 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiCrafter: High-Fidelity Multi-Subject Generation via Spatially Disentangled Attention and Identity-Aware Reinforcement Learning
Sep 26, 2025Multi-subject image generation aims to synthesize user-provided subjects in a single image while preserving subject fidelity, ensuring prompt consistency, and aligning with human aesthetic preferences. However, existing methods, particularly those built on the In-Context-Learning paradigm, are limited by their reliance on simple reconstruction-based objectives, leading to both severe attribute leakage that compromises subject fidelity and failing to align with nuanced human preferences. To address this, we propose MultiCrafter, a framework that ensures high-fidelity, preference-aligned generation. First, we find that the root cause of attribute leakage is a significant entanglement of attention between different subjects during the generation process. Therefore, we introduce explicit positional supervision to explicitly separate attention regions for each subject, effectively mitigating attribute leakage. To enable the model to accurately plan the attention region of different subjects in diverse scenarios, we employ a Mixture-of-Experts architecture to enhance the model's capacity, allowing different experts to focus on different scenarios. Finally, we design a novel online reinforcement learning framework to align the model with human preferences, featuring a scoring mechanism to accurately assess multi-subject fidelity and a more stable training strategy tailored for the MoE architecture. Experiments validate that our framework significantly improves subject fidelity while aligning with human preferences better.
HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird's Eye View
Jul 25, 2023Vision-based Bird's Eye View (BEV) representation is an emerging perception formulation for autonomous driving. The core challenge is to construct BEV space with multi-camera features, which is a one-to-many ill-posed problem. Diving into all previous BEV representation generation methods, we found that most of them fall into two types: modeling depths in image views or modeling heights in the BEV space, mostly in an implicit way. In this work, we propose to explicitly model heights in the BEV space, which needs no extra data like LiDAR and can fit arbitrary camera rigs and types compared to modeling depths. Theoretically, we give proof of the equivalence between height-based methods and depth-based methods. Considering the equivalence and some advantages of modeling heights, we propose HeightFormer, which models heights and uncertainties in a self-recursive way. Without any extra data, the proposed HeightFormer could estimate heights in BEV accurately. Benchmark results show that the performance of HeightFormer achieves SOTA compared with those camera-only methods.
GaitMPL: Gait Recognition with Memory-Augmented Progressive Learning
Jun 06, 2023Gait recognition aims at identifying the pedestrians at a long distance by their biometric gait patterns. It is inherently challenging due to the various covariates and the properties of silhouettes (textureless and colorless), which result in two kinds of pair-wise hard samples: the same pedestrian could have distinct silhouettes (intra-class diversity) and different pedestrians could have similar silhouettes (inter-class similarity). In this work, we propose to solve the hard sample issue with a Memory-augmented Progressive Learning network (GaitMPL), including Dynamic Reweighting Progressive Learning module (DRPL) and Global Structure-Aligned Memory bank (GSAM). Specifically, DRPL reduces the learning difficulty of hard samples by easy-to-hard progressive learning. GSAM further augments DRPL with a structure-aligned memory mechanism, which maintains and models the feature distribution of each ID. Experiments on two commonly used datasets, CASIA-B and OU-MVLP, demonstrate the effectiveness of GaitMPL. On CASIA-B, we achieve the state-of-the-art performance, i.e., 88.0% on the most challenging condition (Clothing) and 93.3% on the average condition, which outperforms the other methods by at least 3.8% and 1.4%, respectively.
UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird's-Eye-View
Jul 18, 2022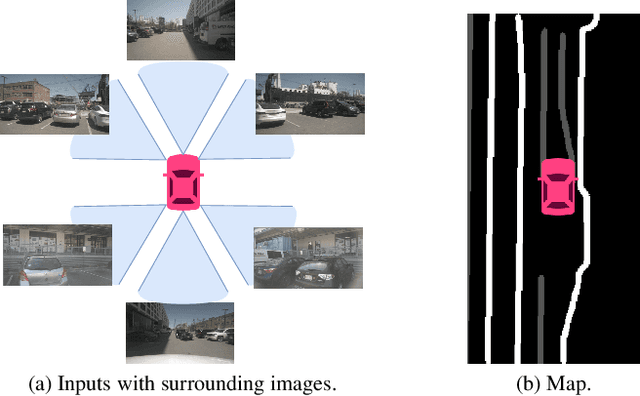

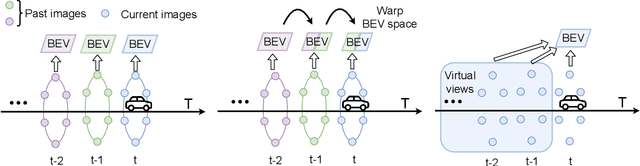
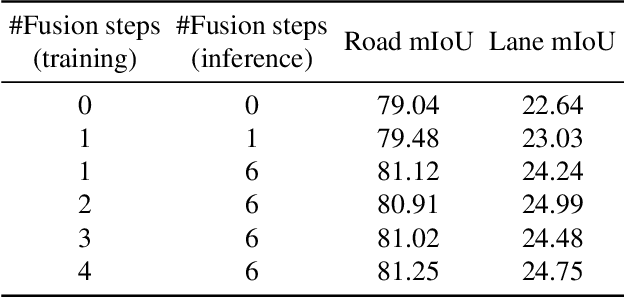
Bird's eye view (BEV) representation is a new perception formulation for autonomous driving, which is based on spatial fusion. Further, temporal fusion is also introduced in BEV representation and gains great success. In this work, we propose a new method that unifies both spatial and temporal fusion and merges them into a unified mathematical formulation. The unified fusion could not only provide a new perspective on BEV fusion but also brings new capabilities. With the proposed unified spatial-temporal fusion, our method could support long-range fusion, which is hard to achieve in conventional BEV methods. Moreover, the BEV fusion in our work is temporal-adaptive, and the weights of temporal fusion are learnable. In contrast, conventional methods mainly use fixed and equal weights for temporal fusion. Besides, the proposed unified fusion could avoid information lost in conventional BEV fusion methods and make full use of features. Extensive experiments and ablation studies on the NuScenes dataset show the effectiveness of the proposed method and our method gains the state-of-the-art performance in the map segmentation task.
Ultra Fast Deep Lane Detection with Hybrid Anchor Driven Ordinal Classification
Jun 15, 2022
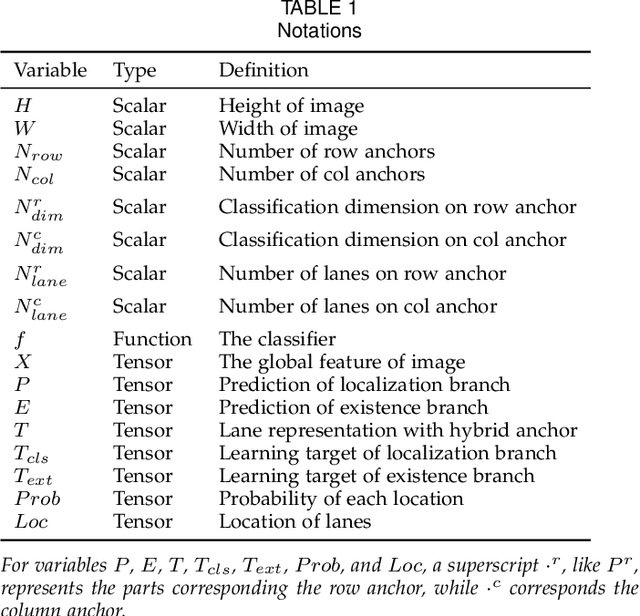
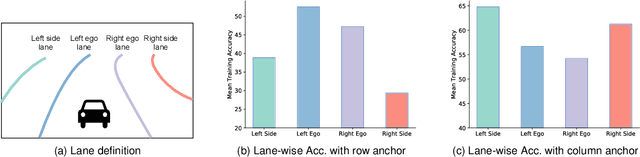

Modern methods mainly regard lane detection as a problem of pixel-wise segmentation, which is struggling to address the problems of efficiency and challenging scenarios like severe occlusions and extreme lighting conditions. Inspired by human perception, the recognition of lanes under severe occlusions and extreme lighting conditions is mainly based on contextual and global information. Motivated by this observation, we propose a novel, simple, yet effective formulation aiming at ultra fast speed and the problem of challenging scenarios. Specifically, we treat the process of lane detection as an anchor-driven ordinal classification problem using global features. First, we represent lanes with sparse coordinates on a series of hybrid (row and column) anchors. With the help of the anchor-driven representation, we then reformulate the lane detection task as an ordinal classification problem to get the coordinates of lanes. Our method could significantly reduce the computational cost with the anchor-driven representation. Using the large receptive field property of the ordinal classification formulation, we could also handle challenging scenarios. Extensive experiments on four lane detection datasets show that our method could achieve state-of-the-art performance in terms of both speed and accuracy. A lightweight version could even achieve 300+ frames per second(FPS). Our code is at https://github.com/cfzd/Ultra-Fast-Lane-Detection-v2.
