 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODE: Efficient Time Series Prediction with Mamba Enhanced by Low-Rank Neural ODEs
Jan 01, 2026Time series prediction plays a pivotal role across diverse domains such as finance, healthcare, energy systems, and environmental modeling. However, existing approaches often struggle to balance efficiency, scalability, and accuracy, particularly when handling long-range dependencies and irregularly sampled data. To address these challenges, we propose MODE, a unified framework that integrates Low-Rank Neural Ordinary Differential Equations (Neural ODEs) with an Enhanced Mamba architecture. As illustrated in our framework, the input sequence is first transformed by a Linear Tokenization Layer and then processed through multiple Mamba Encoder blocks, each equipped with an Enhanced Mamba Layer that employs Causal Convolution, SiLU activation, and a Low-Rank Neural ODE enhancement to efficiently capture temporal dynamics. This low-rank formulation reduces computational overhead while maintaining expressive power. Furthermore, a segmented selective scanning mechanism, inspired by pseudo-ODE dynamics, adaptively focuses on salient subsequences to improve scalability and long-range sequence modeling. Extensive experiments on benchmark datasets demonstrate that MODE surpasses existing baselines in both predictive accuracy and computational efficiency. Overall, our contributions include: (1) a unified and efficient architecture for long-term time series modeling, (2) integration of Mamba's selective scanning with low-rank Neural ODEs for enhanced temporal representation, and (3) substantial improvements in efficiency and scalability enabled by low-rank approximation and dynamic selective scanning.
ConInstruct: Evaluating Large Language Models on Conflict Detection and Resolution in Instructions
Nov 19, 2025Instruction-following is a critical capability of Large Language Models (LLMs). While existing works primarily focus on assessing how well LLMs adhere to user instructions, they often overlook scenarios where instructions contain conflicting constraints-a common occurrence in complex prompts. The behavior of LLMs under such conditions remains under-explored. To bridge this gap, we introduce ConInstruct, a benchmark specifically designed to assess LLMs' ability to detect and resolve conflicts within user instructions. Using this dataset, we evaluate LLMs' conflict detection performance and analyze their conflict resolution behavior. Our experiments reveal two key findings: (1) Most proprietary LLMs exhibit strong conflict detection capabilities, whereas among open-source models, only DeepSeek-R1 demonstrates similarly strong performance. DeepSeek-R1 and Claude-4.5-Sonnet achieve the highest average F1-scores at 91.5% and 87.3%, respectively, ranking first and second overall. (2) Despite their strong conflict detection abilities, LLMs rarely explicitly notify users about the conflicts or request clarification when faced with conflicting constraints. These results underscore a critical shortcoming in current LLMs and highlight an important area for future improvement when designing instruction-following LLMs.
TAG-INSTRUCT: Controlled Instruction Complexity Enhancement through Structure-based Augmentation
May 24, 2025High-quality instruction data is crucial for developing large language models (LLMs), yet existing approaches struggle to effectively control instruction complexity. We present TAG-INSTRUCT, a novel framework that enhances instruction complexity through structured semantic compression and controlled difficulty augmentation. Unlike previous prompt-based methods operating on raw text, TAG-INSTRUCT compresses instructions into a compact tag space and systematically enhances complexity through RL-guided tag expansion. Through extensive experiments, we show that TAG-INSTRUCT outperforms existing instruction complexity augmentation approaches. Our analysis reveals that operating in tag space provides superior controllability and stability across different instruction synthesis frameworks.
TUBench: Benchmarking Large Vision-Language Models on Trustworthiness with Unanswerable Questions
Oct 05, 2024

