 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDATA-WA: Demand-based Adaptive Task Assignment with Dynamic Worker Availability Windows
Mar 27, 2025With the rapid advancement of mobile networks and the widespread use of mobile devices, spatial crowdsourcing, which involves assigning location-based tasks to mobile workers, has gained significant attention. However, most existing research focuses on task assignment at the current moment, overlooking the fluctuating demand and supply between tasks and workers over time. To address this issue, we introduce an adaptive task assignment problem, which aims to maximize the number of assigned tasks by dynamically adjusting task assignments in response to changing demand and supply. We develop a spatial crowdsourcing framework, namely demand-based adaptive task assignment with dynamic worker availability windows, which consists of two components including task demand prediction and task assignment. In the first component, we construct a graph adjacency matrix representing the demand dependency relationships in different regions and employ a multivariate time series learning approach to predict future task demands. In the task assignment component, we adjust tasks to workers based on these predictions, worker availability windows, and the current task assignments, where each worker has an availability window that indicates the time periods they are available for task assignments. To reduce the search space of task assignments and be efficient, we propose a worker dependency separation approach based on graph partition and a task value function with reinforcement learning. Experiments on real data demonstrate that our proposals are both effective and efficient.
Contrastive Graph Condensation: Advancing Data Versatility through Self-Supervised Learning
Nov 26, 2024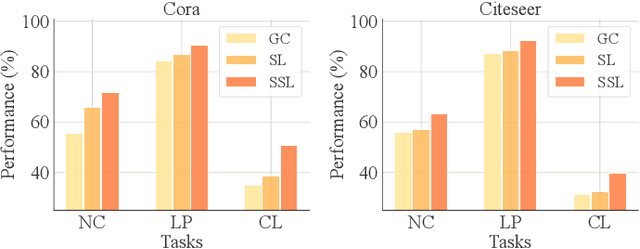
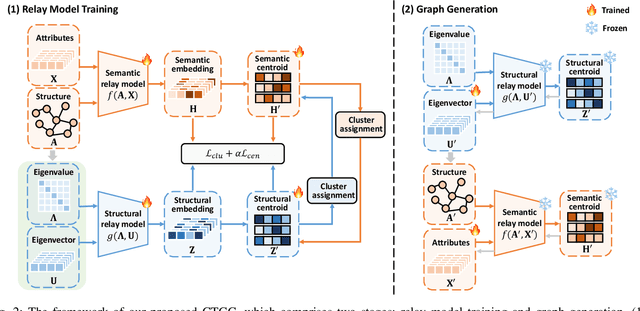
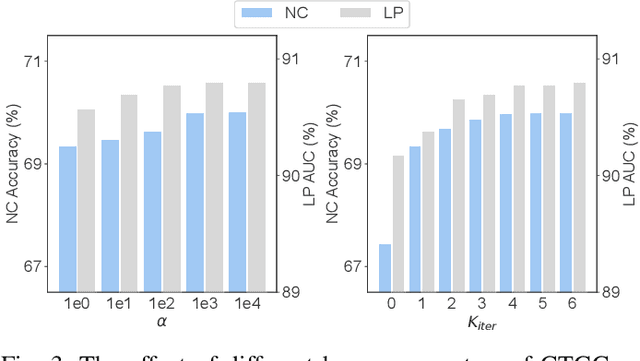
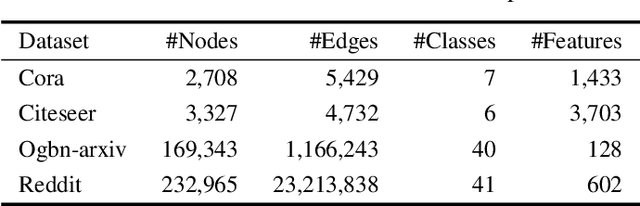
With the increasing computation of training graph neural networks (GNNs) on large-scale graphs, graph condensation (GC) has emerged as a promising solution to synthesize a compact, substitute graph of the large-scale original graph for efficient GNN training. However, existing GC methods predominantly employ classification as the surrogate task for optimization, thus excessively relying on node labels and constraining their utility in label-sparsity scenarios. More critically, this surrogate task tends to overfit class-specific information within the condensed graph, consequently restricting the generalization capabilities of GC for other downstream tasks. To address these challenges, we introduce Contrastive Graph Condensation (CTGC), which adopts a self-supervised surrogate task to extract critical, causal information from the original graph and enhance the cross-task generalizability of the condensed graph. Specifically, CTGC employs a dual-branch framework to disentangle the generation of the node attributes and graph structures, where a dedicated structural branch is designed to explicitly encode geometric information through nodes' positional embeddings. By implementing an alternating optimization scheme with contrastive loss terms, CTGC promotes the mutual enhancement of both branches and facilitates high-quality graph generation through the model inversion technique. Extensive experiments demonstrate that CTGC excels in handling various downstream tasks with a limited number of labels, consistently outperforming state-of-the-art GC methods.