MonoGround: Detecting Monocular 3D Objects from the Ground
Jun 15, 2022
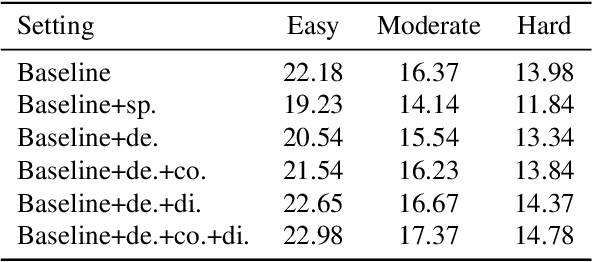

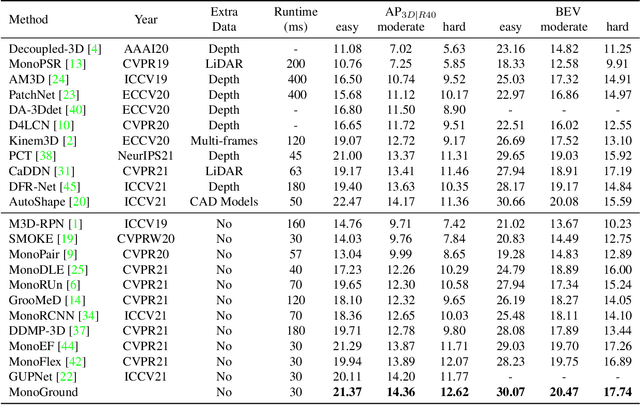
Monocular 3D object detection has attracted great attention for its advantages in simplicity and cost. Due to the ill-posed 2D to 3D mapping essence from the monocular imaging process, monocular 3D object detection suffers from inaccurate depth estimation and thus has poor 3D detection results. To alleviate this problem, we propose to introduce the ground plane as a prior in the monocular 3d object detection. The ground plane prior serves as an additional geometric condition to the ill-posed mapping and an extra source in depth estimation. In this way, we can get a more accurate depth estimation from the ground. Meanwhile, to take full advantage of the ground plane prior, we propose a depth-align training strategy and a precise two-stage depth inference method tailored for the ground plane prior. It is worth noting that the introduced ground plane prior requires no extra data sources like LiDAR, stereo images, and depth information. Extensive experiments on the KITTI benchmark show that our method could achieve state-of-the-art results compared with other methods while maintaining a very fast speed. Our code and models are available at https://github.com/cfzd/MonoGround.
