 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASH: Complementary Learning with Neural Architecture Search for Gait Recognition
Jul 04, 2024

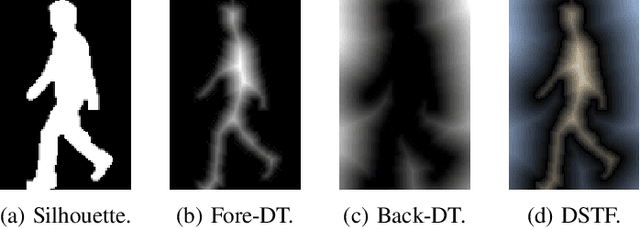

Gait recognition, which aims at identifying individuals by their walking patterns, has achieved great success based on silhouette. The binary silhouette sequence encodes the walking pattern within the sparse boundary representation. Therefore, most pixels in the silhouette are under-sensitive to the walking pattern since the sparse boundary lacks dense spatial-temporal information, which is suitable to be represented with dense texture. To enhance the sensitivity to the walking pattern while maintaining the robustness of recognition, we present a Complementary Learning with neural Architecture Search (CLASH) framework, consisting of walking pattern sensitive gait descriptor named dense spatial-temporal field (DSTF) and neural architecture search based complementary learning (NCL). Specifically, DSTF transforms the representation from the sparse binary boundary into the dense distance-based texture, which is sensitive to the walking pattern at the pixel level. Further, NCL presents a task-specific search space for complementary learning, which mutually complements the sensitivity of DSTF and the robustness of the silhouette to represent the walking pattern effectively. Extensive experiments demonstrate the effectiveness of the proposed methods under both in-the-lab and in-the-wild scenarios. On CASIA-B, we achieve rank-1 accuracy of 98.8%, 96.5%, and 89.3% under three conditions. On OU-MVLP, we achieve rank-1 accuracy of 91.9%. Under the latest in-the-wild datasets, we outperform the latest silhouette-based methods by 16.3% and 19.7% on Gait3D and GREW, respectively.
GaitGCI: Generative Counterfactual Intervention for Gait Recognition
Jun 06, 2023

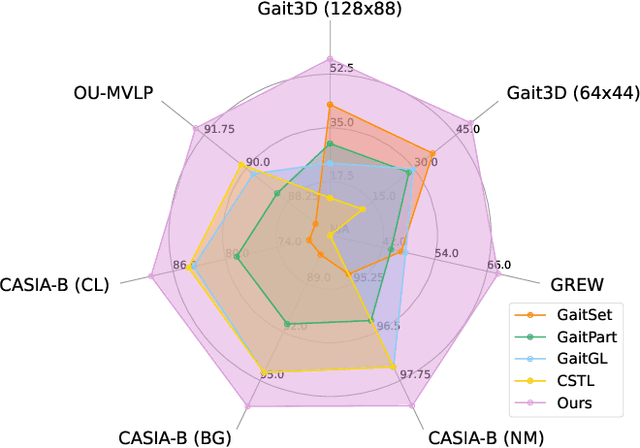
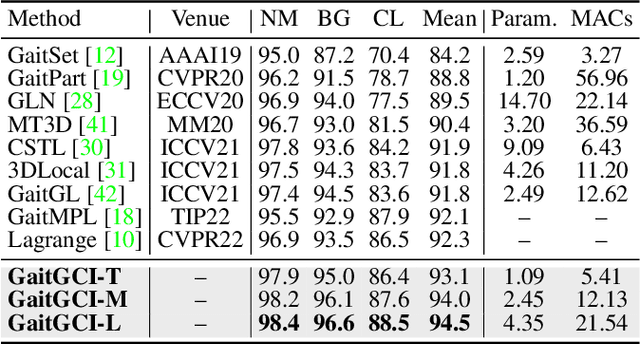
Gait is one of the most promising biometrics that aims to identify pedestrians from their walking patterns. However, prevailing methods are susceptible to confounders, resulting in the networks hardly focusing on the regions that reflect effective walking patterns. To address this fundamental problem in gait recognition, we propose a Generative Counterfactual Intervention framework, dubbed GaitGCI, consisting of Counterfactual Intervention Learning (CIL) and Diversity-Constrained Dynamic Convolution (DCDC). CIL eliminates the impacts of confounders by maximizing the likelihood difference between factual/counterfactual attention while DCDC adaptively generates sample-wise factual/counterfactual attention to efficiently perceive the sample-wise properties. With matrix decomposition and diversity constraint, DCDC guarantees the model to be efficient and effective. Extensive experiments indicate that proposed GaitGCI: 1) could effectively focus on the discriminative and interpretable regions that reflect gait pattern; 2) is model-agnostic and could be plugged into existing models to improve performance with nearly no extra cost; 3) efficiently achieves state-of-the-art performance on arbitrary scenarios (in-the-lab and in-the-wild).