Tackling Data Heterogeneity in Federated Time Series Forecasting
Nov 24, 2024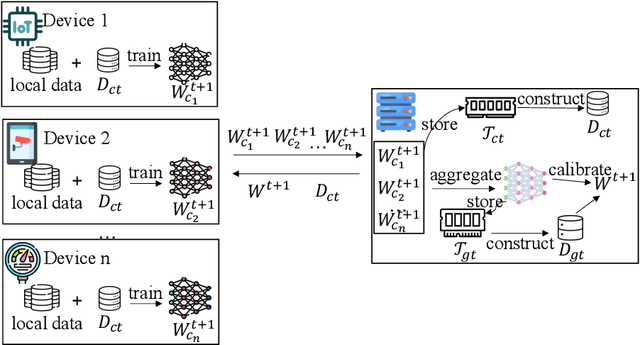
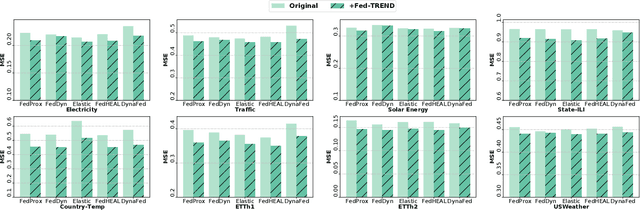
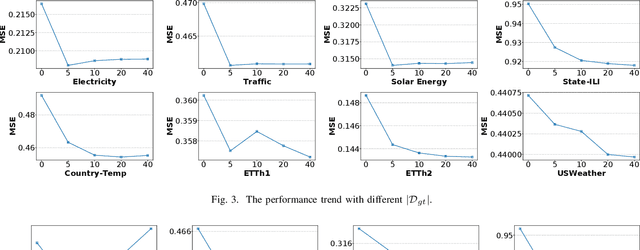
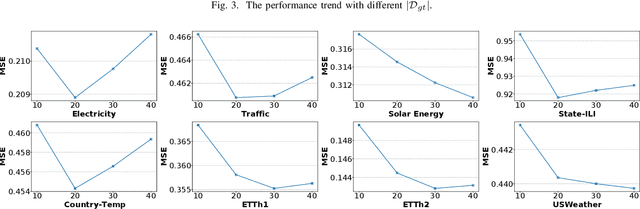
Time series forecasting plays a critical role in various real-world applications, including energy consumption prediction, disease transmission monitoring, and weather forecasting. Although substantial progress has been made in time series forecasting, most existing methods rely on a centralized training paradigm, where large amounts of data are collected from distributed devices (e.g., sensors, wearables) to a central cloud server. However, this paradigm has overloaded communication networks and raised privacy concerns. Federated learning, a popular privacy-preserving technique, enables collaborative model training across distributed data sources. However, directly applying federated learning to time series forecasting often yields suboptimal results, as time series data generated by different devices are inherently heterogeneous. In this paper, we propose a novel framework, Fed-TREND, to address data heterogeneity by generating informative synthetic data as auxiliary knowledge carriers. Specifically, Fed-TREND generates two types of synthetic data. The first type of synthetic data captures the representative distribution information from clients' uploaded model updates and enhances clients' local training consensus. The second kind of synthetic data extracts long-term influence insights from global model update trajectories and is used to refine the global model after aggregation. Fed-TREND is compatible with most time series forecasting models and can be seamlessly integrated into existing federated learning frameworks to improve prediction performance. Extensive experiments on eight datasets, using several federated learning baselines and four popular time series forecasting models, demonstrate the effectiveness and generalizability of Fed-TREND.
