 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
Mar 27, 2025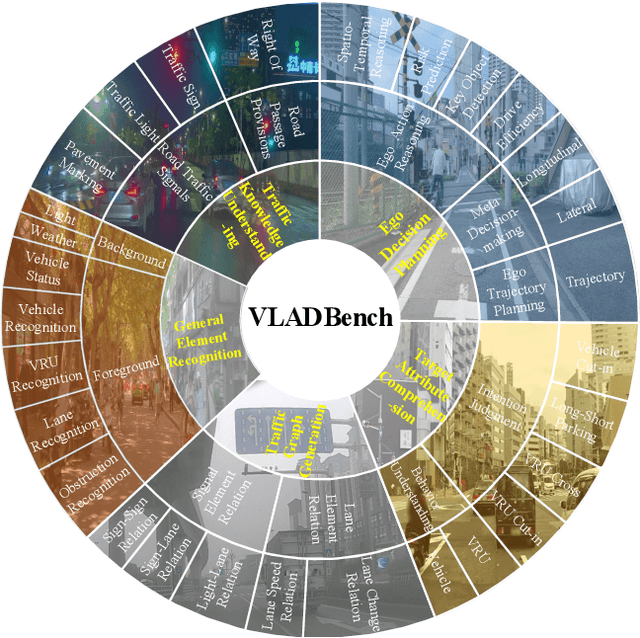

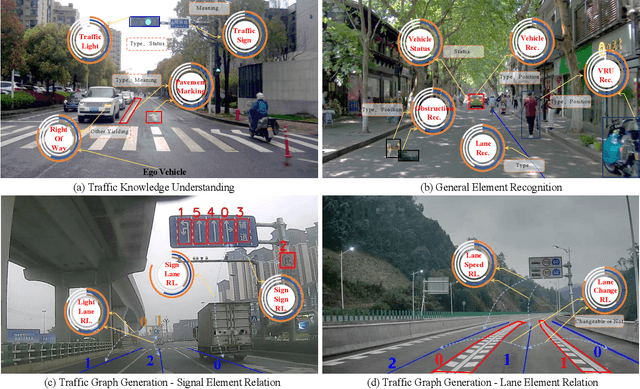

Existing benchmarks for Vision-Language Model (VLM) on autonomous driving (AD) primarily assess interpretability through open-form visual question answering (QA) within coarse-grained tasks, which remain insufficient to assess capabilities in complex driving scenarios. To this end, we introduce $\textbf{VLADBench}$, a challenging and fine-grained dataset featuring close-form QAs that progress from static foundational knowledge and elements to advanced reasoning for dynamic on-road situations. The elaborate $\textbf{VLADBench}$ spans 5 key domains: Traffic Knowledge Understanding, General Element Recognition, Traffic Graph Generation, Target Attribute Comprehension, and Ego Decision-Making and Planning. These domains are further broken down into 11 secondary aspects and 29 tertiary tasks for a granular evaluation. A thorough assessment of general and domain-specific (DS) VLMs on this benchmark reveals both their strengths and critical limitations in AD contexts. To further exploit the cognitive and reasoning interactions among the 5 domains for AD understanding, we start from a small-scale VLM and train the DS models on individual domain datasets (collected from 1.4M DS QAs across public sources). The experimental results demonstrate that the proposed benchmark provides a crucial step toward a more comprehensive assessment of VLMs in AD, paving the way for the development of more cognitively sophisticated and reasoning-capable AD systems.
IC-Mapper: Instance-Centric Spatio-Temporal Modeling for Online Vectorized Map Construction
Mar 05, 2025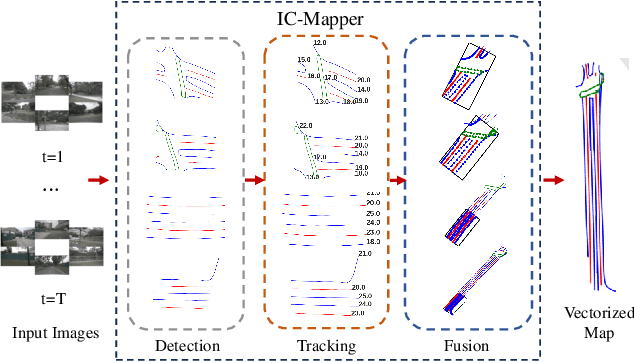
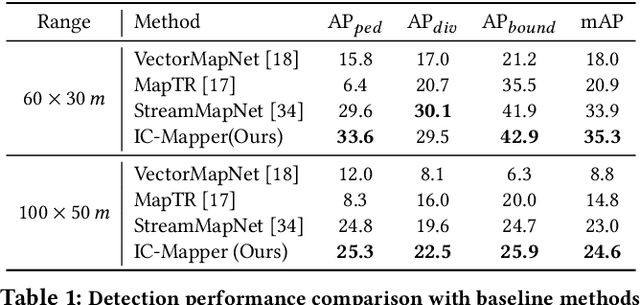

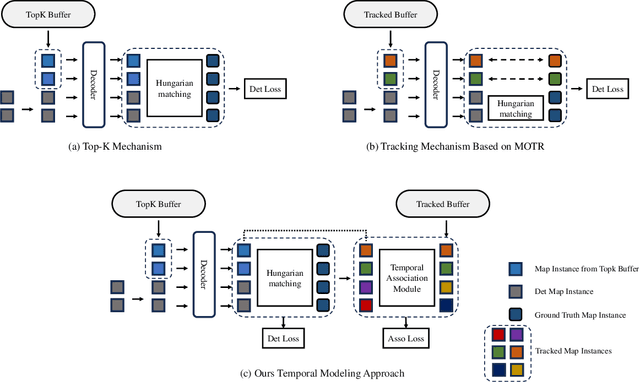
Online vector map construction based on visual data can bypass the processes of data collection, post-processing, and manual annotation required by traditional map construction, which significantly enhances map-building efficiency. However, existing work treats the online mapping task as a local range perception task, overlooking the spatial scalability required for map construction. We propose IC-Mapper, an instance-centric online mapping framework, which comprises two primary components: 1) Instance-centric temporal association module: For the detection queries of adjacent frames, we measure them in both feature and geometric dimensions to obtain the matching correspondence between instances across frames. 2) Instance-centric spatial fusion module: We perform point sampling on the historical global map from a spatial dimension and integrate it with the detection results of instances corresponding to the current frame to achieve real-time expansion and update of the map. Based on the nuScenes dataset, we evaluate our approach on detection, tracking, and global mapping metrics. Experimental results demonstrate the superiority of IC-Mapper against other state-of-the-art methods. Code will be released on https://github.com/Brickzhuantou/IC-Mapper.