GaitMPL: Gait Recognition with Memory-Augmented Progressive Learning
Jun 06, 2023Gait recognition aims at identifying the pedestrians at a long distance by their biometric gait patterns. It is inherently challenging due to the various covariates and the properties of silhouettes (textureless and colorless), which result in two kinds of pair-wise hard samples: the same pedestrian could have distinct silhouettes (intra-class diversity) and different pedestrians could have similar silhouettes (inter-class similarity). In this work, we propose to solve the hard sample issue with a Memory-augmented Progressive Learning network (GaitMPL), including Dynamic Reweighting Progressive Learning module (DRPL) and Global Structure-Aligned Memory bank (GSAM). Specifically, DRPL reduces the learning difficulty of hard samples by easy-to-hard progressive learning. GSAM further augments DRPL with a structure-aligned memory mechanism, which maintains and models the feature distribution of each ID. Experiments on two commonly used datasets, CASIA-B and OU-MVLP, demonstrate the effectiveness of GaitMPL. On CASIA-B, we achieve the state-of-the-art performance, i.e., 88.0% on the most challenging condition (Clothing) and 93.3% on the average condition, which outperforms the other methods by at least 3.8% and 1.4%, respectively.
MetaGait: Learning to Learn an Omni Sample Adaptive Representation for Gait Recognition
Jun 06, 2023Gait recognition, which aims at identifying individuals by their walking patterns, has recently drawn increasing research attention. However, gait recognition still suffers from the conflicts between the limited binary visual clues of the silhouette and numerous covariates with diverse scales, which brings challenges to the model's adaptiveness. In this paper, we address this conflict by developing a novel MetaGait that learns to learn an omni sample adaptive representation. Towards this goal, MetaGait injects meta-knowledge, which could guide the model to perceive sample-specific properties, into the calibration network of the attention mechanism to improve the adaptiveness from the omni-scale, omni-dimension, and omni-process perspectives. Specifically, we leverage the meta-knowledge across the entire process, where Meta Triple Attention and Meta Temporal Pooling are presented respectively to adaptively capture omni-scale dependency from spatial/channel/temporal dimensions simultaneously and to adaptively aggregate temporal information through integrating the merits of three complementary temporal aggregation methods. Extensive experiments demonstrate the state-of-the-art performance of the proposed MetaGait. On CASIA-B, we achieve rank-1 accuracy of 98.7%, 96.0%, and 89.3% under three conditions, respectively. On OU-MVLP, we achieve rank-1 accuracy of 92.4%.
Dissolving Is Amplifying: Towards Fine-Grained Anomaly Detection
Feb 28, 2023



Medical anomalous data normally contains fine-grained instance-wise additive feature patterns (e.g. tumor, hemorrhage), that are oftenly critical but insignificant. Interestingly, apart from the remarkable image generation abilities of diffusion models, we observed that diffusion models can dissolve image details for a given image, resulting in generalized feature representations. We hereby propose DIA, dissolving is amplifying, that amplifies fine-grained image features by contrasting an image against its feature dissolved counterpart. In particular, we show that diffusion models can serve as semantic preserving feature dissolvers that help learning fine-grained anomalous patterns for anomaly detection tasks, especially for medical domains with fine-grained feature differences. As a result, our method yields a novel fine-grained anomaly detection method, aims at amplifying instance-level feature patterns, that significantly improves medical anomaly detection accuracy in a large margin without any prior knowledge of explicit fine-grained anomalous feature patterns.
Ultra Fast Deep Lane Detection with Hybrid Anchor Driven Ordinal Classification
Jun 15, 2022
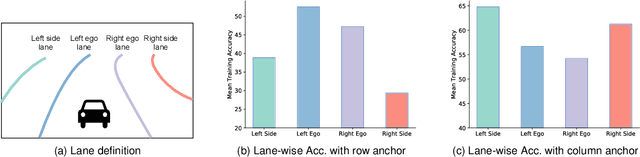

Modern methods mainly regard lane detection as a problem of pixel-wise segmentation, which is struggling to address the problems of efficiency and challenging scenarios like severe occlusions and extreme lighting conditions. Inspired by human perception, the recognition of lanes under severe occlusions and extreme lighting conditions is mainly based on contextual and global information. Motivated by this observation, we propose a novel, simple, yet effective formulation aiming at ultra fast speed and the problem of challenging scenarios. Specifically, we treat the process of lane detection as an anchor-driven ordinal classification problem using global features. First, we represent lanes with sparse coordinates on a series of hybrid (row and column) anchors. With the help of the anchor-driven representation, we then reformulate the lane detection task as an ordinal classification problem to get the coordinates of lanes. Our method could significantly reduce the computational cost with the anchor-driven representation. Using the large receptive field property of the ordinal classification formulation, we could also handle challenging scenarios. Extensive experiments on four lane detection datasets show that our method could achieve state-of-the-art performance in terms of both speed and accuracy. A lightweight version could even achieve 300+ frames per second(FPS). Our code is at https://github.com/cfzd/Ultra-Fast-Lane-Detection-v2.
