 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAGEN: Are LLM Agents Budget-Aware?
May 29, 2026While agents are increasingly spending more resources, today agent cost is mostly measured only after execution. A Budget-Aware Agent (BAGEN) should treat budget as an active control signal, rather than a passive cost metric. We first systematically define budget estimation as internal budgets (from agent computation) and external budgets (from agent actions). We then formalize budget-awareness as progressive interval estimation: at each step of a plan, an agent should predict an upper and lower bound on remaining budget, and alert when completion is unlikely. Scoring with a rollout-replay protocol, we find consistent failure patterns on four environments and five frontier agents: (1) strong agents do not necessarily have strong budget-awareness, with correlation r=0.35. (2) frontier models are consistently over-optimistic, continue spending on tasks that are unlikely to succeed, instead of alerting the user early. (3) budget-aware signal is actionable and trainable. Early stop saves 28-64% tokens on failed trajectories, and SFT+RL strengthens early stop and alert behavior. (4) precise interval calibration remains challenging, with interval coverage capping at 47% after SFT+RL. Project page: https://ragen-ai.github.io/bagen/
How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks
Apr 24, 2026The wide adoption of AI agents in complex human workflows is driving rapid growth in LLM token consumption. When agents are deployed on tasks that require a significant amount of tokens, three questions naturally arise: (1) Where do AI agents spend the tokens? (2) Which models are more token-efficient? and (3) Can agents predict their token usage before task execution? In this paper, we present the first systematic study of token consumption patterns in agentic coding tasks. We analyze trajectories from eight frontier LLMs on SWE-bench Verified and evaluate models' ability to predict their own token costs before task execution. We find that: (1) agentic tasks are uniquely expensive, consuming 1000x more tokens than code reasoning and code chat, with input tokens rather than output tokens driving the overall cost; (2) token usage is highly variable and inherently stochastic: runs on the same task can differ by up to 30x in total tokens, and higher token usage does not translate into higher accuracy; instead, accuracy often peaks at intermediate cost and saturates at higher costs; (3) models vary substantially in token efficiency: on the same tasks, Kimi-K2 and Claude-Sonnet-4.5, on average, consume over 1.5 million more tokens than GPT-5; (4) task difficulty rated by human experts only weakly aligns with actual token costs, revealing a fundamental gap between human-perceived complexity and the computational effort agents actually expend; and (5) frontier models fail to accurately predict their own token usage (with weak-to-moderate correlations, up to 0.39) and systematically underestimate real token costs. Our study offers new insights into the economics of AI agents and can inspire future research in this direction.
Chumor 2.0: Towards Benchmarking Chinese Humor Understanding
Dec 23, 2024



Existing humor datasets and evaluations predominantly focus on English, leaving limited resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, the first Chinese humor explanation dataset that exceeds the size of existing humor datasets. Chumor is sourced from Ruo Zhi Ba, a Chinese Reddit-like platform known for sharing intellectually challenging and culturally specific jokes. We test ten LLMs through direct and chain-of-thought prompting, revealing that Chumor poses significant challenges to existing LLMs, with their accuracy slightly above random and far below human. In addition, our analysis highlights that human-annotated humor explanations are significantly better than those generated by GPT-4o and ERNIE-4-turbo. We release Chumor at https://huggingface.co/datasets/dnaihao/Chumor, our project page is at https://dnaihao.github.io/Chumor-dataset/, our leaderboard is at https://huggingface.co/spaces/dnaihao/Chumor, and our codebase is at https://github.com/dnaihao/Chumor-dataset.
