 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChumor 2.0: Towards Benchmarking Chinese Humor Understanding
Dec 23, 2024



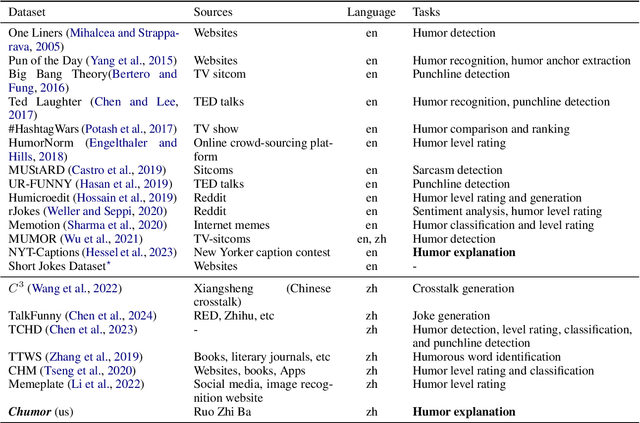
Existing humor datasets and evaluations predominantly focus on English, leaving limited resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, the first Chinese humor explanation dataset that exceeds the size of existing humor datasets. Chumor is sourced from Ruo Zhi Ba, a Chinese Reddit-like platform known for sharing intellectually challenging and culturally specific jokes. We test ten LLMs through direct and chain-of-thought prompting, revealing that Chumor poses significant challenges to existing LLMs, with their accuracy slightly above random and far below human. In addition, our analysis highlights that human-annotated humor explanations are significantly better than those generated by GPT-4o and ERNIE-4-turbo. We release Chumor at https://huggingface.co/datasets/dnaihao/Chumor, our project page is at https://dnaihao.github.io/Chumor-dataset/, our leaderboard is at https://huggingface.co/spaces/dnaihao/Chumor, and our codebase is at https://github.com/dnaihao/Chumor-dataset.
Chumor 1.0: A Truly Funny and Challenging Chinese Humor Understanding Dataset from Ruo Zhi Ba
Jun 18, 2024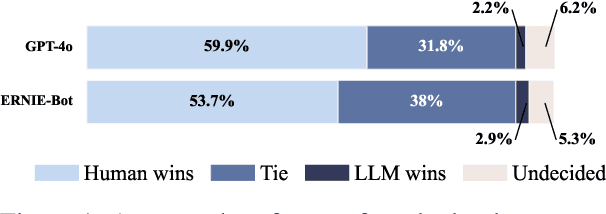

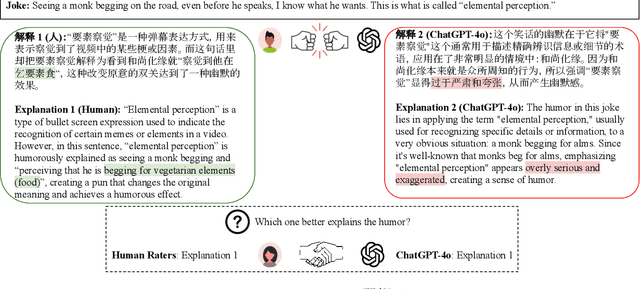
Existing humor datasets and evaluations predominantly focus on English, lacking resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, a dataset sourced from Ruo Zhi Ba (RZB), a Chinese Reddit-like platform dedicated to sharing intellectually challenging and culturally specific jokes. We annotate explanations for each joke and evaluate human explanations against two state-of-the-art LLMs, GPT-4o and ERNIE Bot, through A/B testing by native Chinese speakers. Our evaluation shows that Chumor is challenging even for SOTA LLMs, and the human explanations for Chumor jokes are significantly better than explanations generated by the LLMs.