VersatileGait: A Large-Scale Synthetic Gait Dataset Towards in-the-Wild Simulation
Jun 01, 2021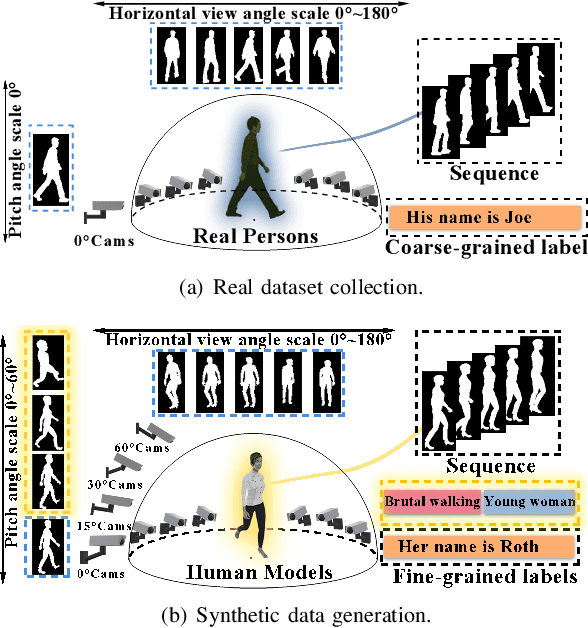
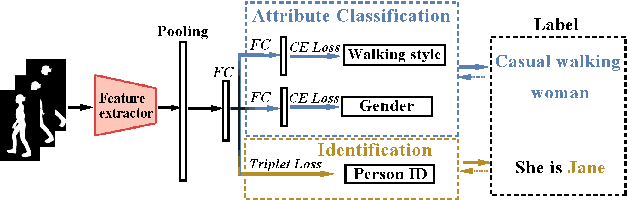
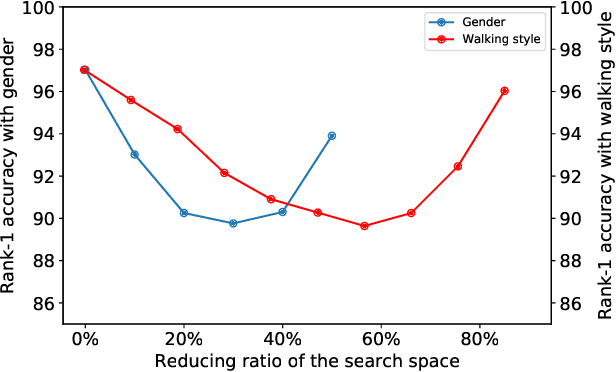
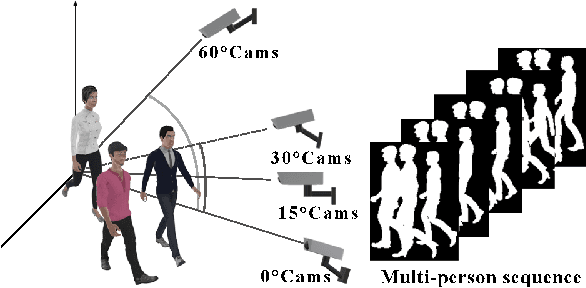
Gait recognition has a rapid development in recent years. However, gait recognition in the wild is not well explored yet. An obvious reason could be ascribed to the lack of diverse training data from the perspective of intrinsic and extrinsic factors. To remedy this problem, we propose to construct a large-scale gait dataset with the help of controllable computer simulation. In detail, to diversify the intrinsic factors of gait, we generate numerous characters with diverse attributes and empower them with various types of walking styles. To diversify the extrinsic factors of gait, we build a complicated scene with a dense camera layout. Finally, we design an automated generation toolkit under Unity3D for simulating the walking scenario and capturing the gait data automatically. As a result, we obtain an in-the-wild gait dataset, called VersatileGait, which has more than one million silhouette sequences of 10,000 subjects with diverse scenarios. VersatileGait possesses several nice properties, including huge dataset size, diverse pedestrian attributes, complicated camera layout, high-quality annotations, small domain gap with the real one, good scalability for new demands, and no privacy issues. Based on VersatileGait, we propose series of experiments and applications for both research exploration of gait in the wild and practical applications. Our dataset and its corresponding generation toolkit will be publicly available for further studies.
