 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024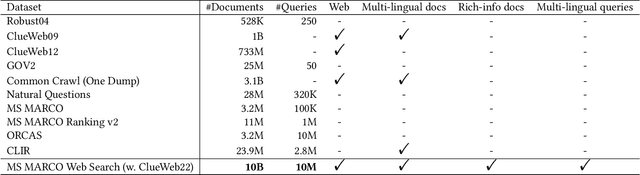
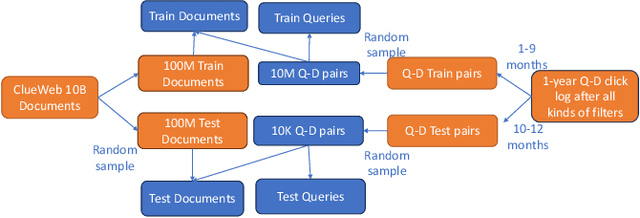
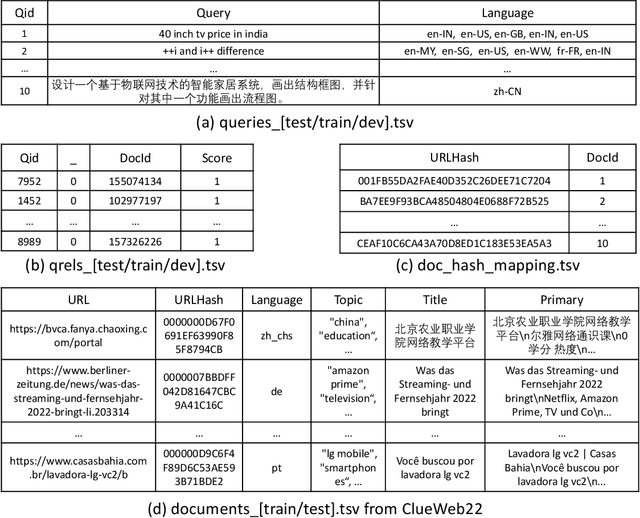
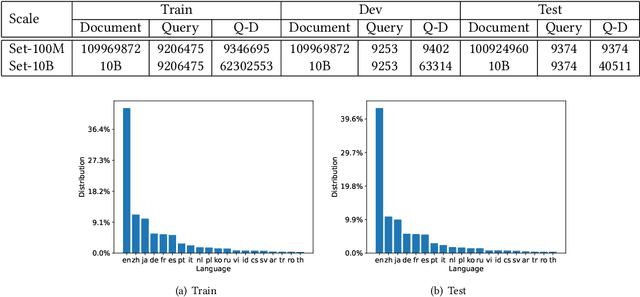
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
Curriculum Sampling for Dense Retrieval with Document Expansion
Dec 18, 2022The dual-encoder has become the de facto architecture for dense retrieval. Typically, it computes the latent representations of the query and document independently, thus failing to fully capture the interactions between the query and document. To alleviate this, recent work expects to get query-informed representations of documents. During training, it expands the document with a real query, while replacing the real query with a generated pseudo query at inference. This discrepancy between training and inference makes the dense retrieval model pay more attention to the query information but ignore the document when computing the document representation. As a result, it even performs worse than the vanilla dense retrieval model, since its performance depends heavily on the relevance between the generated queries and the real query. In this paper, we propose a curriculum sampling strategy, which also resorts to the pseudo query at training and gradually increases the relevance of the generated query to the real query. In this way, the retrieval model can learn to extend its attention from the document only to both the document and query, hence getting high-quality query-informed document representations. Experimental results on several passage retrieval datasets show that our approach outperforms the previous dense retrieval methods1.
