 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
SkinFlow: Efficient Information Transmission for Open Dermatological Diagnosis via Dynamic Visual Encoding and Staged RL
Jan 14, 2026General-purpose Large Vision-Language Models (LVLMs), despite their massive scale, often falter in dermatology due to "diffuse attention" - the inability to disentangle subtle pathological lesions from background noise. In this paper, we challenge the assumption that parameter scaling is the only path to medical precision. We introduce SkinFlow, a framework that treats diagnosis as an optimization of visual information transmission efficiency. Our approach utilizes a Virtual-Width Dynamic Vision Encoder (DVE) to "unfold" complex pathological manifolds without physical parameter expansion, coupled with a two-stage Reinforcement Learning strategy. This strategy sequentially aligns explicit medical descriptions (Stage I) and reconstructs implicit diagnostic textures (Stage II) within a constrained semantic space. Furthermore, we propose a clinically grounded evaluation protocol that prioritizes diagnostic safety and hierarchical relevance over rigid label matching. Empirical results are compelling: our 7B model establishes a new state-of-the-art on the Fitzpatrick17k benchmark, achieving a +12.06% gain in Top-1 accuracy and a +28.57% boost in Top-6 accuracy over the massive general-purpose models (e.g., Qwen3VL-235B and GPT-5.2). These findings demonstrate that optimizing geometric capacity and information flow yields superior diagnostic reasoning compared to raw parameter scaling.
Fine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
Mar 27, 2025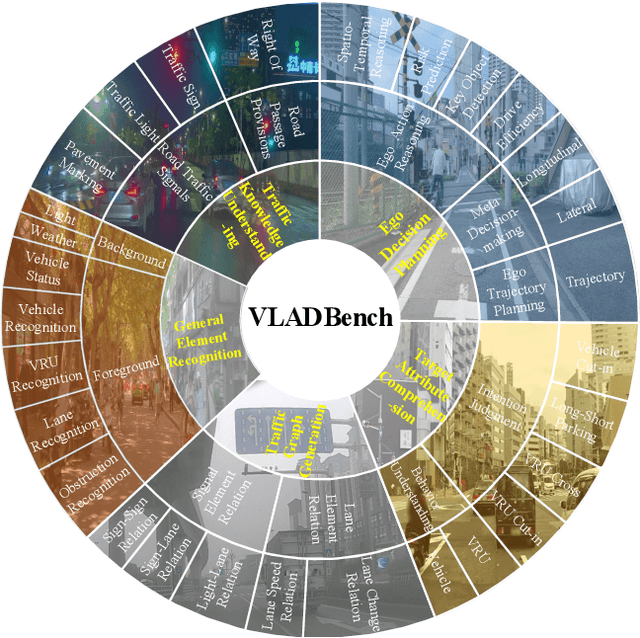

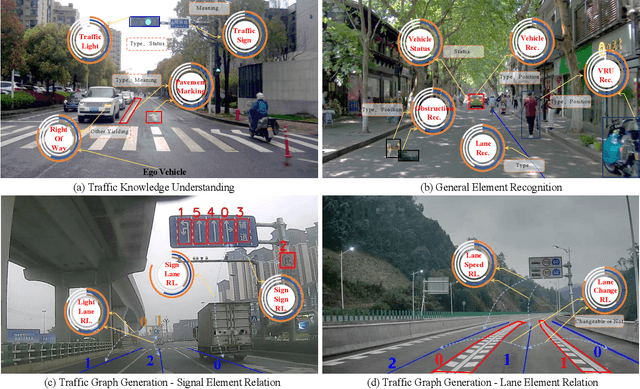

Existing benchmarks for Vision-Language Model (VLM) on autonomous driving (AD) primarily assess interpretability through open-form visual question answering (QA) within coarse-grained tasks, which remain insufficient to assess capabilities in complex driving scenarios. To this end, we introduce $\textbf{VLADBench}$, a challenging and fine-grained dataset featuring close-form QAs that progress from static foundational knowledge and elements to advanced reasoning for dynamic on-road situations. The elaborate $\textbf{VLADBench}$ spans 5 key domains: Traffic Knowledge Understanding, General Element Recognition, Traffic Graph Generation, Target Attribute Comprehension, and Ego Decision-Making and Planning. These domains are further broken down into 11 secondary aspects and 29 tertiary tasks for a granular evaluation. A thorough assessment of general and domain-specific (DS) VLMs on this benchmark reveals both their strengths and critical limitations in AD contexts. To further exploit the cognitive and reasoning interactions among the 5 domains for AD understanding, we start from a small-scale VLM and train the DS models on individual domain datasets (collected from 1.4M DS QAs across public sources). The experimental results demonstrate that the proposed benchmark provides a crucial step toward a more comprehensive assessment of VLMs in AD, paving the way for the development of more cognitively sophisticated and reasoning-capable AD systems.
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
Apr 16, 2024



