 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning and Unlearning for Recommendation with Personalized Data Sharing
Mar 12, 2026Federated recommender systems (FedRS) have emerged as a paradigm for protecting user privacy by keeping interaction data on local devices while coordinating model training through a central server. However, most existing federated recommender systems adopt a one-size-fits-all assumption on user privacy, where all users are required to keep their data strictly local. This setting overlooks users who are willing to share their data with the server in exchange for better recommendation performance. Although several recent studies have explored personalized user data sharing in FedRS, they assume static user privacy preferences and cannot handle user requests to remove previously shared data and its corresponding influence on the trained model. To address this limitation, we propose FedShare, a federated learn-unlearn framework for recommender systems with personalized user data sharing. FedShare not only allows users to control how much interaction data is shared with the server, but also supports data unsharing requests by removing the influence of the unshared data from the trained model. Specifically, FedShare leverages shared data to construct a server-side high-order user-item graph and uses contrastive learning to jointly align local and global representations. In the unlearning phase, we design a contrastive unlearning mechanism that selectively removes representations induced by the unshared data using a small number of historical embedding snapshots, avoiding the need to store large amounts of historical gradient information as required by existing federated recommendation unlearning methods. Extensive experiments on three public datasets demonstrate that FedShare achieves strong recommendation performance in both the learning and unlearning phases, while significantly reducing storage overhead in the unlearning phase compared with state-of-the-art baselines.
Proxy Model-Guided Reinforcement Learning for Client Selection in Federated Recommendation
Aug 14, 2025Federated recommender systems have emerged as a promising privacy-preserving paradigm, enabling personalized recommendation services without exposing users' raw data. By keeping data local and relying on a central server to coordinate training across distributed clients, FedRSs protect user privacy while collaboratively learning global models. However, most existing FedRS frameworks adopt fully random client selection strategy in each training round, overlooking the statistical heterogeneity of user data arising from diverse preferences and behavior patterns, thereby resulting in suboptimal model performance. While some client selection strategies have been proposed in the broader federated learning literature, these methods are typically designed for generic tasks and fail to address the unique challenges of recommendation scenarios, such as expensive contribution evaluation due to the large number of clients, and sparse updates resulting from long-tail item distributions. To bridge this gap, we propose ProxyRL-FRS, a proxy model-guided reinforcement learning framework tailored for client selection in federated recommendation. Specifically, we first introduce ProxyNCF, a dual-branch model deployed on each client, which augments standard Neural Collaborative Filtering with an additional proxy model branch that provides lightweight contribution estimation, thus eliminating the need for expensive per-round local training traditionally required to evaluate a client's contribution. Furthermore, we design a staleness-aware SA reinforcement learning agent that selects clients based on the proxy-estimated contribution, and is guided by a reward function balancing recommendation accuracy and embedding staleness, thereby enriching the update coverage of item embeddings. Experiments conducted on public recommendation datasets demonstrate the effectiveness of ProxyRL-FRS.
M2Rec: Multi-scale Mamba for Efficient Sequential Recommendation
May 07, 2025Sequential recommendation systems aim to predict users' next preferences based on their interaction histories, but existing approaches face critical limitations in efficiency and multi-scale pattern recognition. While Transformer-based methods struggle with quadratic computational complexity, recent Mamba-based models improve efficiency but fail to capture periodic user behaviors, leverage rich semantic information, or effectively fuse multimodal features. To address these challenges, we propose \model, a novel sequential recommendation framework that integrates multi-scale Mamba with Fourier analysis, Large Language Models (LLMs), and adaptive gating. First, we enhance Mamba with Fast Fourier Transform (FFT) to explicitly model periodic patterns in the frequency domain, separating meaningful trends from noise. Second, we incorporate LLM-based text embeddings to enrich sparse interaction data with semantic context from item descriptions. Finally, we introduce a learnable gate mechanism to dynamically balance temporal (Mamba), frequency (FFT), and semantic (LLM) features, ensuring harmonious multimodal fusion. Extensive experiments demonstrate that \model\ achieves state-of-the-art performance, improving Hit Rate@10 by 3.2\% over existing Mamba-based models while maintaining 20\% faster inference than Transformer baselines. Our results highlight the effectiveness of combining frequency analysis, semantic understanding, and adaptive fusion for sequential recommendation. Code and datasets are available at: https://anonymous.4open.science/r/M2Rec.