The Power of Many: Multi-Agent Multimodal Models for Cultural Image Captioning
Nov 18, 2024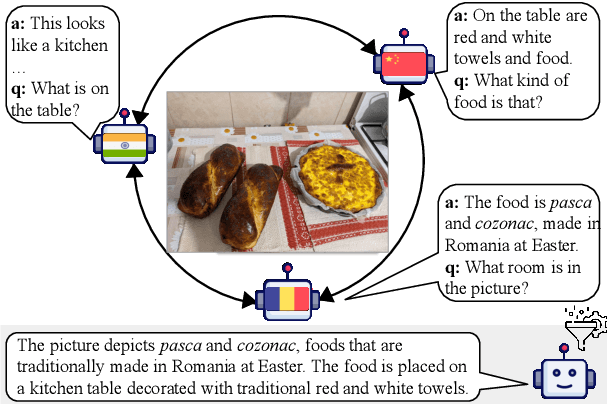
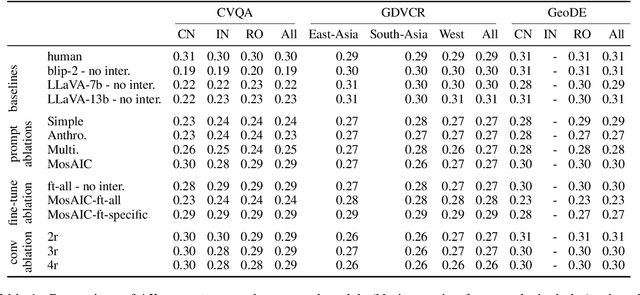
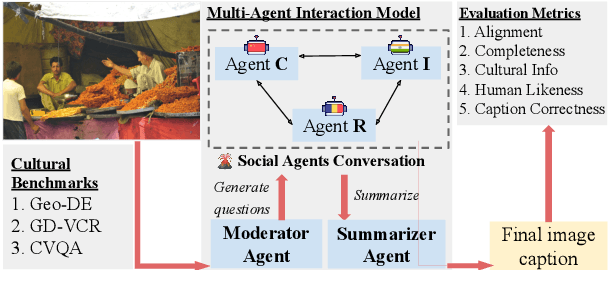
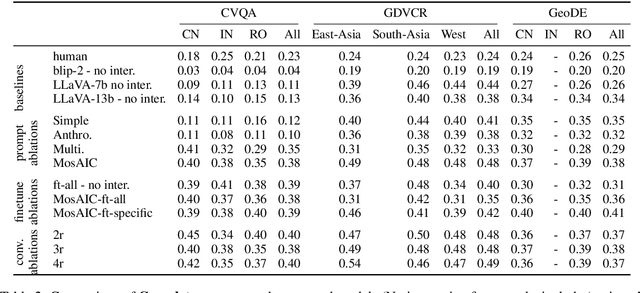
Large Multimodal Models (LMMs) exhibit impressive performance across various multimodal tasks. However, their effectiveness in cross-cultural contexts remains limited due to the predominantly Western-centric nature of most data and models. Conversely, multi-agent models have shown significant capability in solving complex tasks. Our study evaluates the collective performance of LMMs in a multi-agent interaction setting for the novel task of cultural image captioning. Our contributions are as follows: (1) We introduce MosAIC, a Multi-Agent framework to enhance cross-cultural Image Captioning using LMMs with distinct cultural personas; (2) We provide a dataset of culturally enriched image captions in English for images from China, India, and Romania across three datasets: GeoDE, GD-VCR, CVQA; (3) We propose a culture-adaptable metric for evaluating cultural information within image captions; and (4) We show that the multi-agent interaction outperforms single-agent models across different metrics, and offer valuable insights for future research. Our dataset and models can be accessed at https://github.com/MichiganNLP/MosAIC.