Large Vision-Language Models (LVLMs), due to the remarkable visual reasoning ability to understand images and videos, have received widespread attention in the autonomous driving domain, which significantly advances the development of interpretable end-to-end autonomous driving. However, current evaluations of LVLMs primarily focus on the multi-faceted capabilities in common scenarios, lacking quantifiable and automated assessment in autonomous driving contexts, let alone severe road corner cases that even the state-of-the-art autonomous driving perception systems struggle to handle. In this paper, we propose CODA-LM, a novel vision-language benchmark for self-driving, which provides the first automatic and quantitative evaluation of LVLMs for interpretable autonomous driving including general perception, regional perception, and driving suggestions. CODA-LM utilizes the texts to describe the road images, exploiting powerful text-only large language models (LLMs) without image inputs to assess the capabilities of LVLMs in autonomous driving scenarios, which reveals stronger alignment with human preferences than LVLM judges. Experiments demonstrate that even the closed-sourced commercial LVLMs like GPT-4V cannot deal with road corner cases well, suggesting that we are still far from a strong LVLM-powered intelligent driving agent, and we hope our CODA-LM can become the catalyst to promote future development.
Knowledge Augmented Relation Inference for Group Activity Recognition
Mar 01, 2023



Most existing group activity recognition methods construct spatial-temporal relations merely based on visual representation. Some methods introduce extra knowledge, such as action labels, to build semantic relations and use them to refine the visual presentation. However, the knowledge they explored just stay at the semantic-level, which is insufficient for pursing notable accuracy. In this paper, we propose to exploit knowledge concretization for the group activity recognition, and develop a novel Knowledge Augmented Relation Inference framework that can effectively use the concretized knowledge to improve the individual representations. Specifically, the framework consists of a Visual Representation Module to extract individual appearance features, a Knowledge Augmented Semantic Relation Module explore semantic representations of individual actions, and a Knowledge-Semantic-Visual Interaction Module aims to integrate visual and semantic information by the knowledge. Benefiting from these modules, the proposed framework can utilize knowledge to enhance the relation inference process and the individual representations, thus improving the performance of group activity recognition. Experimental results on two public datasets show that the proposed framework achieves competitive performance compared with state-of-the-art methods.
Weakly Supervised Learning of Keypoints for 6D Object Pose Estimation
Mar 07, 2022

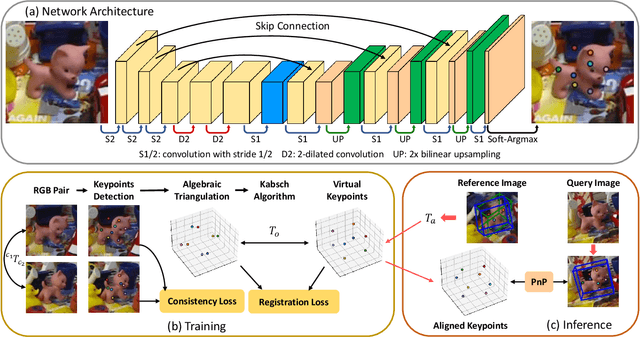

State-of-the-art approaches for 6D object pose estimation require large amounts of labeled data to train the deep networks. However, the acquisition of 6D object pose annotations is tedious and labor-intensive in large quantity. To alleviate this problem, we propose a weakly supervised 6D object pose estimation approach based on 2D keypoint detection. Our method trains only on image pairs with known relative transformations between their viewpoints. Specifically, we assign a set of arbitrarily chosen 3D keypoints to represent each unknown target 3D object and learn a network to detect their 2D projections that comply with the relative camera viewpoints. During inference, our network first infers the 2D keypoints from the query image and a given labeled reference image. We then use these 2D keypoints and the arbitrarily chosen 3D keypoints retained from training to infer the 6D object pose. Extensive experiments demonstrate that our approach achieves comparable performance with state-of-the-art fully supervised approaches.
Blindly Assess Quality of In-the-Wild Videos via Quality-aware Pre-training and Motion Perception
Aug 19, 2021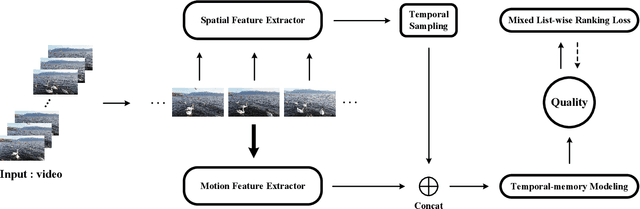