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021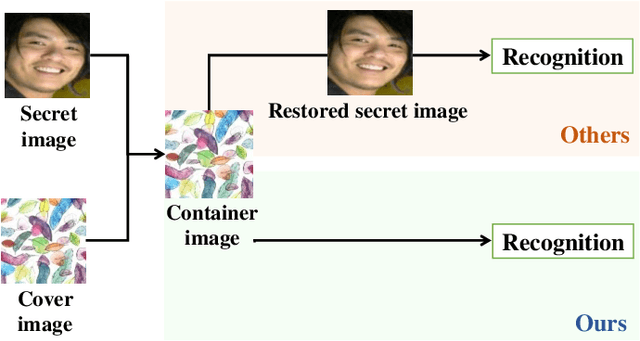

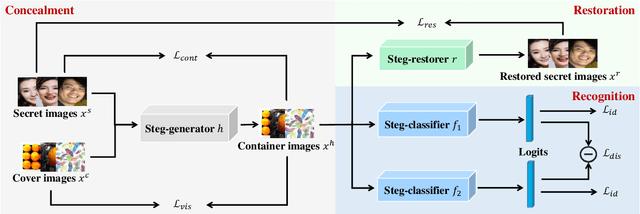
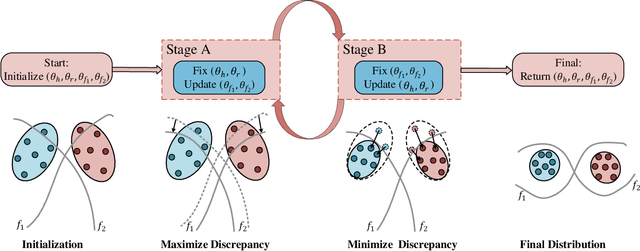
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
VersatileGait: A Large-Scale Synthetic Gait Dataset Towards in-the-Wild Simulation
Jun 01, 2021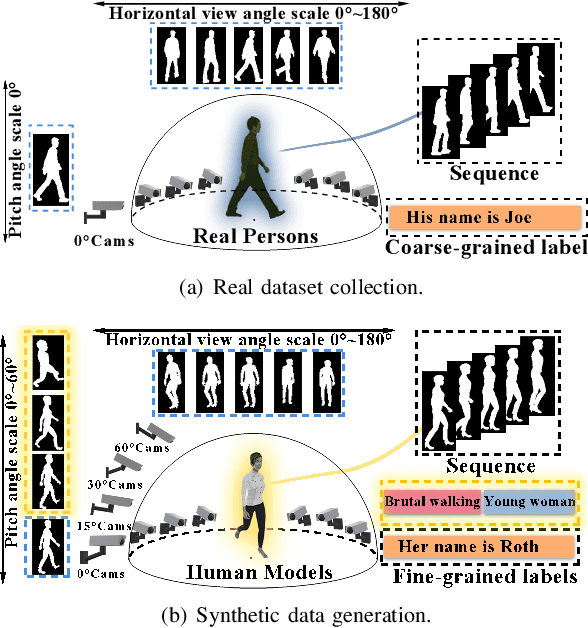
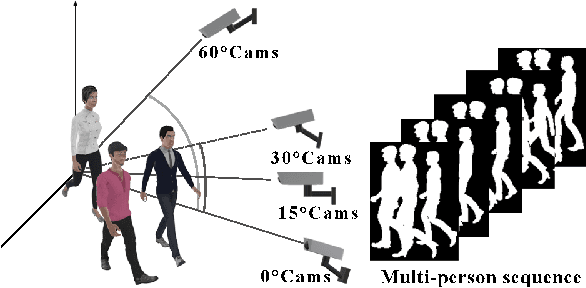
Gait recognition has a rapid development in recent years. However, gait recognition in the wild is not well explored yet. An obvious reason could be ascribed to the lack of diverse training data from the perspective of intrinsic and extrinsic factors. To remedy this problem, we propose to construct a large-scale gait dataset with the help of controllable computer simulation. In detail, to diversify the intrinsic factors of gait, we generate numerous characters with diverse attributes and empower them with various types of walking styles. To diversify the extrinsic factors of gait, we build a complicated scene with a dense camera layout. Finally, we design an automated generation toolkit under Unity3D for simulating the walking scenario and capturing the gait data automatically. As a result, we obtain an in-the-wild gait dataset, called VersatileGait, which has more than one million silhouette sequences of 10,000 subjects with diverse scenarios. VersatileGait possesses several nice properties, including huge dataset size, diverse pedestrian attributes, complicated camera layout, high-quality annotations, small domain gap with the real one, good scalability for new demands, and no privacy issues. Based on VersatileGait, we propose series of experiments and applications for both research exploration of gait in the wild and practical applications. Our dataset and its corresponding generation toolkit will be publicly available for further studies.