Sparser Training for On-Device Recommendation Systems
Nov 19, 2024



Recommender systems often rely on large embedding tables that map users and items to dense vectors of uniform size, leading to substantial memory consumption and inefficiencies. This is particularly problematic in memory-constrained environments like mobile and Web of Things (WoT) applications, where scalability and real-time performance are critical. Various research efforts have sought to address these issues. Although embedding pruning methods utilizing Dynamic Sparse Training (DST) stand out due to their low training and inference costs, consistent sparsity, and end-to-end differentiability, they face key challenges. Firstly, they typically initializes the mask matrix, which is used to prune redundant parameters, with random uniform sparse initialization. This strategy often results in suboptimal performance as it creates unstructured and inefficient connections. Secondly, they tend to favor the users/items sampled in the single batch immediately before weight exploration when they reactivate pruned parameters with large gradient magnitudes, which does not necessarily improve the overall performance. Thirdly, while they use sparse weights during forward passes, they still need to compute dense gradients during backward passes. In this paper, we propose SparseRec, an lightweight embedding method based on DST, to address these issues. Specifically, SparseRec initializes the mask matrix using Nonnegative Matrix Factorization. It accumulates gradients to identify the inactive parameters that can better improve the model performance after activation. Furthermore, it avoids dense gradients during backpropagation by sampling a subset of important vectors. Gradients are calculated only for parameters in this subset, thus maintaining sparsity during training in both forward and backward passes.
DecKG: Decentralized Collaborative Learning with Knowledge Graph Enhancement for POI Recommendation
Oct 14, 2024



Decentralized collaborative learning for Point-of-Interest (POI) recommendation has gained research interest due to its advantages in privacy preservation and efficiency, as it keeps data locally and leverages collaborative learning among clients to train models in a decentralized manner. However, since local data is often limited and insufficient for training accurate models, a common solution is integrating external knowledge as auxiliary information to enhance model performance. Nevertheless, this solution poses challenges for decentralized collaborative learning. Due to private nature of local data, identifying relevant auxiliary information specific to each user is non-trivial. Furthermore, resource-constrained local devices struggle to accommodate all auxiliary information, which places heavy burden on local storage. To fill the gap, we propose a novel decentralized collaborative learning with knowledge graph enhancement framework for POI recommendation (DecKG). Instead of directly uploading interacted items, users generate desensitized check-in data by uploading general categories of interacted items and sampling similar items from same category. The server then pretrains KG without sensitive user-item interactions and deploys relevant partitioned sub-KGs to individual users. Entities are further refined on the device, allowing client to client communication to exchange knowledge learned from local data and sub-KGs. Evaluations across two real-world datasets demonstrate DecKG's effectiveness recommendation performance.
PDC-FRS: Privacy-preserving Data Contribution for Federated Recommender System
Sep 12, 2024
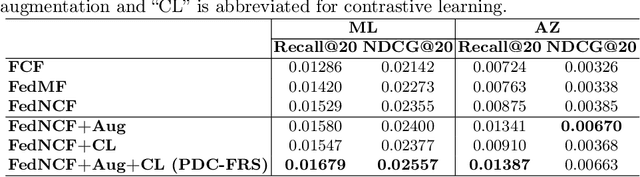
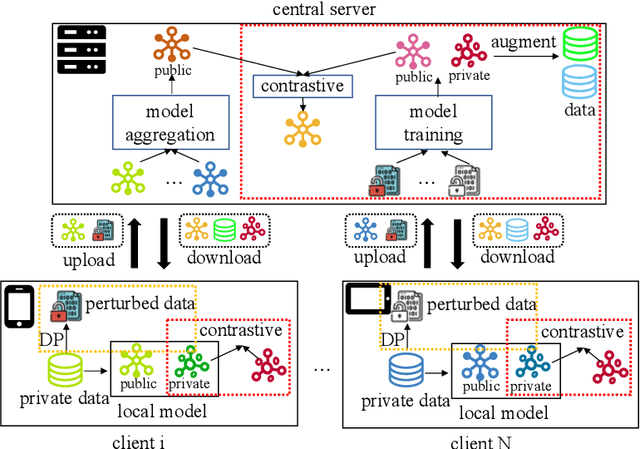
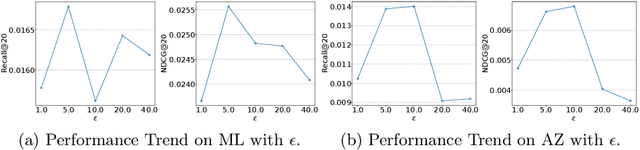
Federated recommender systems (FedRecs) have emerged as a popular research direction for protecting users' privacy in on-device recommendations. In FedRecs, users keep their data locally and only contribute their local collaborative information by uploading model parameters to a central server. While this rigid framework protects users' raw data during training, it severely compromises the recommendation model's performance due to the following reasons: (1) Due to the power law distribution nature of user behavior data, individual users have few data points to train a recommendation model, resulting in uploaded model updates that may be far from optimal; (2) As each user's uploaded parameters are learned from local data, which lacks global collaborative information, relying solely on parameter aggregation methods such as FedAvg to fuse global collaborative information may be suboptimal. To bridge this performance gap, we propose a novel federated recommendation framework, PDC-FRS. Specifically, we design a privacy-preserving data contribution mechanism that allows users to share their data with a differential privacy guarantee. Based on the shared but perturbed data, an auxiliary model is trained in parallel with the original federated recommendation process. This auxiliary model enhances FedRec by augmenting each user's local dataset and integrating global collaborative information. To demonstrate the effectiveness of PDC-FRS, we conduct extensive experiments on two widely used recommendation datasets. The empirical results showcase the superiority of PDC-FRS compared to baseline methods.
