 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructDiff: Domain-Adaptive Data Selection via Differential Entropy for Efficient LLM Fine-Tuning
Jan 30, 2026Supervised fine-tuning (SFT) is fundamental to adapting large language models, yet training on complete datasets incurs prohibitive costs with diminishing returns. Existing data selection methods suffer from severe domain specificity: techniques optimized for general instruction-following fail on reasoning tasks, and vice versa. We observe that measuring entropy differences between base models and minimally instruction-tuned calibrated models reveals a pattern -- samples with the lowest differential entropy consistently yield optimal performance across domains, yet this principle manifests domain-adaptively: reasoning tasks favor entropy increase (cognitive expansion), while general tasks favor entropy decrease (cognitive compression). We introduce InstructDiff, a unified framework that operationalizes differential entropy as a domain-adaptive selection criterion through warmup calibration, bi-directional NLL filtering, and entropy-based ranking. Extensive experiments show that InstructDiff achieves 17\% relative improvement over full data training on mathematical reasoning and 52\% for general instruction-following, outperforming prior baselines while using only 10\% of the data.
TAG-INSTRUCT: Controlled Instruction Complexity Enhancement through Structure-based Augmentation
May 24, 2025High-quality instruction data is crucial for developing large language models (LLMs), yet existing approaches struggle to effectively control instruction complexity. We present TAG-INSTRUCT, a novel framework that enhances instruction complexity through structured semantic compression and controlled difficulty augmentation. Unlike previous prompt-based methods operating on raw text, TAG-INSTRUCT compresses instructions into a compact tag space and systematically enhances complexity through RL-guided tag expansion. Through extensive experiments, we show that TAG-INSTRUCT outperforms existing instruction complexity augmentation approaches. Our analysis reveals that operating in tag space provides superior controllability and stability across different instruction synthesis frameworks.
PlanGPT-VL: Enhancing Urban Planning with Domain-Specific Vision-Language Models
May 21, 2025In the field of urban planning, existing Vision-Language Models (VLMs) frequently fail to effectively analyze and evaluate planning maps, despite the critical importance of these visual elements for urban planners and related educational contexts. Planning maps, which visualize land use, infrastructure layouts, and functional zoning, require specialized understanding of spatial configurations, regulatory requirements, and multi-scale analysis. To address this challenge, we introduce PlanGPT-VL, the first domain-specific Vision-Language Model tailored specifically for urban planning maps. PlanGPT-VL employs three innovative approaches: (1) PlanAnno-V framework for high-quality VQA data synthesis, (2) Critical Point Thinking to reduce hallucinations through structured verification, and (3) comprehensive training methodology combining Supervised Fine-Tuning with frozen vision encoder parameters. Through systematic evaluation on our proposed PlanBench-V benchmark, we demonstrate that PlanGPT-VL significantly outperforms general-purpose state-of-the-art VLMs in specialized planning map interpretation tasks, offering urban planning professionals a reliable tool for map analysis, assessment, and educational applications while maintaining high factual accuracy. Our lightweight 7B parameter model achieves comparable performance to models exceeding 72B parameters, demonstrating efficient domain specialization without sacrificing performance.