VersatileGait: A Large-Scale Synthetic Gait Dataset with Fine-GrainedAttributes and Complicated Scenarios
Jan 05, 2021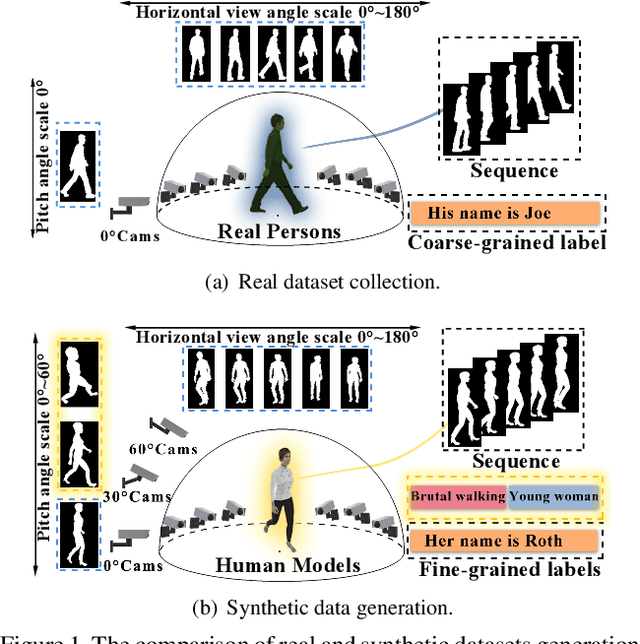


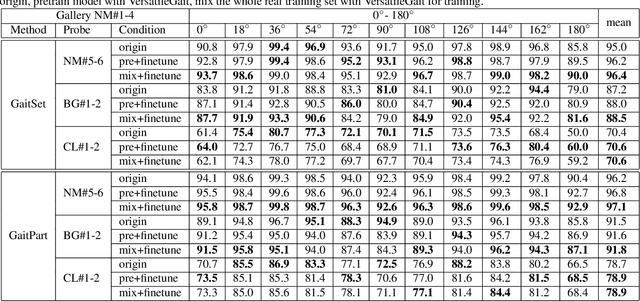
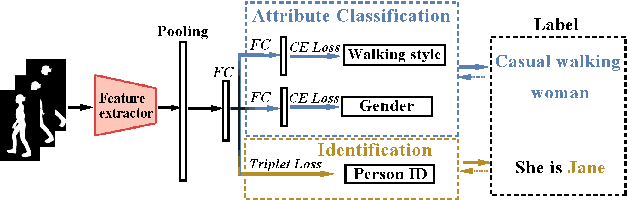
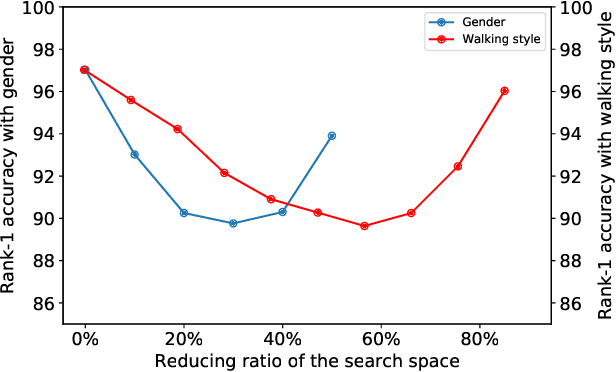
With the motivation of practical gait recognition applications, we propose to automatically create a large-scale synthetic gait dataset (called VersatileGait) by a game engine, which consists of around one million silhouette sequences of 11,000 subjects with fine-grained attributes in various complicated scenarios. Compared with existing real gait datasets with limited samples and simple scenarios, the proposed VersatileGait dataset possesses several nice properties, including huge dataset size, high sample diversity, high-quality annotations, multi-pitch angles, small domain gap with the real one, etc. Furthermore, we investigate the effectiveness of our dataset (e.g., domain transfer after pretraining). Then, we use the fine-grained attributes from VersatileGait to promote gait recognition in both accuracy and speed, and meanwhile justify the gait recognition performance under multi-pitch angle settings. Additionally, we explore a variety of potential applications for research.Extensive experiments demonstrate the value and effective-ness of the proposed VersatileGait in gait recognition along with its associated applications. We will release both VersatileGait and its corresponding data generation toolkit for further studies.
