnaihao/Chumor, our project page is at https://dnaihao.github.io/Chumor-dataset/, our leaderboard is at https://huggingface.co/spaces/dnaihao/Chumor, and our codebase is at https://github.com/dnaihao/Chumor-dataset.
Chumor 1.0: A Truly Funny and Challenging Chinese Humor Understanding Dataset from Ruo Zhi Ba
Jun 18, 2024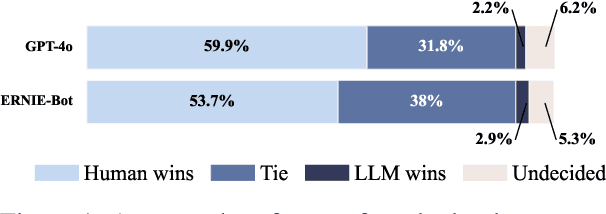

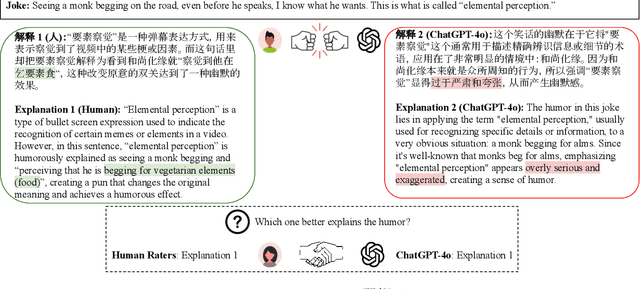
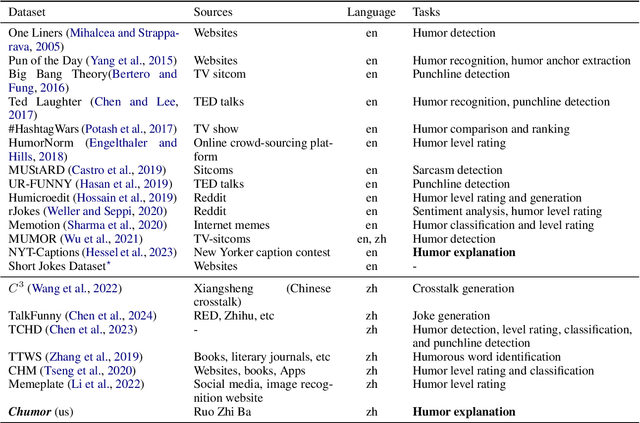
Existing humor datasets and evaluations predominantly focus on English, lacking resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, a dataset sourced from Ruo Zhi Ba (RZB), a Chinese Reddit-like platform dedicated to sharing intellectually challenging and culturally specific jokes. We annotate explanations for each joke and evaluate human explanations against two state-of-the-art LLMs, GPT-4o and ERNIE Bot, through A/B testing by native Chinese speakers. Our evaluation shows that Chumor is challenging even for SOTA LLMs, and the human explanations for Chumor jokes are significantly better than explanations generated by the LLMs.
Tables as Images? Exploring the Strengths and Limitations of LLMs on Multimodal Representations of Tabular Data
Feb 23, 2024