Chumor 1.0: A Truly Funny and Challenging Chinese Humor Understanding Dataset from Ruo Zhi Ba
Jun 18, 2024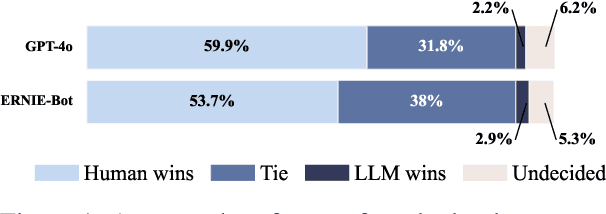

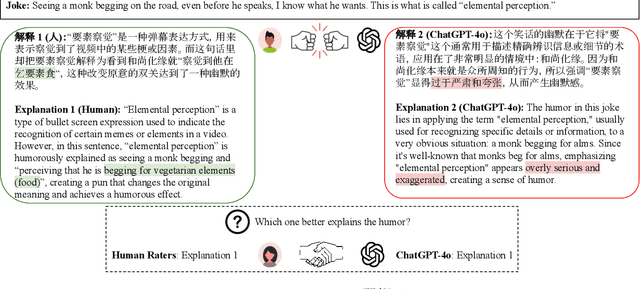
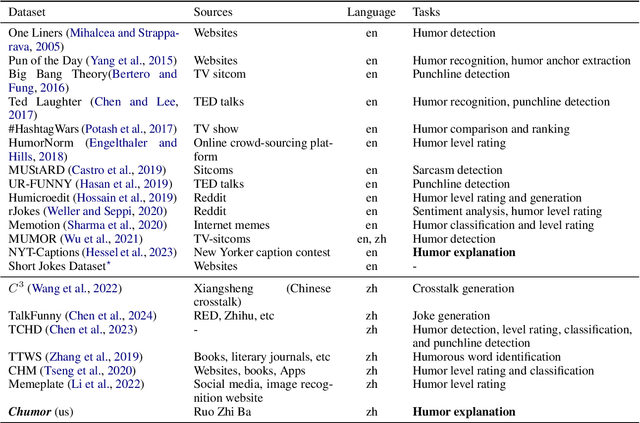
Existing humor datasets and evaluations predominantly focus on English, lacking resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, a dataset sourced from Ruo Zhi Ba (RZB), a Chinese Reddit-like platform dedicated to sharing intellectually challenging and culturally specific jokes. We annotate explanations for each joke and evaluate human explanations against two state-of-the-art LLMs, GPT-4o and ERNIE Bot, through A/B testing by native Chinese speakers. Our evaluation shows that Chumor is challenging even for SOTA LLMs, and the human explanations for Chumor jokes are significantly better than explanations generated by the LLMs.
Graphical Reasoning: LLM-based Semi-Open Relation Extraction
Apr 30, 2024This paper presents a comprehensive exploration of relation extraction utilizing advanced language models, specifically Chain of Thought (CoT) and Graphical Reasoning (GRE) techniques. We demonstrate how leveraging in-context learning with GPT-3.5 can significantly enhance the extraction process, particularly through detailed example-based reasoning. Additionally, we introduce a novel graphical reasoning approach that dissects relation extraction into sequential sub-tasks, improving precision and adaptability in processing complex relational data. Our experiments, conducted on multiple datasets, including manually annotated data, show considerable improvements in performance metrics, underscoring the effectiveness of our methodologies.
Annotations on a Budget: Leveraging Geo-Data Similarity to Balance Model Performance and Annotation Cost
Mar 12, 2024



Current foundation models have shown impressive performance across various tasks. However, several studies have revealed that these models are not effective for everyone due to the imbalanced geographical and economic representation of the data used in the training process. Most of this data comes from Western countries, leading to poor results for underrepresented countries. To address this issue, more data needs to be collected from these countries, but the cost of annotation can be a significant bottleneck. In this paper, we propose methods to identify the data to be annotated to balance model performance and annotation costs. Our approach first involves finding the countries with images of topics (objects and actions) most visually distinct from those already in the training datasets used by current large vision-language foundation models. Next, we identify countries with higher visual similarity for these topics and show that using data from these countries to supplement the training data improves model performance and reduces annotation costs. The resulting lists of countries and corresponding topics are made available at https://github.com/MichiganNLP/visual_diversity_budget.