On-device Content-based Recommendation with Single-shot Embedding Pruning: A Cooperative Game Perspective
Nov 20, 2024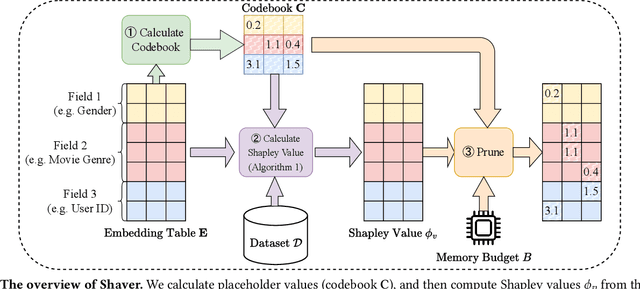
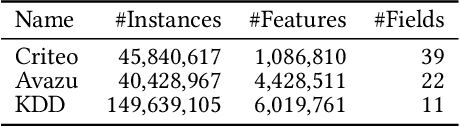
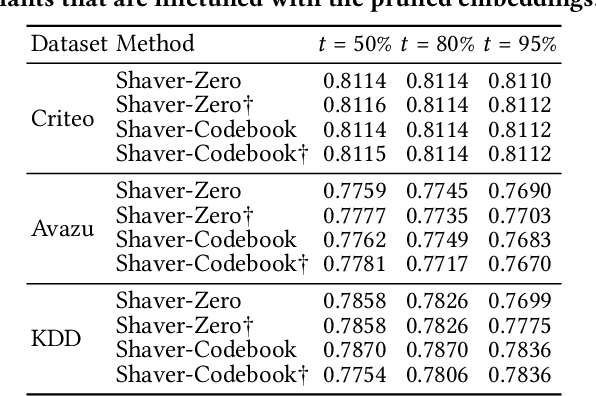
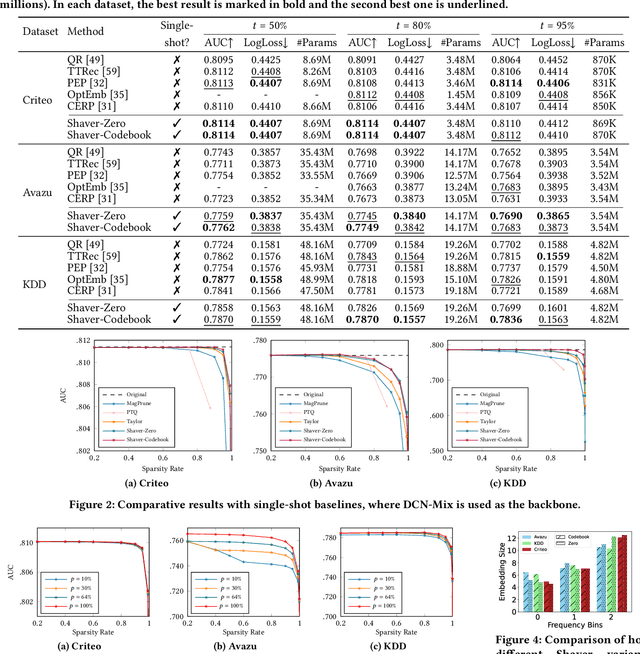
Content-based Recommender Systems (CRSs) play a crucial role in shaping user experiences in e-commerce, online advertising, and personalized recommendations. However, due to the vast amount of categorical features, the embedding tables used in CRS models pose a significant storage bottleneck for real-world deployment, especially on resource-constrained devices. To address this problem, various embedding pruning methods have been proposed, but most existing ones require expensive retraining steps for each target parameter budget, leading to enormous computation costs. In reality, this computation cost is a major hurdle in real-world applications with diverse storage requirements, such as federated learning and streaming settings. In this paper, we propose Shapley Value-guided Embedding Reduction (Shaver) as our response. With Shaver, we view the problem from a cooperative game perspective, and quantify each embedding parameter's contribution with Shapley values to facilitate contribution-based parameter pruning. To address the inherently high computation costs of Shapley values, we propose an efficient and unbiased method to estimate Shapley values of a CRS's embedding parameters. Moreover, in the pruning stage, we put forward a field-aware codebook to mitigate the information loss in the traditional zero-out treatment. Through extensive experiments on three real-world datasets, Shaver has demonstrated competitive performance with lightweight recommendation models across various parameter budgets. The source code is available at https://anonymous.4open.science/r/shaver-E808
Progressive Generalization Risk Reduction for Data-Efficient Causal Effect Estimation
