 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoremForge: Scaling up Formal Data Synthesis with Low-Budget Agentic Workflow
Jan 24, 2026The high cost of agentic workflows in formal mathematics hinders large-scale data synthesis, exacerbating the scarcity of open-source corpora. To address this, we introduce \textbf{TheoremForge}, a cost-effective formal data synthesis pipeline that decomposes the formalization process into five sub-tasks, which are \textit{statement formalization}, \textit{proof generation}, \textit{premise selection}, \textit{proof correction} and \textit{proof sketching}. By implementing a \textit{Decoupled Extraction Strategy}, the workflow recovers valid training signals from globally failed trajectories, effectively utilizing wasted computation. Experiments on a 2,000-problem benchmark demonstrate that TheoremForge achieves a Verified Rate of 12.6\%, surpassing the 8.6\% baseline, at an average cost of only \textbf{\$0.481} per successful trajectory using Gemini-3-Flash. Crucially, our strategy increases data yield by \textbf{1.6$\times$} for proof generation compared to standard filtering. These results establish TheoremForge as a scalable framework for constructing a data flywheel to train future expert models. Our code is available \href{https://github.com/timechess/TheoremForge}{here}.
Retrieval-Augmented Code Generation: A Survey with Focus on Repository-Level Approaches
Oct 06, 2025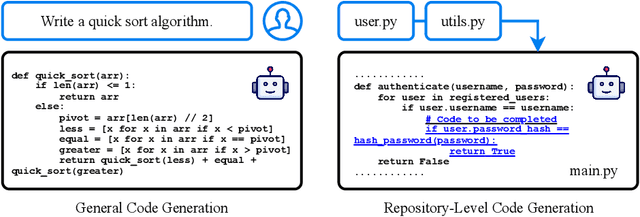

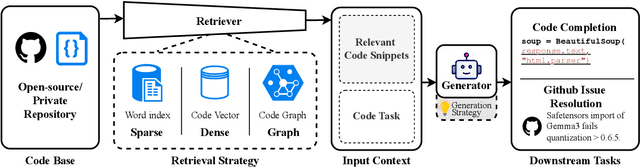
Recent advancements in large language models (LLMs) have substantially improved automated code generation. While function-level and file-level generation have achieved promising results, real-world software development typically requires reasoning across entire repositories. This gives rise to the challenging task of Repository-Level Code Generation (RLCG), where models must capture long-range dependencies, ensure global semantic consistency, and generate coherent code spanning multiple files or modules. To address these challenges, Retrieval-Augmented Generation (RAG) has emerged as a powerful paradigm that integrates external retrieval mechanisms with LLMs, enhancing context-awareness and scalability. In this survey, we provide a comprehensive review of research on Retrieval-Augmented Code Generation (RACG), with an emphasis on repository-level approaches. We categorize existing work along several dimensions, including generation strategies, retrieval modalities, model architectures, training paradigms, and evaluation protocols. Furthermore, we summarize widely used datasets and benchmarks, analyze current limitations, and outline key challenges and opportunities for future research. Our goal is to establish a unified analytical framework for understanding this rapidly evolving field and to inspire continued progress in AI-powered software engineering.