Scalable Dynamic Embedding Size Search for Streaming Recommendation
Jul 22, 2024



Recommender systems typically represent users and items by learning their embeddings, which are usually set to uniform dimensions and dominate the model parameters. However, real-world recommender systems often operate in streaming recommendation scenarios, where the number of users and items continues to grow, leading to substantial storage resource consumption for these embeddings. Although a few methods attempt to mitigate this by employing embedding size search strategies to assign different embedding dimensions in streaming recommendations, they assume that the embedding size grows with the frequency of users/items, which eventually still exceeds the predefined memory budget over time. To address this issue, this paper proposes to learn Scalable Lightweight Embeddings for streaming recommendation, called SCALL, which can adaptively adjust the embedding sizes of users/items within a given memory budget over time. Specifically, we propose to sample embedding sizes from a probabilistic distribution, with the guarantee to meet any predefined memory budget. By fixing the memory budget, the proposed embedding size sampling strategy can increase and decrease the embedding sizes in accordance to the frequency of the corresponding users or items. Furthermore, we develop a reinforcement learning-based search paradigm that models each state with mean pooling to keep the length of the state vectors fixed, invariant to the changing number of users and items. As a result, the proposed method can provide embedding sizes to unseen users and items. Comprehensive empirical evaluations on two public datasets affirm the advantageous effectiveness of our proposed method.
PTF-FSR: A Parameter Transmission-Free Federated Sequential Recommender System
Jun 08, 2024Sequential recommender systems have made significant progress. Recently, due to increasing concerns about user data privacy, some researchers have implemented federated learning for sequential recommendation, a.k.a., Federated Sequential Recommender Systems (FedSeqRecs), in which a public sequential recommender model is shared and frequently transmitted between a central server and clients to achieve collaborative learning. Although these solutions mitigate user privacy to some extent, they present two significant limitations that affect their practical usability: (1) They require a globally shared sequential recommendation model. However, in real-world scenarios, the recommendation model constitutes a critical intellectual property for platform and service providers. Therefore, service providers may be reluctant to disclose their meticulously developed models. (2) The communication costs are high as they correlate with the number of model parameters. This becomes particularly problematic as the current FedSeqRec will be inapplicable when sequential recommendation marches into a large language model era. To overcome the above challenges, this paper proposes a parameter transmission-free federated sequential recommendation framework (PTF-FSR), which ensures both model and data privacy protection to meet the privacy needs of service providers and system users alike. Furthermore, since PTF-FSR only transmits prediction results under privacy protection, which are independent of model sizes, this new federated learning architecture can accommodate more complex and larger sequential recommendation models. Extensive experiments conducted on three widely used recommendation datasets, employing various sequential recommendation models from both ID-based and ID-free paradigms, demonstrate the effectiveness and generalization capability of our proposed framework.