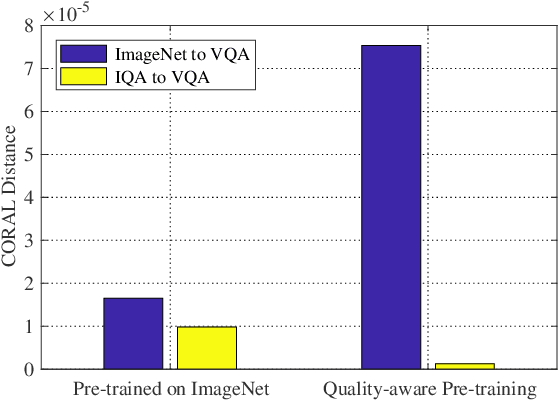

Perceptual quality assessment of the videos acquired in the wilds is of vital importance for quality assurance of video services. The inaccessibility of reference videos with pristine quality and the complexity of authentic distortions pose great challenges for this kind of blind video quality assessment (BVQA) task. Although model-based transfer learning is an effective and efficient paradigm for the BVQA task, it remains to be a challenge to explore what and how to bridge the domain shifts for better video representation. In this work, we propose to transfer knowledge from image quality assessment (IQA) databases with authentic distortions and large-scale action recognition with rich motion patterns. We rely on both groups of data to learn the feature extractor. We train the proposed model on the target VQA databases using a mixed list-wise ranking loss function. Extensive experiments on six databases demonstrate that our method performs very competitively under both individual database and mixed database training settings. We also verify the rationality of each component of the proposed method and explore a simple manner for further improvement.
DeepOpht: Medical Report Generation for Retinal Images via Deep Models and Visual Explanation
Nov 01, 2020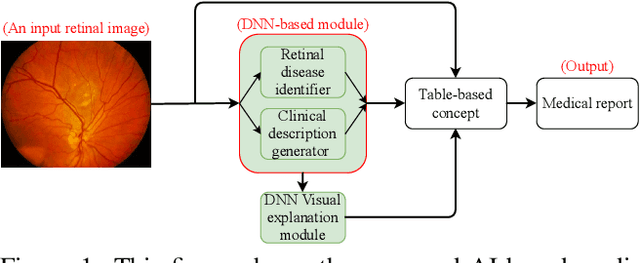
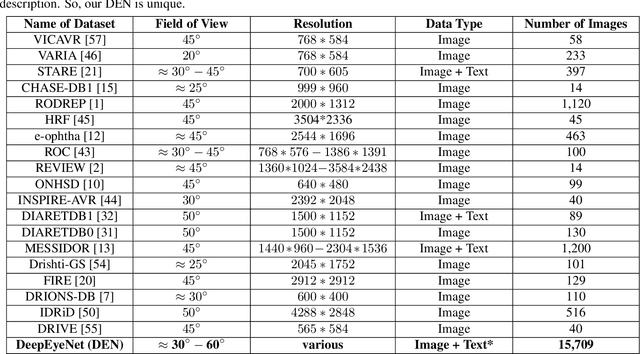
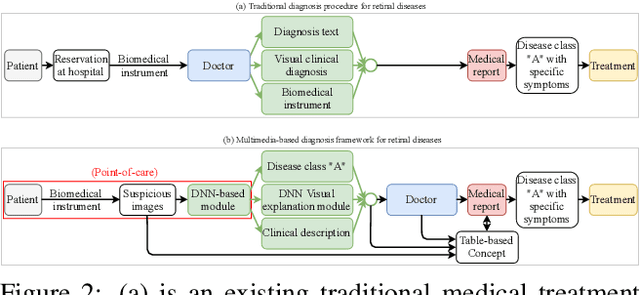
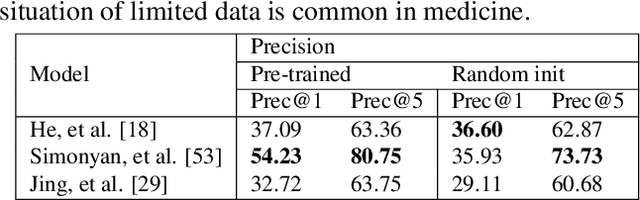
In this work, we propose an AI-based method that intends to improve the conventional retinal disease treatment procedure and help ophthalmologists increase diagnosis efficiency and accuracy. The proposed method is composed of a deep neural networks-based (DNN-based) module, including a retinal disease identifier and clinical description generator, and a DNN visual explanation module. To train and validate the effectiveness of our DNN-based module, we propose a large-scale retinal disease image dataset. Also, as ground truth, we provide a retinal image dataset manually labeled by ophthalmologists to qualitatively show, the proposed AI-based method is effective. With our experimental results, we show that the proposed method is quantitatively and qualitatively effective. Our method is capable of creating meaningful retinal image descriptions and visual explanations that are clinically relevant.
Shape Prior Deformation for Categorical 6D Object Pose and Size Estimation
Jul 16, 2020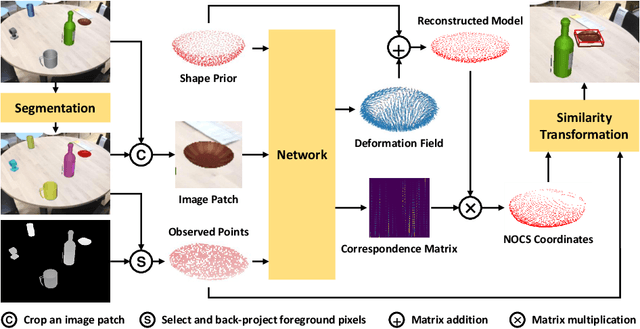
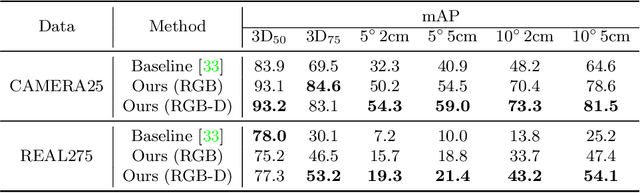


