 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Evaluation of Large Vision-Language Models in Autonomous Driving
Mar 27, 2025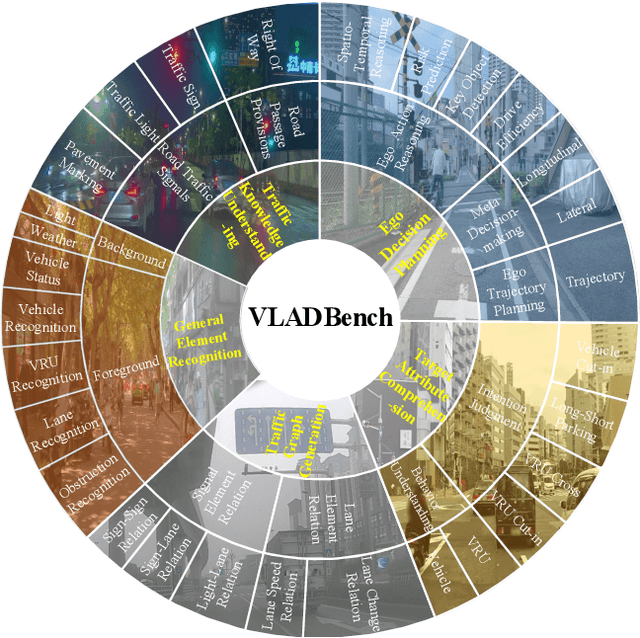

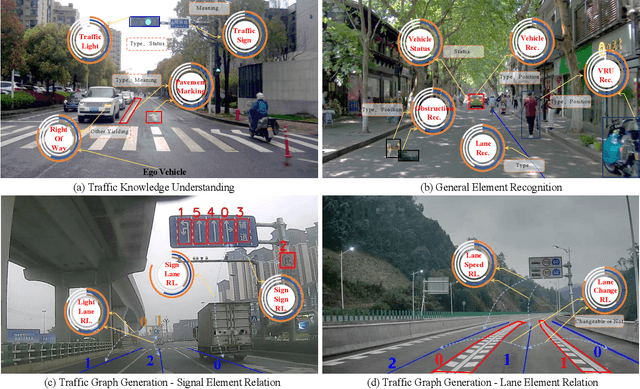

Existing benchmarks for Vision-Language Model (VLM) on autonomous driving (AD) primarily assess interpretability through open-form visual question answering (QA) within coarse-grained tasks, which remain insufficient to assess capabilities in complex driving scenarios. To this end, we introduce $\textbf{VLADBench}$, a challenging and fine-grained dataset featuring close-form QAs that progress from static foundational knowledge and elements to advanced reasoning for dynamic on-road situations. The elaborate $\textbf{VLADBench}$ spans 5 key domains: Traffic Knowledge Understanding, General Element Recognition, Traffic Graph Generation, Target Attribute Comprehension, and Ego Decision-Making and Planning. These domains are further broken down into 11 secondary aspects and 29 tertiary tasks for a granular evaluation. A thorough assessment of general and domain-specific (DS) VLMs on this benchmark reveals both their strengths and critical limitations in AD contexts. To further exploit the cognitive and reasoning interactions among the 5 domains for AD understanding, we start from a small-scale VLM and train the DS models on individual domain datasets (collected from 1.4M DS QAs across public sources). The experimental results demonstrate that the proposed benchmark provides a crucial step toward a more comprehensive assessment of VLMs in AD, paving the way for the development of more cognitively sophisticated and reasoning-capable AD systems.
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
Apr 16, 2024