FcaNet: Frequency Channel Attention Networks
Dec 23, 2020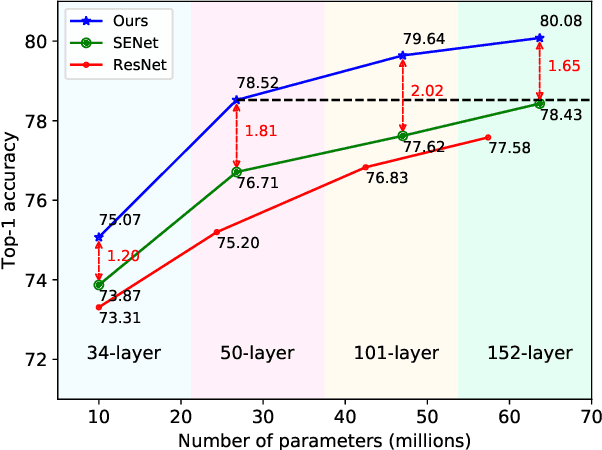

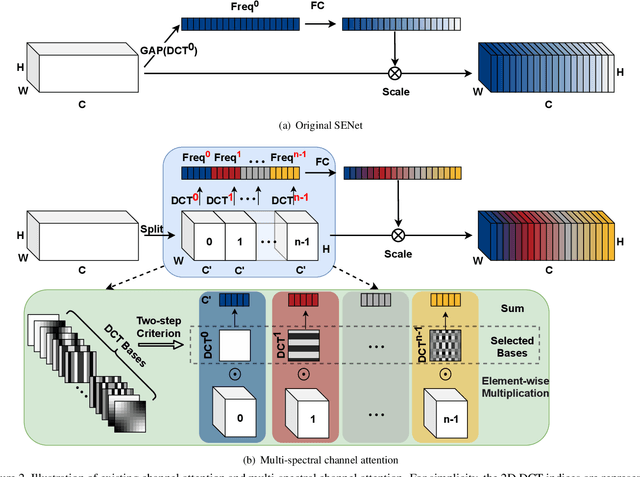
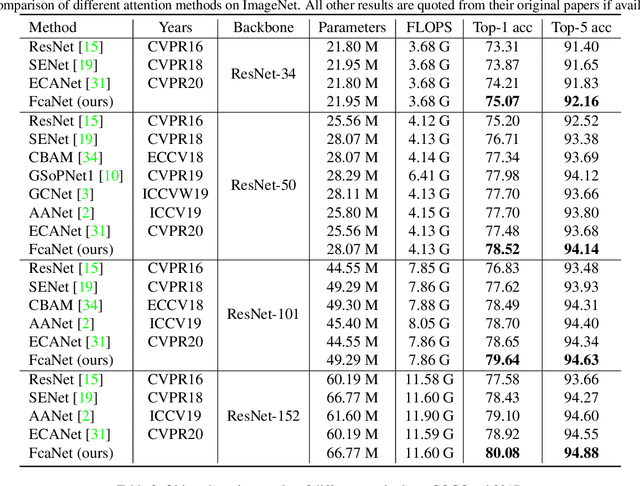
Attention mechanism, especially channel attention, has gained great success in the computer vision field. Many works focus on how to design efficient channel attention mechanisms while ignoring a fundamental problem, i.e., using global average pooling (GAP) as the unquestionable pre-processing method. In this work, we start from a different view and rethink channel attention using frequency analysis. Based on the frequency analysis, we mathematically prove that the conventional GAP is a special case of the feature decomposition in the frequency domain. With the proof, we naturally generalize the pre-processing of channel attention mechanism in the frequency domain and propose FcaNet with novel multi-spectral channel attention. The proposed method is simple but effective. We can change only one line of code in the calculation to implement our method within existing channel attention methods. Moreover, the proposed method achieves state-of-the-art results compared with other channel attention methods on image classification, object detection, and instance segmentation tasks. Our method could improve by 1.8% in terms of Top-1 accuracy on ImageNet compared with the baseline SENet-50, with the same number of parameters and the same computational cost. Our code and models will be made publicly available.