We present a novel learning approach to recover the 6D poses and sizes of unseen object instances from an RGB-D image. To handle the intra-class shape variation, we propose a deep network to reconstruct the 3D object model by explicitly modeling the deformation from a pre-learned categorical shape prior. Additionally, our network infers the dense correspondences between the depth observation of the object instance and the reconstructed 3D model to jointly estimate the 6D object pose and size. We design an autoencoder that trains on a collection of object models and compute the mean latent embedding for each category to learn the categorical shape priors. Extensive experiments on both synthetic and real-world datasets demonstrate that our approach significantly outperforms the state of the art. Our code is available at https://github.com/mentian/object-deformnet.
Robust 6D Object Pose Estimation by Learning RGB-D Features
Mar 09, 2020

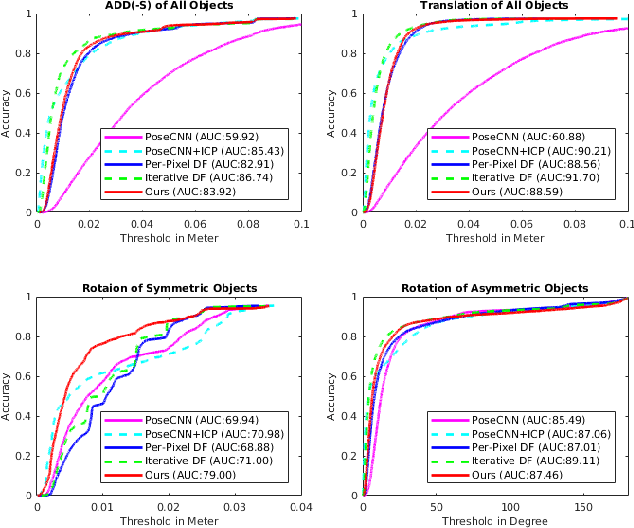
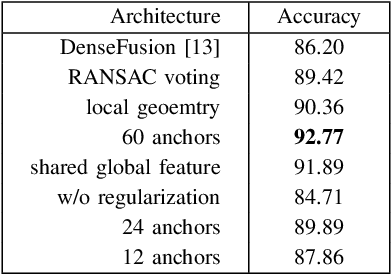
Accurate 6D object pose estimation is fundamental to robotic manipulation and grasping. Previous methods follow a local optimization approach which minimizes the distance between closest point pairs to handle the rotation ambiguity of symmetric objects. In this work, we propose a novel discrete-continuous formulation for rotation regression to resolve this local-optimum problem. We uniformly sample rotation anchors in SO(3), and predict a constrained deviation from each anchor to the target, as well as uncertainty scores for selecting the best prediction. Additionally, the object location is detected by aggregating point-wise vectors pointing to the 3D center. Experiments on two benchmarks: LINEMOD and YCB-Video, show that the proposed method outperforms state-of-the-art approaches. Our code is available at https://github.com/mentian/object-posenet.