FANNO: Augmenting High-Quality Instruction Data with Open-Sourced LLMs Only
Aug 02, 2024
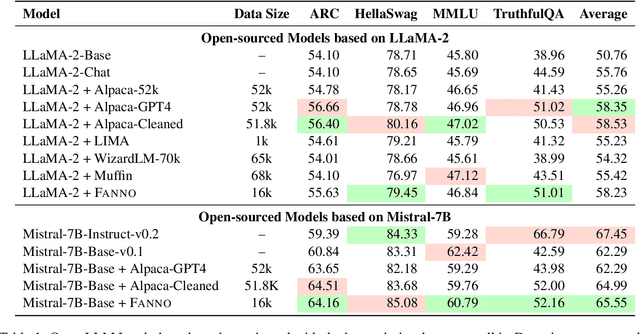
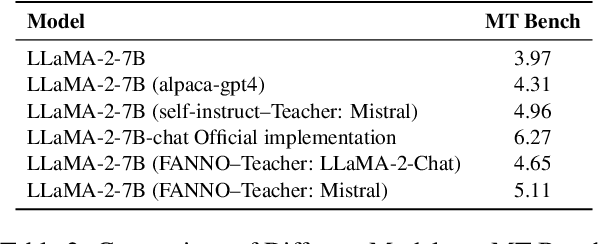
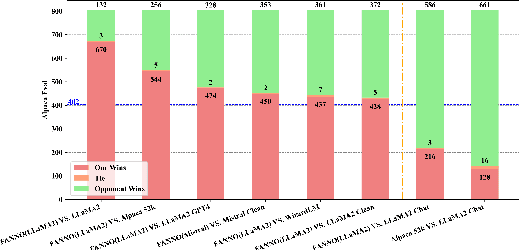
Instruction fine-tuning stands as a crucial advancement in leveraging large language models (LLMs) for enhanced task performance. However, the annotation of instruction datasets has traditionally been expensive and laborious, often relying on manual annotations or costly API calls of proprietary LLMs. To address these challenges, we introduce FANNO, a fully autonomous, open-sourced framework that revolutionizes the annotation process without the need for pre-existing annotated data. Utilizing a Mistral-7b-instruct model, FANNO efficiently produces diverse and high-quality datasets through a structured process involving document pre-screening, instruction generation, and response generation. Experiments on Open LLM Leaderboard and AlpacaEval benchmark show that the FANNO can generate high-quality data with diversity and complexity for free, comparable to human-annotated or cleaned datasets like Alpaca-GPT4-Cleaned.
Graphical Reasoning: LLM-based Semi-Open Relation Extraction
Apr 30, 2024This paper presents a comprehensive exploration of relation extraction utilizing advanced language models, specifically Chain of Thought (CoT) and Graphical Reasoning (GRE) techniques. We demonstrate how leveraging in-context learning with GPT-3.5 can significantly enhance the extraction process, particularly through detailed example-based reasoning. Additionally, we introduce a novel graphical reasoning approach that dissects relation extraction into sequential sub-tasks, improving precision and adaptability in processing complex relational data. Our experiments, conducted on multiple datasets, including manually annotated data, show considerable improvements in performance metrics, underscoring the effectiveness of our methodologies.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024
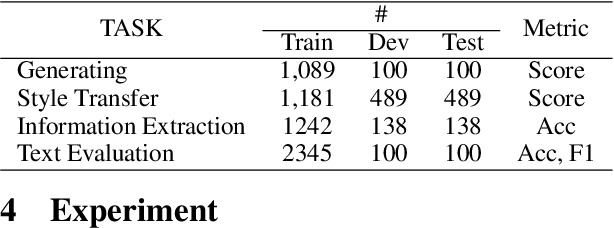
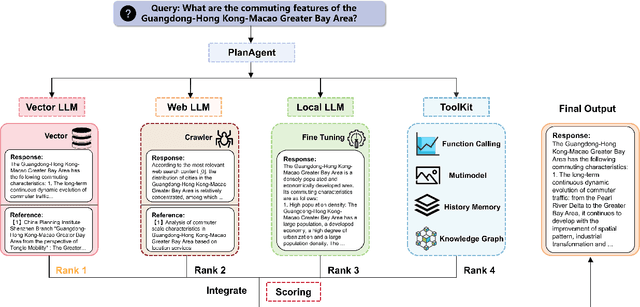
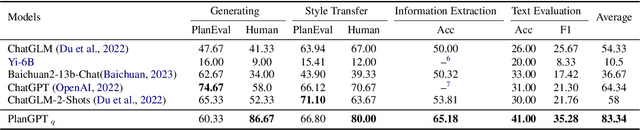
In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.
Learning Sparsity and Randomness for Data-driven Low Rank Approximation
Dec 15, 2022Learning-based low rank approximation algorithms can significantly improve the performance of randomized low rank approximation with sketch matrix. With the learned value and fixed non-zero positions for sketch matrices from learning-based algorithms, these matrices can reduce the test error of low rank approximation significantly. However, there is still no good method to learn non-zero positions as well as overcome the out-of-distribution performance loss. In this work, we introduce two new methods Learning Sparsity and Learning Randomness which try to learn a better sparsity patterns and add randomness to the value of sketch matrix. These two methods can be applied with any learning-based algorithms which use sketch matrix directly. Our experiments show that these two methods can improve the performance of previous learning-based algorithm for both test error and out-of-distribution test error without adding too much complexity.