 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConInstruct: Evaluating Large Language Models on Conflict Detection and Resolution in Instructions
Nov 19, 2025Instruction-following is a critical capability of Large Language Models (LLMs). While existing works primarily focus on assessing how well LLMs adhere to user instructions, they often overlook scenarios where instructions contain conflicting constraints-a common occurrence in complex prompts. The behavior of LLMs under such conditions remains under-explored. To bridge this gap, we introduce ConInstruct, a benchmark specifically designed to assess LLMs' ability to detect and resolve conflicts within user instructions. Using this dataset, we evaluate LLMs' conflict detection performance and analyze their conflict resolution behavior. Our experiments reveal two key findings: (1) Most proprietary LLMs exhibit strong conflict detection capabilities, whereas among open-source models, only DeepSeek-R1 demonstrates similarly strong performance. DeepSeek-R1 and Claude-4.5-Sonnet achieve the highest average F1-scores at 91.5% and 87.3%, respectively, ranking first and second overall. (2) Despite their strong conflict detection abilities, LLMs rarely explicitly notify users about the conflicts or request clarification when faced with conflicting constraints. These results underscore a critical shortcoming in current LLMs and highlight an important area for future improvement when designing instruction-following LLMs.
Nexus: Execution-Grounded Multi-Agent Test Oracle Synthesis
Oct 30, 2025Test oracle generation in non-regression testing is a longstanding challenge in software engineering, where the goal is to produce oracles that can accurately determine whether a function under test (FUT) behaves as intended for a given input. In this paper, we introduce Nexus, a novel multi-agent framework to address this challenge. Nexus generates test oracles by leveraging a diverse set of specialized agents that synthesize test oracles through a structured process of deliberation, validation, and iterative self-refinement. During the deliberation phase, a panel of four specialist agents, each embodying a distinct testing philosophy, collaboratively critiques and refines an initial set of test oracles. Then, in the validation phase, Nexus generates a plausible candidate implementation of the FUT and executes the proposed oracles against it in a secure sandbox. For any oracle that fails this execution-based check, Nexus activates an automated selfrefinement loop, using the specific runtime error to debug and correct the oracle before re-validation. Our extensive evaluation on seven diverse benchmarks demonstrates that Nexus consistently and substantially outperforms state-of-theart baselines. For instance, Nexus improves the test-level oracle accuracy on the LiveCodeBench from 46.30% to 57.73% for GPT-4.1-Mini. The improved accuracy also significantly enhances downstream tasks: the bug detection rate of GPT4.1-Mini generated test oracles on HumanEval increases from 90.91% to 95.45% for Nexus compared to baselines, and the success rate of automated program repair improves from 35.23% to 69.32%.
EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated Code
May 19, 2025
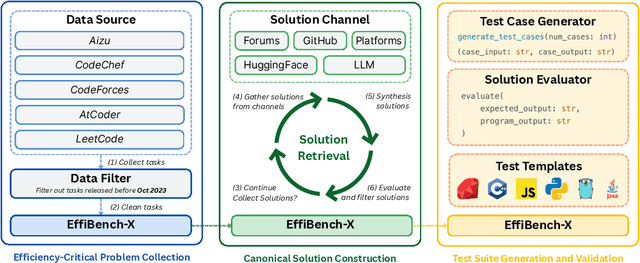