LEAD: Liberal Feature-based Distillation for Dense Retrieval
Dec 10, 2022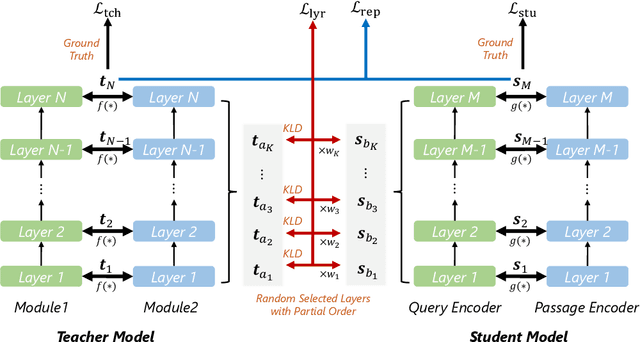
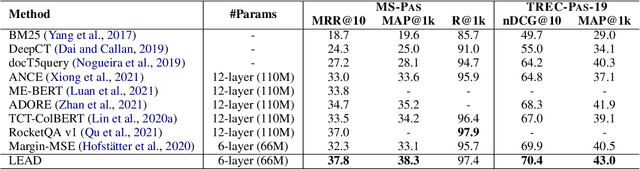
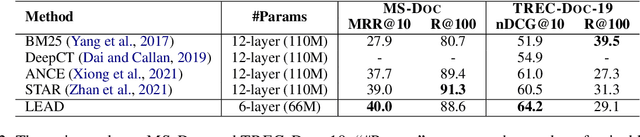
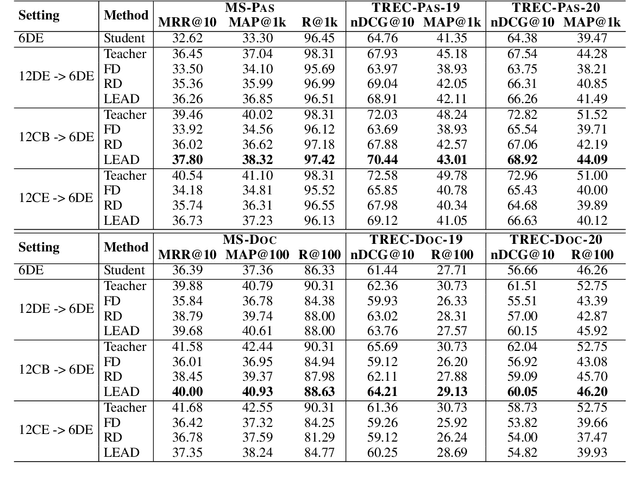
Knowledge distillation is often used to transfer knowledge from a strong teacher model to a relatively weak student model. Traditional knowledge distillation methods include response-based methods and feature-based methods. Response-based methods are used the most widely but suffer from lower upper limit of model performance, while feature-based methods have constraints on the vocabularies and tokenizers. In this paper, we propose a tokenizer-free method liberal feature-based distillation (LEAD). LEAD aligns the distribution between teacher model and student model, which is effective, extendable, portable and has no requirements on vocabularies, tokenizer, or model architecture. Extensive experiments show the effectiveness of LEAD on several widely-used benchmarks, including MS MARCO Passage, TREC Passage 19, TREC Passage 20, MS MARCO Document, TREC Document 19 and TREC Document 20.
PROD: Progressive Distillation for Dense Retrieval
Sep 27, 2022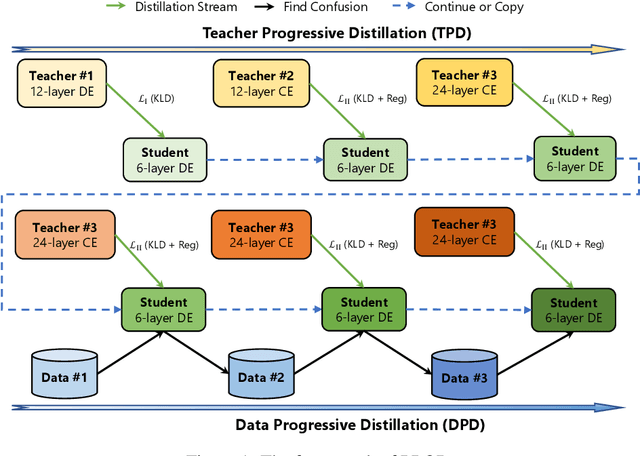
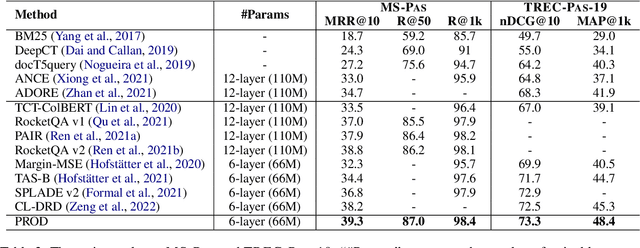
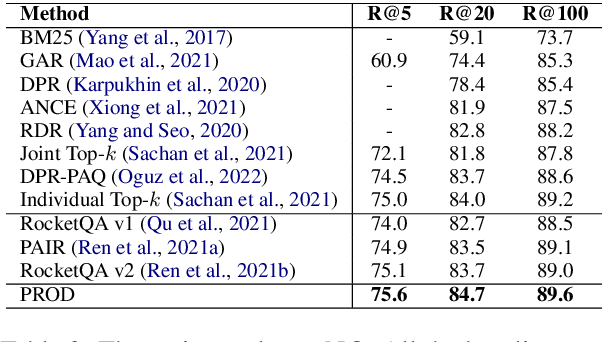
Knowledge distillation is an effective way to transfer knowledge from a strong teacher to an efficient student model. Ideally, we expect the better the teacher is, the better the student. However, this expectation does not always come true. It is common that a better teacher model results in a bad student via distillation due to the nonnegligible gap between teacher and student. To bridge the gap, we propose PROD, a PROgressive Distillation method, for dense retrieval. PROD consists of a teacher progressive distillation and a data progressive distillation to gradually improve the student. We conduct extensive experiments on five widely-used benchmarks, MS MARCO Passage, TREC Passage 19, TREC Document 19, MS MARCO Document and Natural Questions, where PROD achieves the state-of-the-art within the distillation methods for dense retrieval. The code and models will be released.