Large Vision-Language Models (LVLMs), due to the remarkable visual reasoning ability to understand images and videos, have received widespread attention in the autonomous driving domain, which significantly advances the development of interpretable end-to-end autonomous driving. However, current evaluations of LVLMs primarily focus on the multi-faceted capabilities in common scenarios, lacking quantifiable and automated assessment in autonomous driving contexts, let alone severe road corner cases that even the state-of-the-art autonomous driving perception systems struggle to handle. In this paper, we propose CODA-LM, a novel vision-language benchmark for self-driving, which provides the first automatic and quantitative evaluation of LVLMs for interpretable autonomous driving including general perception, regional perception, and driving suggestions. CODA-LM utilizes the texts to describe the road images, exploiting powerful text-only large language models (LLMs) without image inputs to assess the capabilities of LVLMs in autonomous driving scenarios, which reveals stronger alignment with human preferences than LVLM judges. Experiments demonstrate that even the closed-sourced commercial LVLMs like GPT-4V cannot deal with road corner cases well, suggesting that we are still far from a strong LVLM-powered intelligent driving agent, and we hope our CODA-LM can become the catalyst to promote future development.
HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird's Eye View
Jul 25, 2023Vision-based Bird's Eye View (BEV) representation is an emerging perception formulation for autonomous driving. The core challenge is to construct BEV space with multi-camera features, which is a one-to-many ill-posed problem. Diving into all previous BEV representation generation methods, we found that most of them fall into two types: modeling depths in image views or modeling heights in the BEV space, mostly in an implicit way. In this work, we propose to explicitly model heights in the BEV space, which needs no extra data like LiDAR and can fit arbitrary camera rigs and types compared to modeling depths. Theoretically, we give proof of the equivalence between height-based methods and depth-based methods. Considering the equivalence and some advantages of modeling heights, we propose HeightFormer, which models heights and uncertainties in a self-recursive way. Without any extra data, the proposed HeightFormer could estimate heights in BEV accurately. Benchmark results show that the performance of HeightFormer achieves SOTA compared with those camera-only methods.
Towards Domain Generalization for Multi-view 3D Object Detection in Bird-Eye-View
Mar 03, 2023
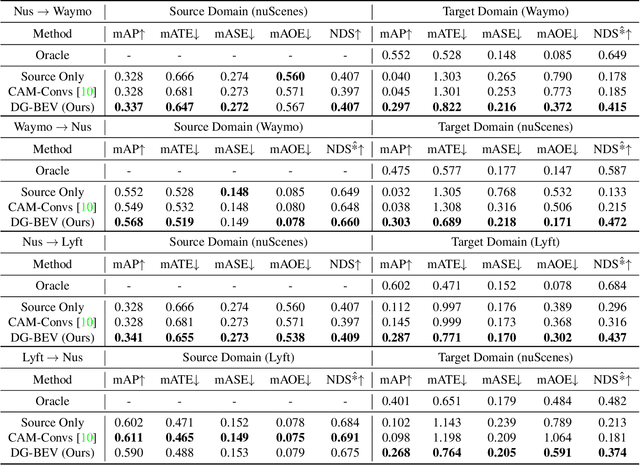
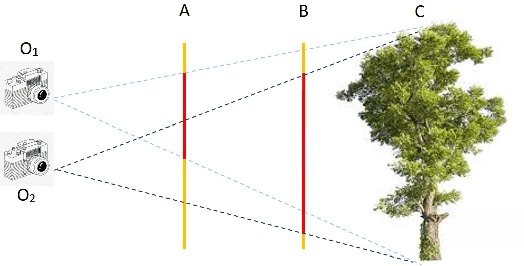
Multi-view 3D object detection (MV3D-Det) in Bird-Eye-View (BEV) has drawn extensive attention due to its low cost and high efficiency. Although new algorithms for camera-only 3D object detection have been continuously proposed, most of them may risk drastic performance degradation when the domain of input images differs from that of training. In this paper, we first analyze the causes of the domain gap for the MV3D-Det task. Based on the covariate shift assumption, we find that the gap mainly attributes to the feature distribution of BEV, which is determined by the quality of both depth estimation and 2D image's feature representation. To acquire a robust depth prediction, we propose to decouple the depth estimation from the intrinsic parameters of the camera (i.e. the focal length) through converting the prediction of metric depth to that of scale-invariant depth and perform dynamic perspective augmentation to increase the diversity of the extrinsic parameters (i.e. the camera poses) by utilizing homography. Moreover, we modify the focal length values to create multiple pseudo-domains and construct an adversarial training loss to encourage the feature representation to be more domain-agnostic. Without bells and whistles, our approach, namely DG-BEV, successfully alleviates the performance drop on the unseen target domain without impairing the accuracy of the source domain. Extensive experiments on various public datasets, including Waymo, nuScenes, and Lyft, demonstrate the generalization and effectiveness of our approach. To the best of our knowledge, this is the first systematic study to explore a domain generalization method for MV3D-Det.
Fast Hypergraph Regularized Nonnegative Tensor Ring Factorization Based on Low-Rank Approximation
Sep 06, 2021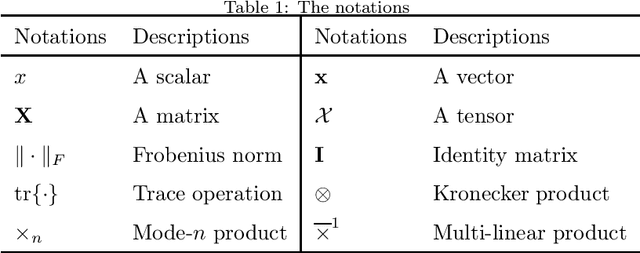
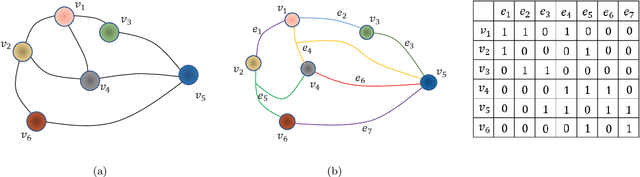
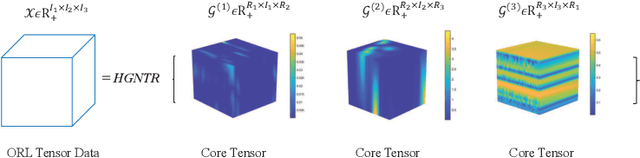
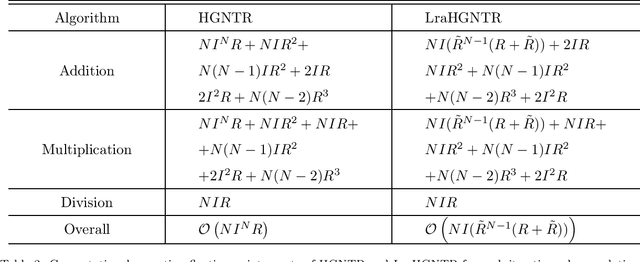
For the high dimensional data representation, nonnegative tensor ring (NTR) decomposition equipped with manifold learning has become a promising model to exploit the multi-dimensional structure and extract the feature from tensor data. However, the existing methods such as graph regularized tensor ring decomposition (GNTR) only models the pair-wise similarities of objects. For tensor data with complex manifold structure, the graph can not exactly construct similarity relationships. In this paper, in order to effectively utilize the higher-dimensional and complicated similarities among objects, we introduce hypergraph to the framework of NTR to further enhance the feature extraction, upon which a hypergraph regularized nonnegative tensor ring decomposition (HGNTR) method is developed. To reduce the computational complexity and suppress the noise, we apply the low-rank approximation trick to accelerate HGNTR (called LraHGNTR). Our experimental results show that compared with other state-of-the-art algorithms, the proposed HGNTR and LraHGNTR can achieve higher performance in clustering tasks, in addition, LraHGNTR can greatly reduce running time without decreasing accuracy.