Existing code generation benchmarks primarily evaluate functional correctness, with limited focus on code efficiency and often restricted to a single language like Python. To address this gap, we introduce EffiBench-X, the first multi-language benchmark designed to measure the efficiency of LLM-generated code. EffiBench-X supports Python, C++, Java, JavaScript, Ruby, and Golang. It comprises competitive programming tasks with human-expert solutions as efficiency baselines. Evaluating state-of-the-art LLMs on EffiBench-X reveals that while models generate functionally correct code, they consistently underperform human experts in efficiency. Even the most efficient LLM-generated solutions (Qwen3-32B) achieve only around \textbf{62\%} of human efficiency on average, with significant language-specific variations. LLMs show better efficiency in Python, Ruby, and JavaScript than in Java, C++, and Golang. For instance, DeepSeek-R1's Python code is significantly more efficient than its Java code. These results highlight the critical need for research into LLM optimization techniques to improve code efficiency across diverse languages. The dataset and evaluation infrastructure are submitted and available at https://github.com/EffiBench/EffiBench-X.git and https://huggingface.co/datasets/EffiBench/effibench-x.
HMamba: Hyperbolic Mamba for Sequential Recommendation
May 14, 2025Sequential recommendation systems have become a cornerstone of personalized services, adept at modeling the temporal evolution of user preferences by capturing dynamic interaction sequences. Existing approaches predominantly rely on traditional models, including RNNs and Transformers. Despite their success in local pattern recognition, Transformer-based methods suffer from quadratic computational complexity and a tendency toward superficial attention patterns, limiting their ability to infer enduring preference hierarchies in sequential recommendation data. Recent advances in Mamba-based sequential models introduce linear-time efficiency but remain constrained by Euclidean geometry, failing to leverage the intrinsic hyperbolic structure of recommendation data. To bridge this gap, we propose Hyperbolic Mamba, a novel architecture that unifies the efficiency of Mamba's selective state space mechanism with hyperbolic geometry's hierarchical representational power. Our framework introduces (1) a hyperbolic selective state space that maintains curvature-aware sequence modeling and (2) stabilized Riemannian operations to enable scalable training. Experiments across four benchmarks demonstrate that Hyperbolic Mamba achieves 3-11% improvement while retaining Mamba's linear-time efficiency, enabling real-world deployment. This work establishes a new paradigm for efficient, hierarchy-aware sequential modeling.
M2Rec: Multi-scale Mamba for Efficient Sequential Recommendation
May 07, 2025Sequential recommendation systems aim to predict users' next preferences based on their interaction histories, but existing approaches face critical limitations in efficiency and multi-scale pattern recognition. While Transformer-based methods struggle with quadratic computational complexity, recent Mamba-based models improve efficiency but fail to capture periodic user behaviors, leverage rich semantic information, or effectively fuse multimodal features. To address these challenges, we propose \model, a novel sequential recommendation framework that integrates multi-scale Mamba with Fourier analysis, Large Language Models (LLMs), and adaptive gating. First, we enhance Mamba with Fast Fourier Transform (FFT) to explicitly model periodic patterns in the frequency domain, separating meaningful trends from noise. Second, we incorporate LLM-based text embeddings to enrich sparse interaction data with semantic context from item descriptions. Finally, we introduce a learnable gate mechanism to dynamically balance temporal (Mamba), frequency (FFT), and semantic (LLM) features, ensuring harmonious multimodal fusion. Extensive experiments demonstrate that \model\ achieves state-of-the-art performance, improving Hit Rate@10 by 3.2\% over existing Mamba-based models while maintaining 20\% faster inference than Transformer baselines. Our results highlight the effectiveness of combining frequency analysis, semantic understanding, and adaptive fusion for sequential recommendation. Code and datasets are available at: https://anonymous.4open.science/r/M2Rec.
Low-Rank Adaptation for Foundation Models: A Comprehensive Review
Dec 31, 2024The rapid advancement of foundation modelslarge-scale neural networks trained on diverse, extensive datasetshas revolutionized artificial intelligence, enabling unprecedented advancements across domains such as natural language processing, computer vision, and scientific discovery. However, the substantial parameter count of these models, often reaching billions or trillions, poses significant challenges in adapting them to specific downstream tasks. Low-Rank Adaptation (LoRA) has emerged as a highly promising approach for mitigating these challenges, offering a parameter-efficient mechanism to fine-tune foundation models with minimal computational overhead. This survey provides the first comprehensive review of LoRA techniques beyond large Language Models to general foundation models, including recent techniques foundations, emerging frontiers and applications of low-rank adaptation across multiple domains. Finally, this survey discusses key challenges and future research directions in theoretical understanding, scalability, and robustness. This survey serves as a valuable resource for researchers and practitioners working with efficient foundation model adaptation.
Graph Masked Autoencoder for Spatio-Temporal Graph Learning
Oct 14, 2024Effective spatio-temporal prediction frameworks play a crucial role in urban sensing applications, including traffic analysis, human mobility behavior modeling, and citywide crime prediction. However, the presence of data noise and label sparsity in spatio-temporal data presents significant challenges for existing neural network models in learning effective and robust region representations. To address these challenges, we propose a novel spatio-temporal graph masked autoencoder paradigm that explores generative self-supervised learning for effective spatio-temporal data augmentation. Our proposed framework introduces a spatial-temporal heterogeneous graph neural encoder that captures region-wise dependencies from heterogeneous data sources, enabling the modeling of diverse spatial dependencies. In our spatio-temporal self-supervised learning paradigm, we incorporate a masked autoencoding mechanism on node representations and structures. This mechanism automatically distills heterogeneous spatio-temporal dependencies across regions over time, enhancing the learning process of dynamic region-wise spatial correlations. To validate the effectiveness of our STGMAE framework, we conduct extensive experiments on various spatio-temporal mining tasks. We compare our approach against state-of-the-art baselines. The results of these evaluations demonstrate the superiority of our proposed framework in terms of performance and its ability to address the challenges of spatial and temporal data noise and sparsity in practical urban sensing scenarios.
TUBench: Benchmarking Large Vision-Language Models on Trustworthiness with Unanswerable Questions
Oct 05, 2024