VersatileGait: A Large-Scale Synthetic Gait Dataset with Fine-GrainedAttributes and Complicated Scenarios
Jan 05, 2021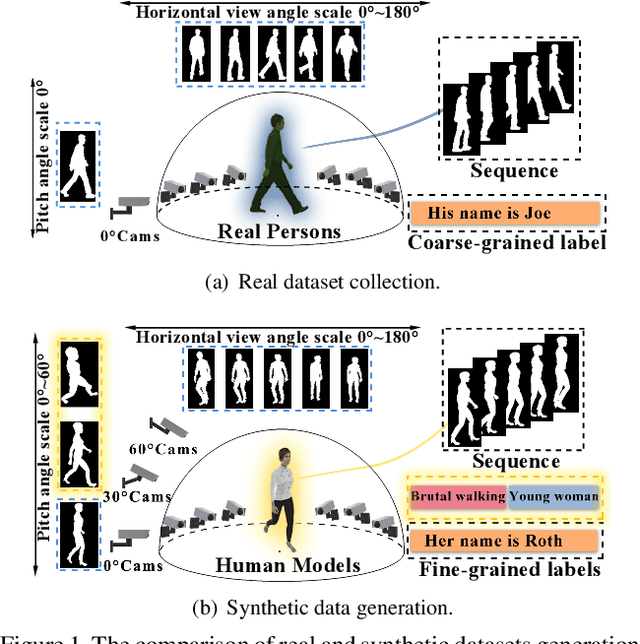


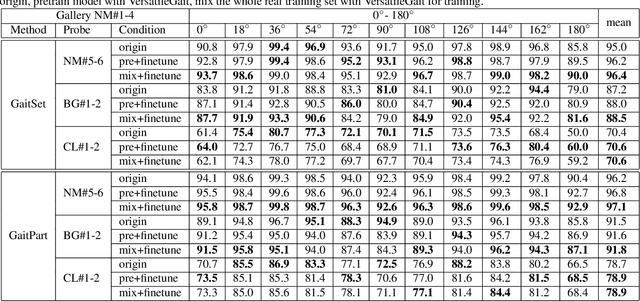
With the motivation of practical gait recognition applications, we propose to automatically create a large-scale synthetic gait dataset (called VersatileGait) by a game engine, which consists of around one million silhouette sequences of 11,000 subjects with fine-grained attributes in various complicated scenarios. Compared with existing real gait datasets with limited samples and simple scenarios, the proposed VersatileGait dataset possesses several nice properties, including huge dataset size, high sample diversity, high-quality annotations, multi-pitch angles, small domain gap with the real one, etc. Furthermore, we investigate the effectiveness of our dataset (e.g., domain transfer after pretraining). Then, we use the fine-grained attributes from VersatileGait to promote gait recognition in both accuracy and speed, and meanwhile justify the gait recognition performance under multi-pitch angle settings. Additionally, we explore a variety of potential applications for research.Extensive experiments demonstrate the value and effective-ness of the proposed VersatileGait in gait recognition along with its associated applications. We will release both VersatileGait and its corresponding data generation toolkit for further studies.
FcaNet: Frequency Channel Attention Networks
Dec 23, 2020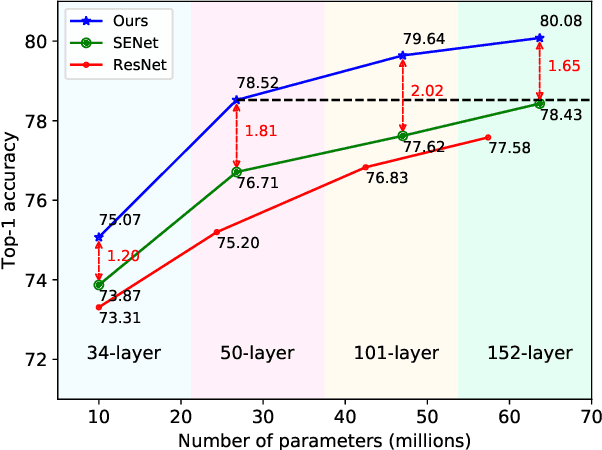

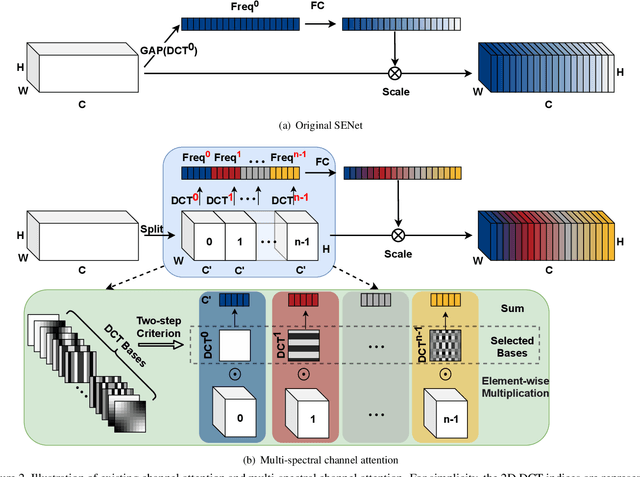
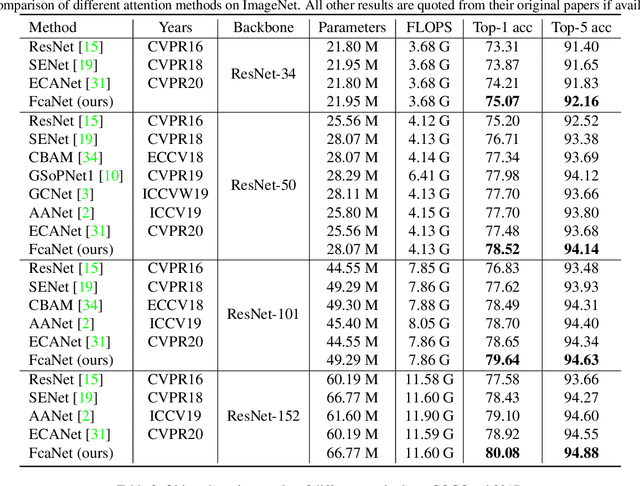