Nov 18, 2024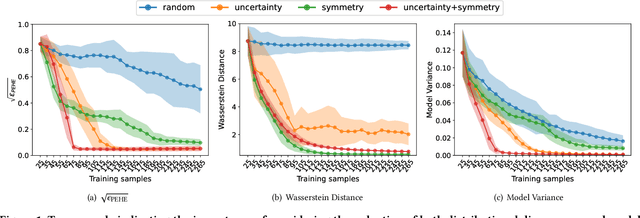
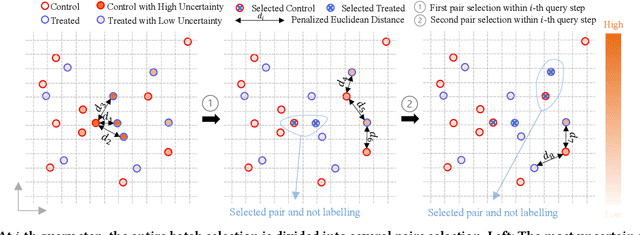

Causal effect estimation (CEE) provides a crucial tool for predicting the unobserved counterfactual outcome for an entity. As CEE relaxes the requirement for ``perfect'' counterfactual samples (e.g., patients with identical attributes and only differ in treatments received) that are impractical to obtain and can instead operate on observational data, it is usually used in high-stake domains like medical treatment effect prediction. Nevertheless, in those high-stake domains, gathering a decently sized, fully labelled observational dataset remains challenging due to hurdles associated with costs, ethics, expertise and time needed, etc., of which medical treatment surveys are a typical example. Consequently, if the training dataset is small in scale, low generalization risks can hardly be achieved on any CEE algorithms. Unlike existing CEE methods that assume the constant availability of a dataset with abundant samples, in this paper, we study a more realistic CEE setting where the labelled data samples are scarce at the beginning, while more can be gradually acquired over the course of training -- assuredly under a limited budget considering their expensive nature. Then, the problem naturally comes down to actively selecting the best possible samples to be labelled, e.g., identifying the next subset of patients to conduct the treatment survey. However, acquiring quality data for reducing the CEE risk under limited labelling budgets remains under-explored until now. To fill the gap, we theoretically analyse the generalization risk from an intriguing perspective of progressively shrinking its upper bound, and develop a principled label acquisition pipeline exclusively for CEE tasks. With our analysis, we propose the Model Agnostic Causal Active Learning (MACAL) algorithm for batch-wise label acquisition, which aims to reduce both the CEE model's uncertainty and the post-acquisition ...
