 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTUBench: Benchmarking Large Vision-Language Models on Trustworthiness with Unanswerable Questions
Oct 05, 2024

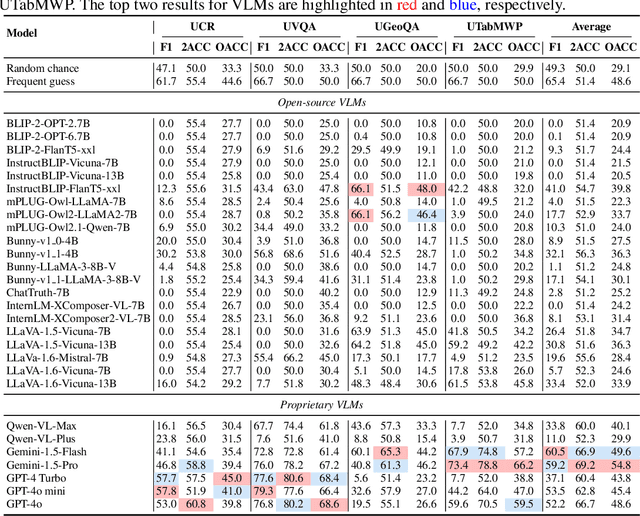

Large Vision-Language Models (LVLMs) have achieved remarkable progress on visual perception and linguistic interpretation. Despite their impressive capabilities across various tasks, LVLMs still suffer from the issue of hallucination, which involves generating content that is incorrect or unfaithful to the visual or textual inputs. Traditional benchmarks, such as MME and POPE, evaluate hallucination in LVLMs within the scope of Visual Question Answering (VQA) using answerable questions. However, some questions are unanswerable due to insufficient information in the images, and the performance of LVLMs on such unanswerable questions remains underexplored. To bridge this research gap, we propose TUBench, a benchmark specifically designed to evaluate the reliability of LVLMs using unanswerable questions. TUBench comprises an extensive collection of high-quality, unanswerable questions that are meticulously crafted using ten distinct strategies. To thoroughly evaluate LVLMs, the unanswerable questions in TUBench are based on images from four diverse domains as visual contexts: screenshots of code snippets, natural images, geometry diagrams, and screenshots of statistical tables. These unanswerable questions are tailored to test LVLMs' trustworthiness in code reasoning, commonsense reasoning, geometric reasoning, and mathematical reasoning related to tables, respectively. We conducted a comprehensive quantitative evaluation of 28 leading foundational models on TUBench, with Gemini-1.5-Pro, the top-performing model, achieving an average accuracy of 69.2%, and GPT-4o, the third-ranked model, reaching 66.7% average accuracy, in determining whether questions are answerable. TUBench is available at https://github.com/NLPCode/TUBench.
Improving Factual Error Correction by Learning to Inject Factual Errors
Dec 12, 2023Factual error correction (FEC) aims to revise factual errors in false claims with minimal editing, making them faithful to the provided evidence. This task is crucial for alleviating the hallucination problem encountered by large language models. Given the lack of paired data (i.e., false claims and their corresponding correct claims), existing methods typically adopt the mask-then-correct paradigm. This paradigm relies solely on unpaired false claims and correct claims, thus being referred to as distantly supervised methods. These methods require a masker to explicitly identify factual errors within false claims before revising with a corrector. However, the absence of paired data to train the masker makes accurately pinpointing factual errors within claims challenging. To mitigate this, we propose to improve FEC by Learning to Inject Factual Errors (LIFE), a three-step distantly supervised method: mask-corrupt-correct. Specifically, we first train a corruptor using the mask-then-corrupt procedure, allowing it to deliberately introduce factual errors into correct text. The corruptor is then applied to correct claims, generating a substantial amount of paired data. After that, we filter out low-quality data, and use the remaining data to train a corrector. Notably, our corrector does not require a masker, thus circumventing the bottleneck associated with explicit factual error identification. Our experiments on a public dataset verify the effectiveness of LIFE in two key aspects: Firstly, it outperforms the previous best-performing distantly supervised method by a notable margin of 10.59 points in SARI Final (19.3% improvement). Secondly, even compared to ChatGPT prompted with in-context examples, LIFE achieves a superiority of 7.16 points in SARI Final.
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Mar 29, 2023



Many natural language processing (NLP) tasks rely on labeled data to train machine learning models to achieve high performance. However, data annotation can be a time-consuming and expensive process, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator by providing them with sufficient guidance and demonstrated examples. To make LLMs to be better annotators, we propose a two-step approach, 'explain-then-annotate'. To be more precise, we begin by creating prompts for every demonstrated example, which we subsequently utilize to prompt a LLM to provide an explanation for why the specific ground truth answer/label was chosen for that particular example. Following this, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data. We conduct experiments on three tasks, including user input and keyword relevance assessment, BoolQ and WiC. The annotation results from GPT-3.5 surpasses those from crowdsourced annotation for user input and keyword relevance assessment. Additionally, for the other two tasks, GPT-3.5 achieves results that are comparable to those obtained through crowdsourced annotation.
Curriculum Sampling for Dense Retrieval with Document Expansion
Dec 18, 2022The dual-encoder has become the de facto architecture for dense retrieval. Typically, it computes the latent representations of the query and document independently, thus failing to fully capture the interactions between the query and document. To alleviate this, recent work expects to get query-informed representations of documents. During training, it expands the document with a real query, while replacing the real query with a generated pseudo query at inference. This discrepancy between training and inference makes the dense retrieval model pay more attention to the query information but ignore the document when computing the document representation. As a result, it even performs worse than the vanilla dense retrieval model, since its performance depends heavily on the relevance between the generated queries and the real query. In this paper, we propose a curriculum sampling strategy, which also resorts to the pseudo query at training and gradually increases the relevance of the generated query to the real query. In this way, the retrieval model can learn to extend its attention from the document only to both the document and query, hence getting high-quality query-informed document representations. Experimental results on several passage retrieval datasets show that our approach outperforms the previous dense retrieval methods1.