Attention mechanism, especially channel attention, has gained great success in the computer vision field. Many works focus on how to design efficient channel attention mechanisms while ignoring a fundamental problem, i.e., using global average pooling (GAP) as the unquestionable pre-processing method. In this work, we start from a different view and rethink channel attention using frequency analysis. Based on the frequency analysis, we mathematically prove that the conventional GAP is a special case of the feature decomposition in the frequency domain. With the proof, we naturally generalize the pre-processing of channel attention mechanism in the frequency domain and propose FcaNet with novel multi-spectral channel attention. The proposed method is simple but effective. We can change only one line of code in the calculation to implement our method within existing channel attention methods. Moreover, the proposed method achieves state-of-the-art results compared with other channel attention methods on image classification, object detection, and instance segmentation tasks. Our method could improve by 1.8% in terms of Top-1 accuracy on ImageNet compared with the baseline SENet-50, with the same number of parameters and the same computational cost. Our code and models will be made publicly available.
Dynamic Routing with Path Diversity and Consistency for Compact Network Learning
May 29, 2020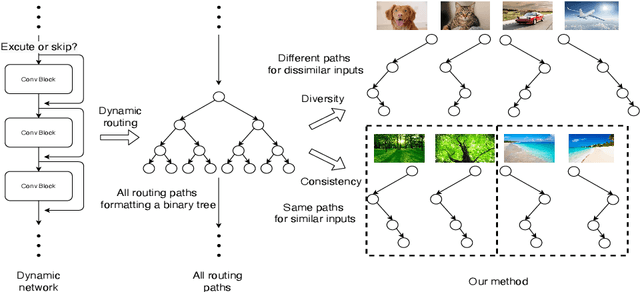
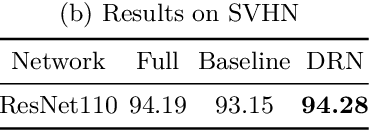


In this paper, we propose a novel dynamic routing inference method with diversity and consistency that better takes advantage of the network capacity. Specifically, by diverse routing, we achieve the goal of better utilizing of the network. By consistent routing, the better optimization of the routing mechanism is realized. Moreover, we propose a customizable computational cost controlling method that could balance the trade-off between cost and accuracy. Extensive ablation studies and experiments show that our method could achieve state-of-the-art results compared with the original full network, other dynamic networks and model compression methods. Our code will be made publicly available.