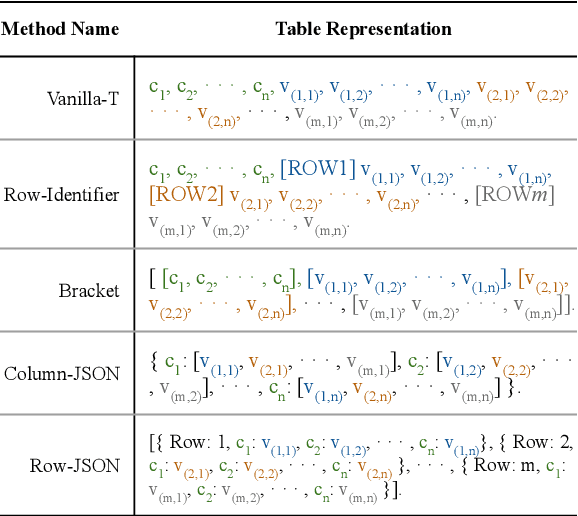

In this paper, we investigate the effectiveness of various LLMs in interpreting tabular data through different prompting strategies and data formats. Our analysis extends across six benchmarks for table-related tasks such as question-answering and fact-checking. We introduce for the first time the assessment of LLMs' performance on image-based table representations. Specifically, we compare five text-based and three image-based table representations, demonstrating the influence of representation and prompting on LLM performance. Our study provides insights into the effective use of LLMs on table-related tasks.
SQL-CRAFT: Text-to-SQL through Interactive Refinement and Enhanced Reasoning
Feb 20, 2024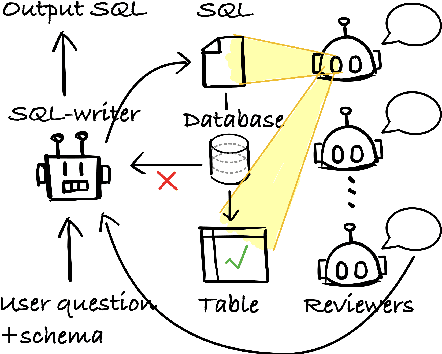
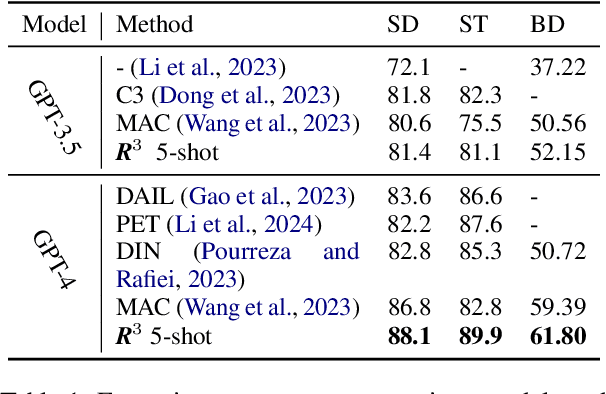
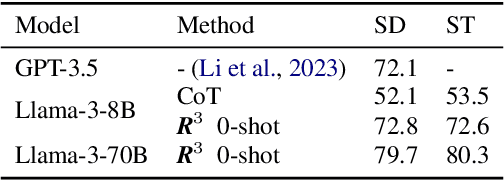
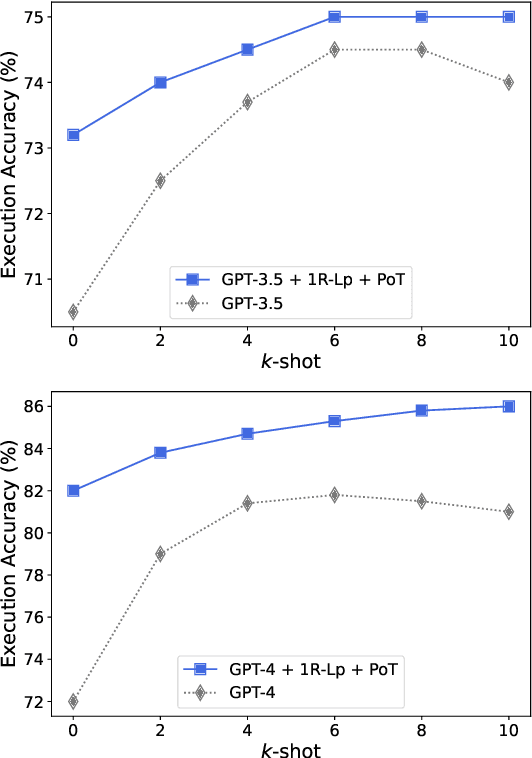
Modern LLMs have become increasingly powerful, but they are still facing challenges in specialized tasks such as Text-to-SQL. We propose SQL-CRAFT, a framework to advance LLMs' SQL generation Capabilities through inteRActive reFinemenT and enhanced reasoning. We leverage an Interactive Correction Loop (IC-Loop) for LLMs to interact with databases automatically, as well as Python-enhanced reasoning. We conduct experiments on two Text-to-SQL datasets, Spider and Bird, with performance improvements of up to 5.7% compared to the naive prompting method. Moreover, our method surpasses the current state-of-the-art on the Spider Leaderboard, demonstrating the effectiveness of our framework.