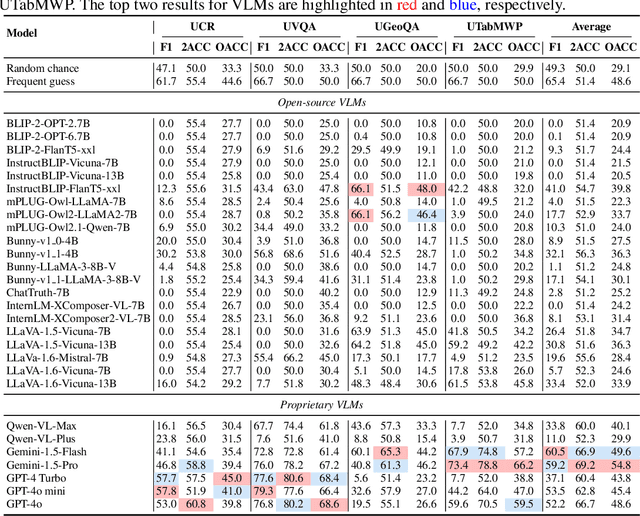

Large Vision-Language Models (LVLMs) have achieved remarkable progress on visual perception and linguistic interpretation. Despite their impressive capabilities across various tasks, LVLMs still suffer from the issue of hallucination, which involves generating content that is incorrect or unfaithful to the visual or textual inputs. Traditional benchmarks, such as MME and POPE, evaluate hallucination in LVLMs within the scope of Visual Question Answering (VQA) using answerable questions. However, some questions are unanswerable due to insufficient information in the images, and the performance of LVLMs on such unanswerable questions remains underexplored. To bridge this research gap, we propose TUBench, a benchmark specifically designed to evaluate the reliability of LVLMs using unanswerable questions. TUBench comprises an extensive collection of high-quality, unanswerable questions that are meticulously crafted using ten distinct strategies. To thoroughly evaluate LVLMs, the unanswerable questions in TUBench are based on images from four diverse domains as visual contexts: screenshots of code snippets, natural images, geometry diagrams, and screenshots of statistical tables. These unanswerable questions are tailored to test LVLMs' trustworthiness in code reasoning, commonsense reasoning, geometric reasoning, and mathematical reasoning related to tables, respectively. We conducted a comprehensive quantitative evaluation of 28 leading foundational models on TUBench, with Gemini-1.5-Pro, the top-performing model, achieving an average accuracy of 69.2%, and GPT-4o, the third-ranked model, reaching 66.7% average accuracy, in determining whether questions are answerable. TUBench is available at https://github.com/NLPCode/TUBench.
A Survey on Point-of-Interest Recommendation: Models, Architectures, and Security
Oct 03, 2024



The widespread adoption of smartphones and Location-Based Social Networks has led to a massive influx of spatio-temporal data, creating unparalleled opportunities for enhancing Point-of-Interest (POI) recommendation systems. These advanced POI systems are crucial for enriching user experiences, enabling personalized interactions, and optimizing decision-making processes in the digital landscape. However, existing surveys tend to focus on traditional approaches and few of them delve into cutting-edge developments, emerging architectures, as well as security considerations in POI recommendations. To address this gap, our survey stands out by offering a comprehensive, up-to-date review of POI recommendation systems, covering advancements in models, architectures, and security aspects. We systematically examine the transition from traditional models to advanced techniques such as large language models. Additionally, we explore the architectural evolution from centralized to decentralized and federated learning systems, highlighting the improvements in scalability and privacy. Furthermore, we address the increasing importance of security, examining potential vulnerabilities and privacy-preserving approaches. Our taxonomy provides a structured overview of the current state of POI recommendation, while we also identify promising directions for future research in this rapidly advancing field.
Enhancing Few-Shot Stock Trend Prediction with Large Language Models
Jul 12, 2024



The goal of stock trend prediction is to forecast future market movements for informed investment decisions. Existing methods mostly focus on predicting stock trends with supervised models trained on extensive annotated data. However, human annotation can be resource-intensive and the annotated data are not readily available. Inspired by the impressive few-shot capability of Large Language Models (LLMs), we propose using LLMs in a few-shot setting to overcome the scarcity of labeled data and make prediction more feasible to investors. Previous works typically merge multiple financial news for predicting stock trends, causing two significant problems when using LLMs: (1) Merged news contains noise, and (2) it may exceed LLMs' input limits, leading to performance degradation. To overcome these issues, we propose a two-step method 'denoising-then-voting'. Specifically, we introduce an `Irrelevant' category, and predict stock trends for individual news instead of merged news. Then we aggregate these predictions using majority voting. The proposed method offers two advantages: (1) Classifying noisy news as irrelevant removes its impact on the final prediction. (2) Predicting for individual news mitigates LLMs' input length limits. Our method achieves 66.59% accuracy in S&P 500, 62.17% in CSI-100, and 61.17% in HK stock prediction, outperforming the standard few-shot counterparts by around 7%, 4%, and 4%. Furthermore, our proposed method performs on par with state-of-the-art supervised methods.
A Survey of Generative Techniques for Spatial-Temporal Data Mining
May 15, 2024