Brain Storm Optimization Based Swarm Learning for Diabetic Retinopathy Image Classification
Apr 24, 2024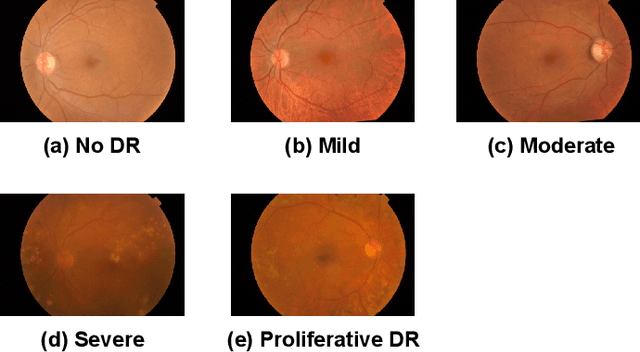
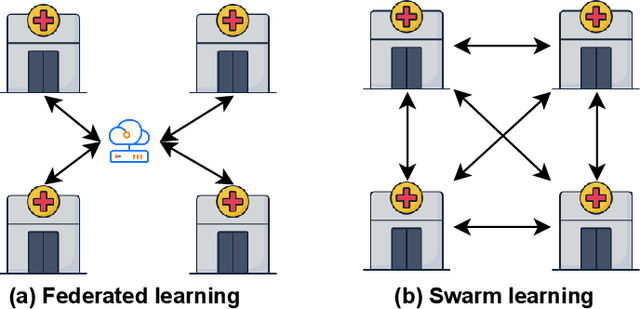
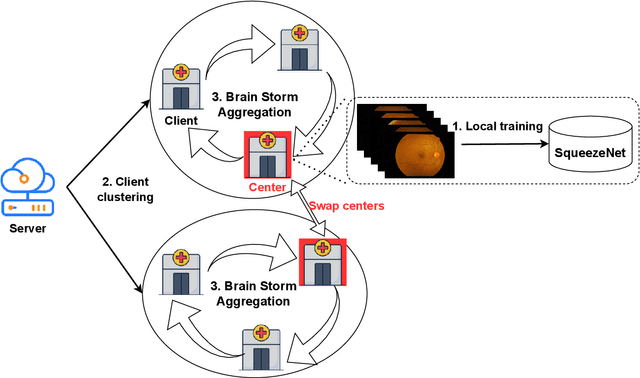
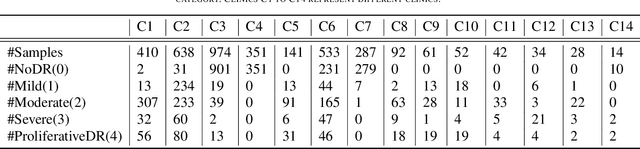
The application of deep learning techniques to medical problems has garnered widespread research interest in recent years, such as applying convolutional neural networks to medical image classification tasks. However, data in the medical field is often highly private, preventing different hospitals from sharing data to train an accurate model. Federated learning, as a privacy-preserving machine learning architecture, has shown promising performance in balancing data privacy and model utility by keeping private data on the client's side and using a central server to coordinate a set of clients for model training through aggregating their uploaded model parameters. Yet, this architecture heavily relies on a trusted third-party server, which is challenging to achieve in real life. Swarm learning, as a specialized decentralized federated learning architecture that does not require a central server, utilizes blockchain technology to enable direct parameter exchanges between clients. However, the mining of blocks requires significant computational resources, limiting its scalability. To address this issue, this paper integrates the brain storm optimization algorithm into the swarm learning framework, named BSO-SL. This approach clusters similar clients into different groups based on their model distributions. Additionally, leveraging the architecture of BSO, clients are given the probability to engage in collaborative learning both within their cluster and with clients outside their cluster, preventing the model from converging to local optima. The proposed method has been validated on a real-world diabetic retinopathy image classification dataset, and the experimental results demonstrate the effectiveness of the proposed approach.
Automated Similarity Metric Generation for Recommendation
Apr 18, 2024



The embedding-based architecture has become the dominant approach in modern recommender systems, mapping users and items into a compact vector space. It then employs predefined similarity metrics, such as the inner product, to calculate similarity scores between user and item embeddings, thereby guiding the recommendation of items that align closely with a user's preferences. Given the critical role of similarity metrics in recommender systems, existing methods mainly employ handcrafted similarity metrics to capture the complex characteristics of user-item interactions. Yet, handcrafted metrics may not fully capture the diverse range of similarity patterns that can significantly vary across different domains. To address this issue, we propose an Automated Similarity Metric Generation method for recommendations, named AutoSMG, which can generate tailored similarity metrics for various domains and datasets. Specifically, we first construct a similarity metric space by sampling from a set of basic embedding operators, which are then integrated into computational graphs to represent metrics. We employ an evolutionary algorithm to search for the optimal metrics within this metric space iteratively. To improve search efficiency, we utilize an early stopping strategy and a surrogate model to approximate the performance of candidate metrics instead of fully training models. Notably, our proposed method is model-agnostic, which can seamlessly plugin into different recommendation model architectures. The proposed method is validated on three public recommendation datasets across various domains in the Top-K recommendation task, and experimental results demonstrate that AutoSMG outperforms both commonly used handcrafted metrics and those generated by other search strategies.