LAC: Graph Contrastive Learning with Learnable Augmentation in Continuous Space
Oct 20, 2024Graph Contrastive Learning frameworks have demonstrated success in generating high-quality node representations. The existing research on efficient data augmentation methods and ideal pretext tasks for graph contrastive learning remains limited, resulting in suboptimal node representation in the unsupervised setting. In this paper, we introduce LAC, a graph contrastive learning framework with learnable data augmentation in an orthogonal continuous space. To capture the representative information in the graph data during augmentation, we introduce a continuous view augmenter, that applies both a masked topology augmentation module and a cross-channel feature augmentation module to adaptively augment the topological information and the feature information within an orthogonal continuous space, respectively. The orthogonal nature of continuous space ensures that the augmentation process avoids dimension collapse. To enhance the effectiveness of pretext tasks, we propose an information-theoretic principle named InfoBal and introduce corresponding pretext tasks. These tasks enable the continuous view augmenter to maintain consistency in the representative information across views while maximizing diversity between views, and allow the encoder to fully utilize the representative information in the unsupervised setting. Our experimental results show that LAC significantly outperforms the state-of-the-art frameworks.
WPFed: Web-based Personalized Federation for Decentralized Systems
Oct 15, 2024



Decentralized learning has become crucial for collaborative model training in environments where data privacy and trust are paramount. In web-based applications, clients are liberated from traditional fixed network topologies, enabling the establishment of arbitrary peer-to-peer (P2P) connections. While this flexibility is highly promising, it introduces a fundamental challenge: the optimal selection of neighbors to ensure effective collaboration. To address this, we introduce WPFed, a fully decentralized, web-based learning framework designed to enable globally optimal neighbor selection. WPFed employs a dynamic communication graph and a weighted neighbor selection mechanism. By assessing inter-client similarity through Locality-Sensitive Hashing (LSH) and evaluating model quality based on peer rankings, WPFed enables clients to identify personalized optimal neighbors on a global scale while preserving data privacy. To enhance security and deter malicious behavior, WPFed integrates verification mechanisms for both LSH codes and performance rankings, leveraging blockchain-driven announcements to ensure transparency and verifiability. Through extensive experiments on multiple real-world datasets, we demonstrate that WPFed significantly improves learning outcomes and system robustness compared to traditional federated learning methods. Our findings highlight WPFed's potential to facilitate effective and secure decentralized collaborative learning across diverse and interconnected web environments.
DecKG: Decentralized Collaborative Learning with Knowledge Graph Enhancement for POI Recommendation
Oct 14, 2024



Decentralized collaborative learning for Point-of-Interest (POI) recommendation has gained research interest due to its advantages in privacy preservation and efficiency, as it keeps data locally and leverages collaborative learning among clients to train models in a decentralized manner. However, since local data is often limited and insufficient for training accurate models, a common solution is integrating external knowledge as auxiliary information to enhance model performance. Nevertheless, this solution poses challenges for decentralized collaborative learning. Due to private nature of local data, identifying relevant auxiliary information specific to each user is non-trivial. Furthermore, resource-constrained local devices struggle to accommodate all auxiliary information, which places heavy burden on local storage. To fill the gap, we propose a novel decentralized collaborative learning with knowledge graph enhancement framework for POI recommendation (DecKG). Instead of directly uploading interacted items, users generate desensitized check-in data by uploading general categories of interacted items and sampling similar items from same category. The server then pretrains KG without sensitive user-item interactions and deploys relevant partitioned sub-KGs to individual users. Entities are further refined on the device, allowing client to client communication to exchange knowledge learned from local data and sub-KGs. Evaluations across two real-world datasets demonstrate DecKG's effectiveness recommendation performance.