This paper focuses on the integration of generative techniques into spatial-temporal data mining, considering the significant growth and diverse nature of spatial-temporal data. With the advancements in RNNs, CNNs, and other non-generative techniques, researchers have explored their application in capturing temporal and spatial dependencies within spatial-temporal data. However, the emergence of generative techniques such as LLMs, SSL, Seq2Seq and diffusion models has opened up new possibilities for enhancing spatial-temporal data mining further. The paper provides a comprehensive analysis of generative technique-based spatial-temporal methods and introduces a standardized framework specifically designed for the spatial-temporal data mining pipeline. By offering a detailed review and a novel taxonomy of spatial-temporal methodology utilizing generative techniques, the paper enables a deeper understanding of the various techniques employed in this field. Furthermore, the paper highlights promising future research directions, urging researchers to delve deeper into spatial-temporal data mining. It emphasizes the need to explore untapped opportunities and push the boundaries of knowledge to unlock new insights and improve the effectiveness and efficiency of spatial-temporal data mining. By integrating generative techniques and providing a standardized framework, the paper contributes to advancing the field and encourages researchers to explore the vast potential of generative techniques in spatial-temporal data mining.
Improving Factual Error Correction by Learning to Inject Factual Errors
Dec 12, 2023Factual error correction (FEC) aims to revise factual errors in false claims with minimal editing, making them faithful to the provided evidence. This task is crucial for alleviating the hallucination problem encountered by large language models. Given the lack of paired data (i.e., false claims and their corresponding correct claims), existing methods typically adopt the mask-then-correct paradigm. This paradigm relies solely on unpaired false claims and correct claims, thus being referred to as distantly supervised methods. These methods require a masker to explicitly identify factual errors within false claims before revising with a corrector. However, the absence of paired data to train the masker makes accurately pinpointing factual errors within claims challenging. To mitigate this, we propose to improve FEC by Learning to Inject Factual Errors (LIFE), a three-step distantly supervised method: mask-corrupt-correct. Specifically, we first train a corruptor using the mask-then-corrupt procedure, allowing it to deliberately introduce factual errors into correct text. The corruptor is then applied to correct claims, generating a substantial amount of paired data. After that, we filter out low-quality data, and use the remaining data to train a corrector. Notably, our corrector does not require a masker, thus circumventing the bottleneck associated with explicit factual error identification. Our experiments on a public dataset verify the effectiveness of LIFE in two key aspects: Firstly, it outperforms the previous best-performing distantly supervised method by a notable margin of 10.59 points in SARI Final (19.3% improvement). Secondly, even compared to ChatGPT prompted with in-context examples, LIFE achieves a superiority of 7.16 points in SARI Final.
Noisy Pair Corrector for Dense Retrieval
Nov 07, 2023
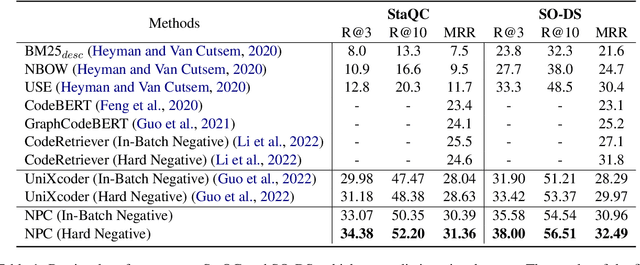
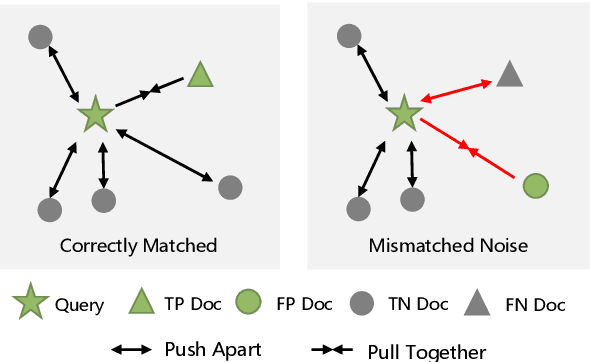
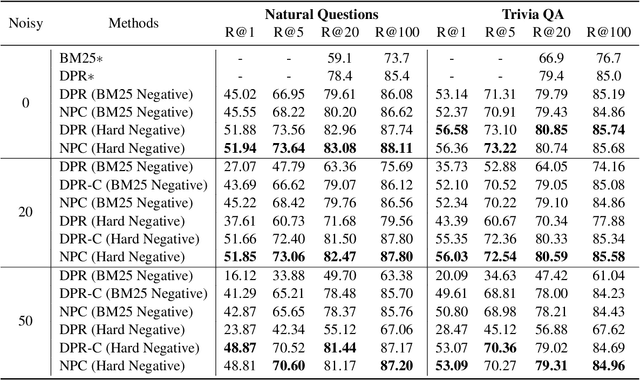
Most dense retrieval models contain an implicit assumption: the training query-document pairs are exactly matched. Since it is expensive to annotate the corpus manually, training pairs in real-world applications are usually collected automatically, which inevitably introduces mismatched-pair noise. In this paper, we explore an interesting and challenging problem in dense retrieval, how to train an effective model with mismatched-pair noise. To solve this problem, we propose a novel approach called Noisy Pair Corrector (NPC), which consists of a detection module and a correction module. The detection module estimates noise pairs by calculating the perplexity between annotated positive and easy negative documents. The correction module utilizes an exponential moving average (EMA) model to provide a soft supervised signal, aiding in mitigating the effects of noise. We conduct experiments on text-retrieval benchmarks Natural Question and TriviaQA, code-search benchmarks StaQC and SO-DS. Experimental results show that NPC achieves excellent performance in handling both synthetic and realistic noise.
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Mar 29, 2023



Many natural language processing (NLP) tasks rely on labeled data to train machine learning models to achieve high performance. However, data annotation can be a time-consuming and expensive process, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator by providing them with sufficient guidance and demonstrated examples. To make LLMs to be better annotators, we propose a two-step approach, 'explain-then-annotate'. To be more precise, we begin by creating prompts for every demonstrated example, which we subsequently utilize to prompt a LLM to provide an explanation for why the specific ground truth answer/label was chosen for that particular example. Following this, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data. We conduct experiments on three tasks, including user input and keyword relevance assessment, BoolQ and WiC. The annotation results from GPT-3.5 surpasses those from crowdsourced annotation for user input and keyword relevance assessment. Additionally, for the other two tasks, GPT-3.5 achieves results that are comparable to those obtained through crowdsourced annotation.