IRSC: A Zero-shot Evaluation Benchmark for Information Retrieval through Semantic Comprehension in Retrieval-Augmented Generation Scenarios
Sep 26, 2024



In Retrieval-Augmented Generation (RAG) tasks using Large Language Models (LLMs), the quality of retrieved information is critical to the final output. This paper introduces the IRSC benchmark for evaluating the performance of embedding models in multilingual RAG tasks. The benchmark encompasses five retrieval tasks: query retrieval, title retrieval, part-of-paragraph retrieval, keyword retrieval, and summary retrieval. Our research addresses the current lack of comprehensive testing and effective comparison methods for embedding models in RAG scenarios. We introduced new metrics: the Similarity of Semantic Comprehension Index (SSCI) and the Retrieval Capability Contest Index (RCCI), and evaluated models such as Snowflake-Arctic, BGE, GTE, and M3E. Our contributions include: 1) the IRSC benchmark, 2) the SSCI and RCCI metrics, and 3) insights into the cross-lingual limitations of embedding models. The IRSC benchmark aims to enhance the understanding and development of accurate retrieval systems in RAG tasks. All code and datasets are available at: https://github.com/Jasaxion/IRSC_Benchmark
FANNO: Augmenting High-Quality Instruction Data with Open-Sourced LLMs Only
Aug 02, 2024
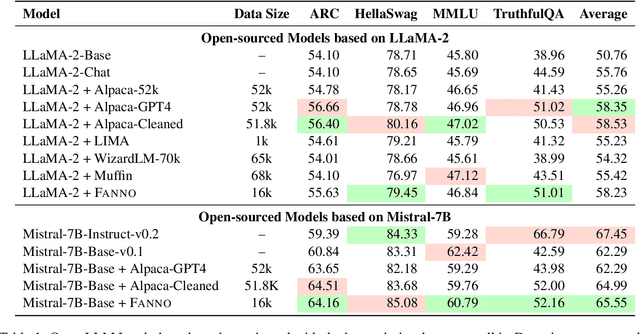
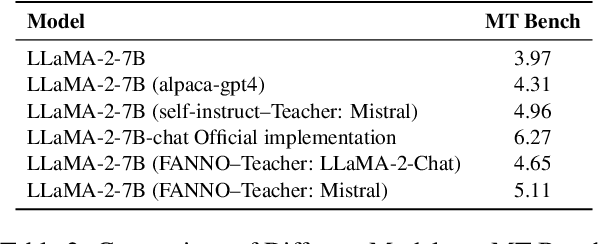
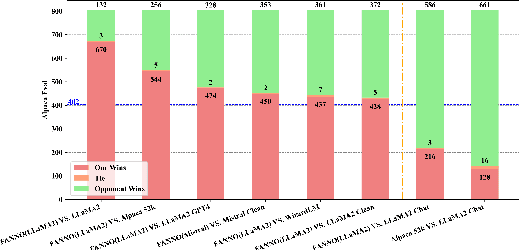
Instruction fine-tuning stands as a crucial advancement in leveraging large language models (LLMs) for enhanced task performance. However, the annotation of instruction datasets has traditionally been expensive and laborious, often relying on manual annotations or costly API calls of proprietary LLMs. To address these challenges, we introduce FANNO, a fully autonomous, open-sourced framework that revolutionizes the annotation process without the need for pre-existing annotated data. Utilizing a Mistral-7b-instruct model, FANNO efficiently produces diverse and high-quality datasets through a structured process involving document pre-screening, instruction generation, and response generation. Experiments on Open LLM Leaderboard and AlpacaEval benchmark show that the FANNO can generate high-quality data with diversity and complexity for free, comparable to human-annotated or cleaned datasets like Alpaca-GPT4-Cleaned.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024
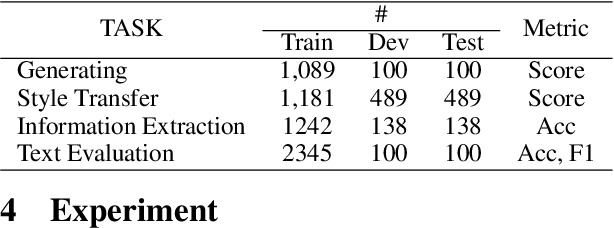
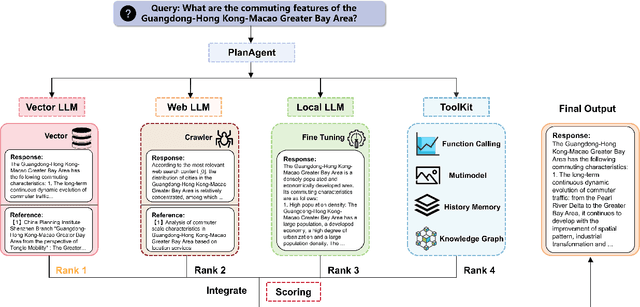
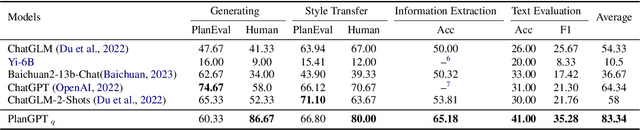
In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.