FELLAS: Enhancing Federated Sequential Recommendation with LLM as External Services
Oct 07, 2024



Federated sequential recommendation (FedSeqRec) has gained growing attention due to its ability to protect user privacy. Unfortunately, the performance of FedSeqRec is still unsatisfactory because the models used in FedSeqRec have to be lightweight to accommodate communication bandwidth and clients' on-device computational resource constraints. Recently, large language models (LLMs) have exhibited strong transferable and generalized language understanding abilities and therefore, in the NLP area, many downstream tasks now utilize LLMs as a service to achieve superior performance without constructing complex models. Inspired by this successful practice, we propose a generic FedSeqRec framework, FELLAS, which aims to enhance FedSeqRec by utilizing LLMs as an external service. Specifically, FELLAS employs an LLM server to provide both item-level and sequence-level representation assistance. The item-level representation service is queried by the central server to enrich the original ID-based item embedding with textual information, while the sequence-level representation service is accessed by each client. However, invoking the sequence-level representation service requires clients to send sequences to the external LLM server. To safeguard privacy, we implement dx-privacy satisfied sequence perturbation, which protects clients' sensitive data with guarantees. Additionally, a contrastive learning-based method is designed to transfer knowledge from the noisy sequence representation to clients' sequential recommendation models. Furthermore, to empirically validate the privacy protection capability of FELLAS, we propose two interacted item inference attacks. Extensive experiments conducted on three datasets with two widely used sequential recommendation models demonstrate the effectiveness and privacy-preserving capability of FELLAS.
Physics-guided Active Sample Reweighting for Urban Flow Prediction
Jul 18, 2024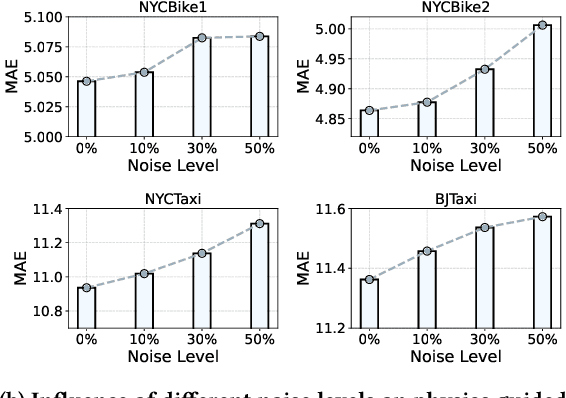

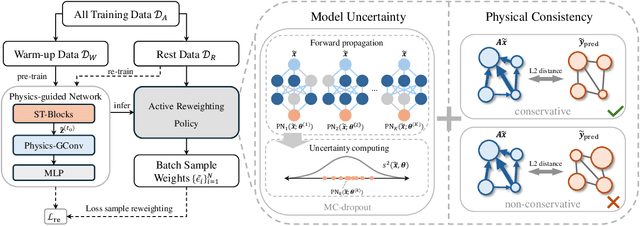

Urban flow prediction is a spatio-temporal modeling task that estimates the throughput of transportation services like buses, taxis, and ride-sharing, where data-driven models have become the most popular solution in the past decade. Meanwhile, the implicitly learned mapping between historical observations to the prediction targets tend to over-simplify the dynamics of real-world urban flows, leading to suboptimal predictions. Some recent spatio-temporal prediction solutions bring remedies with the notion of physics-guided machine learning (PGML), which describes spatio-temporal data with nuanced and principled physics laws, thus enhancing both the prediction accuracy and interpretability. However, these spatio-temporal PGML methods are built upon a strong assumption that the observed data fully conforms to the differential equations that define the physical system, which can quickly become ill-posed in urban flow prediction tasks. The observed urban flow data, especially when sliced into time-dependent snapshots to facilitate predictions, is typically incomplete and sparse, and prone to inherent noise incurred in the collection process. As a result, such physical inconsistency between the data and PGML model significantly limits the predictive power and robustness of the solution. Moreover, due to the interval-based predictions and intermittent nature of data filing in many transportation services, the instantaneous dynamics of urban flows can hardly be captured, rendering differential equation-based continuous modeling a loose fit for this setting. To overcome the challenges, we develop a discretized physics-guided network (PN), and propose a data-aware framework Physics-guided Active Sample Reweighting (P-GASR) to enhance PN. Experimental results in four real-world datasets demonstrate that our method achieves state-of-the-art performance with a demonstrable improvement in robustness.