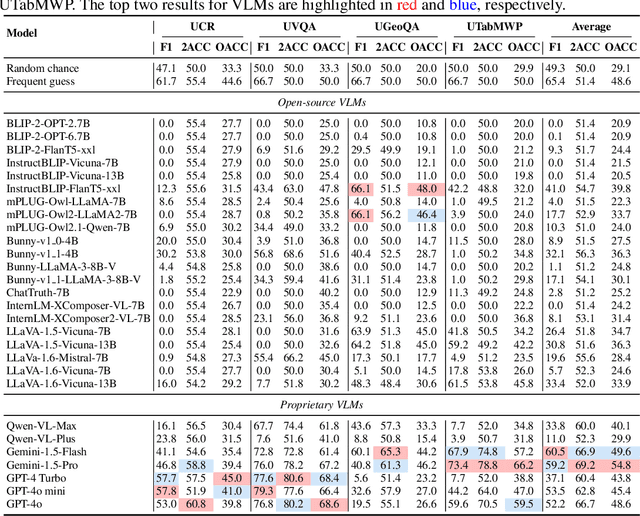

Large Vision-Language Models (LVLMs) have achieved remarkable progress on visual perception and linguistic interpretation. Despite their impressive capabilities across various tasks, LVLMs still suffer from the issue of hallucination, which involves generating content that is incorrect or unfaithful to the visual or textual inputs. Traditional benchmarks, such as MME and POPE, evaluate hallucination in LVLMs within the scope of Visual Question Answering (VQA) using answerable questions. However, some questions are unanswerable due to insufficient information in the images, and the performance of LVLMs on such unanswerable questions remains underexplored. To bridge this research gap, we propose TUBench, a benchmark specifically designed to evaluate the reliability of LVLMs using unanswerable questions. TUBench comprises an extensive collection of high-quality, unanswerable questions that are meticulously crafted using ten distinct strategies. To thoroughly evaluate LVLMs, the unanswerable questions in TUBench are based on images from four diverse domains as visual contexts: screenshots of code snippets, natural images, geometry diagrams, and screenshots of statistical tables. These unanswerable questions are tailored to test LVLMs' trustworthiness in code reasoning, commonsense reasoning, geometric reasoning, and mathematical reasoning related to tables, respectively. We conducted a comprehensive quantitative evaluation of 28 leading foundational models on TUBench, with Gemini-1.5-Pro, the top-performing model, achieving an average accuracy of 69.2%, and GPT-4o, the third-ranked model, reaching 66.7% average accuracy, in determining whether questions are answerable. TUBench is available at https://github.com/NLPCode/TUBench.
A Survey on Point-of-Interest Recommendation: Models, Architectures, and Security
Oct 03, 2024



The widespread adoption of smartphones and Location-Based Social Networks has led to a massive influx of spatio-temporal data, creating unparalleled opportunities for enhancing Point-of-Interest (POI) recommendation systems. These advanced POI systems are crucial for enriching user experiences, enabling personalized interactions, and optimizing decision-making processes in the digital landscape. However, existing surveys tend to focus on traditional approaches and few of them delve into cutting-edge developments, emerging architectures, as well as security considerations in POI recommendations. To address this gap, our survey stands out by offering a comprehensive, up-to-date review of POI recommendation systems, covering advancements in models, architectures, and security aspects. We systematically examine the transition from traditional models to advanced techniques such as large language models. Additionally, we explore the architectural evolution from centralized to decentralized and federated learning systems, highlighting the improvements in scalability and privacy. Furthermore, we address the increasing importance of security, examining potential vulnerabilities and privacy-preserving approaches. Our taxonomy provides a structured overview of the current state of POI recommendation, while we also identify promising directions for future research in this rapidly advancing field.
A Survey of Generative Techniques for Spatial-Temporal Data Mining
May 15, 2024



This paper focuses on the integration of generative techniques into spatial-temporal data mining, considering the significant growth and diverse nature of spatial-temporal data. With the advancements in RNNs, CNNs, and other non-generative techniques, researchers have explored their application in capturing temporal and spatial dependencies within spatial-temporal data. However, the emergence of generative techniques such as LLMs, SSL, Seq2Seq and diffusion models has opened up new possibilities for enhancing spatial-temporal data mining further. The paper provides a comprehensive analysis of generative technique-based spatial-temporal methods and introduces a standardized framework specifically designed for the spatial-temporal data mining pipeline. By offering a detailed review and a novel taxonomy of spatial-temporal methodology utilizing generative techniques, the paper enables a deeper understanding of the various techniques employed in this field. Furthermore, the paper highlights promising future research directions, urging researchers to delve deeper into spatial-temporal data mining. It emphasizes the need to explore untapped opportunities and push the boundaries of knowledge to unlock new insights and improve the effectiveness and efficiency of spatial-temporal data mining. By integrating generative techniques and providing a standardized framework, the paper contributes to advancing the field and encourages researchers to explore the vast potential of generative techniques in spatial-temporal data mining.