 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFANNO: Augmenting High-Quality Instruction Data with Open-Sourced LLMs Only
Aug 02, 2024
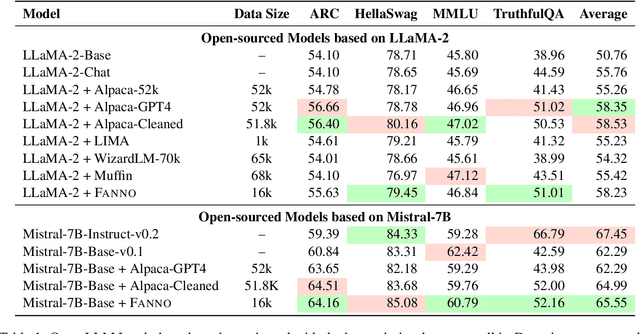
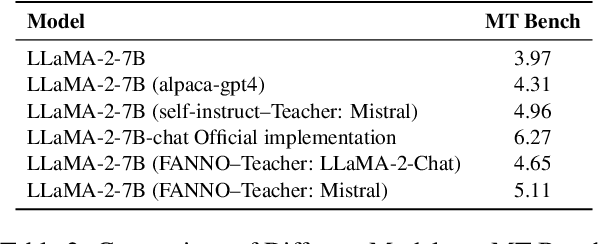
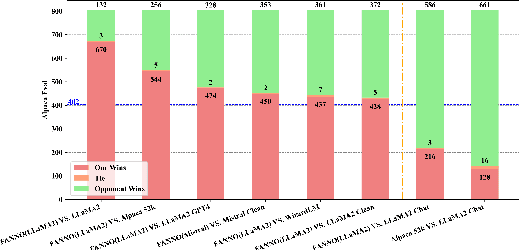
Instruction fine-tuning stands as a crucial advancement in leveraging large language models (LLMs) for enhanced task performance. However, the annotation of instruction datasets has traditionally been expensive and laborious, often relying on manual annotations or costly API calls of proprietary LLMs. To address these challenges, we introduce FANNO, a fully autonomous, open-sourced framework that revolutionizes the annotation process without the need for pre-existing annotated data. Utilizing a Mistral-7b-instruct model, FANNO efficiently produces diverse and high-quality datasets through a structured process involving document pre-screening, instruction generation, and response generation. Experiments on Open LLM Leaderboard and AlpacaEval benchmark show that the FANNO can generate high-quality data with diversity and complexity for free, comparable to human-annotated or cleaned datasets like Alpaca-GPT4-Cleaned.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024
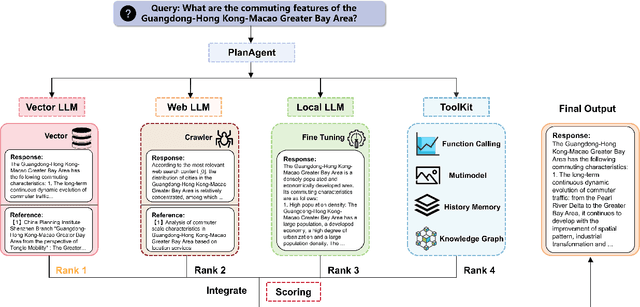
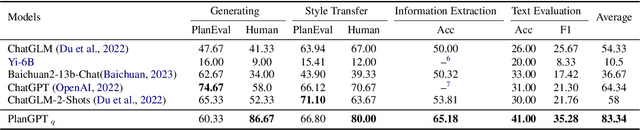
In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.