 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
Mar 27, 2025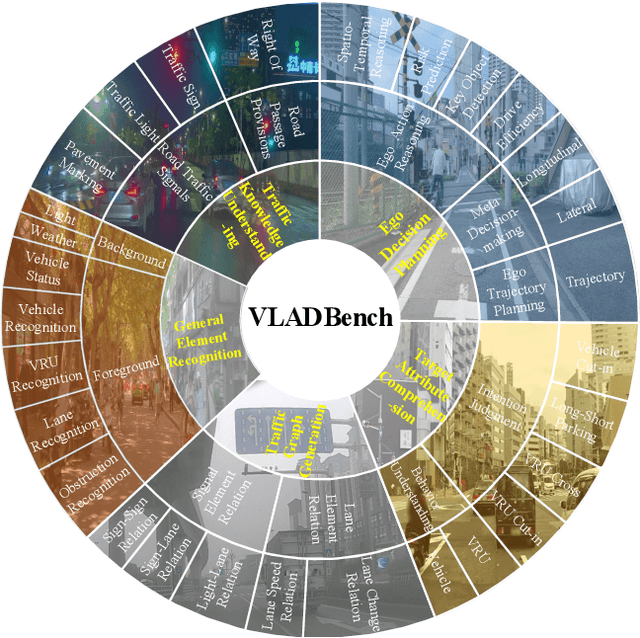

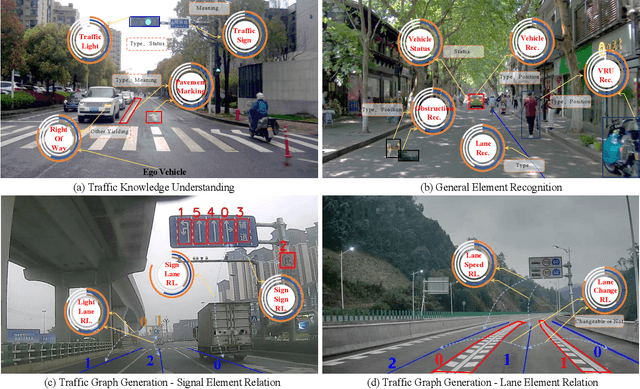

Existing benchmarks for Vision-Language Model (VLM) on autonomous driving (AD) primarily assess interpretability through open-form visual question answering (QA) within coarse-grained tasks, which remain insufficient to assess capabilities in complex driving scenarios. To this end, we introduce $\textbf{VLADBench}$, a challenging and fine-grained dataset featuring close-form QAs that progress from static foundational knowledge and elements to advanced reasoning for dynamic on-road situations. The elaborate $\textbf{VLADBench}$ spans 5 key domains: Traffic Knowledge Understanding, General Element Recognition, Traffic Graph Generation, Target Attribute Comprehension, and Ego Decision-Making and Planning. These domains are further broken down into 11 secondary aspects and 29 tertiary tasks for a granular evaluation. A thorough assessment of general and domain-specific (DS) VLMs on this benchmark reveals both their strengths and critical limitations in AD contexts. To further exploit the cognitive and reasoning interactions among the 5 domains for AD understanding, we start from a small-scale VLM and train the DS models on individual domain datasets (collected from 1.4M DS QAs across public sources). The experimental results demonstrate that the proposed benchmark provides a crucial step toward a more comprehensive assessment of VLMs in AD, paving the way for the development of more cognitively sophisticated and reasoning-capable AD systems.
LAC: Graph Contrastive Learning with Learnable Augmentation in Continuous Space
Oct 20, 2024Graph Contrastive Learning frameworks have demonstrated success in generating high-quality node representations. The existing research on efficient data augmentation methods and ideal pretext tasks for graph contrastive learning remains limited, resulting in suboptimal node representation in the unsupervised setting. In this paper, we introduce LAC, a graph contrastive learning framework with learnable data augmentation in an orthogonal continuous space. To capture the representative information in the graph data during augmentation, we introduce a continuous view augmenter, that applies both a masked topology augmentation module and a cross-channel feature augmentation module to adaptively augment the topological information and the feature information within an orthogonal continuous space, respectively. The orthogonal nature of continuous space ensures that the augmentation process avoids dimension collapse. To enhance the effectiveness of pretext tasks, we propose an information-theoretic principle named InfoBal and introduce corresponding pretext tasks. These tasks enable the continuous view augmenter to maintain consistency in the representative information across views while maximizing diversity between views, and allow the encoder to fully utilize the representative information in the unsupervised setting. Our experimental results show that LAC significantly outperforms the state-of-the-art frameworks.