Less is Less: When Are Snippets Insufficient for Human vs Machine Relevance Estimation?
Jan 21, 2022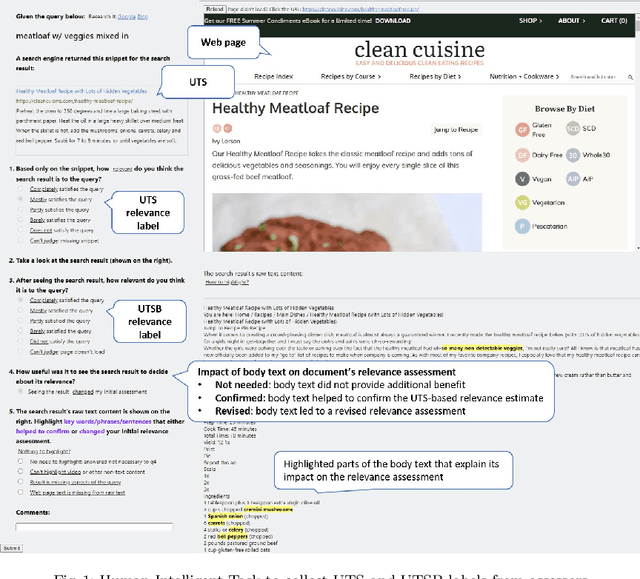

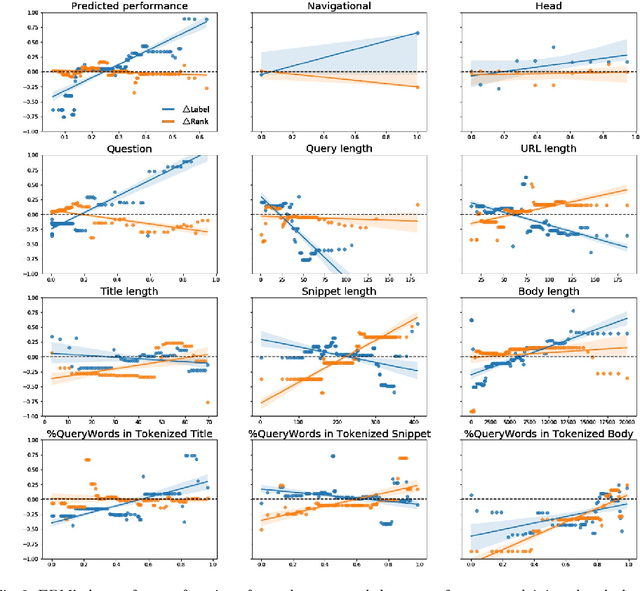

Traditional information retrieval (IR) ranking models process the full text of documents. Newer models based on Transformers, however, would incur a high computational cost when processing long texts, so typically use only snippets from the document instead. The model's input based on a document's URL, title, and snippet (UTS) is akin to the summaries that appear on a search engine results page (SERP) to help searchers decide which result to click. This raises questions about when such summaries are sufficient for relevance estimation by the ranking model or the human assessor, and whether humans and machines benefit from the document's full text in similar ways. To answer these questions, we study human and neural model based relevance assessments on 12k query-documents sampled from Bing's search logs. We compare changes in the relevance assessments when only the document summaries and when the full text is also exposed to assessors, studying a range of query and document properties, e.g., query type, snippet length. Our findings show that the full text is beneficial for humans and a BERT model for similar query and document types, e.g., tail, long queries. A closer look, however, reveals that humans and machines respond to the additional input in very different ways. Adding the full text can also hurt the ranker's performance, e.g., for navigational queries.