 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention
May 19, 2026Diffusion Language Models (DLMs) enable globally coherent, bidirectional, and controllable text generation, offering advantages over traditional autoregressive LLMs, while scaling to ultra-long sequences remains costly. Many existing block-sparse attention methods select blocks by fixed sampling patterns over the high-resolution attention space, such as tail regions or anti-diagonal stripes. Such prior-driven sampling can miss salient tokens and introduce instability under distribution shifts. In this paper, we propose the Block Approximate Sparse Attention framework (BA-Att) with block-wise pre-downsampled operation, which identifies informative regions within a compact downsampled space, avoiding reliance on brittle positional priors. To analyze its theoretical behavior, we define an oracle post-downsample attention map and formalize the approximation error between pre- and post-downsample schemes. Based on this insight, we introduce a lightweight norm-sorting module and a covariance-compensated correction that approximates full covariance using diagonal QK variances, reducing computational complexity. Extensive experiments show that our operator achieves up to 6.95x acceleration over FlashAttention in attention computation, and maintains near full-attention performance at 50% sparsity across language models, multimodal language models, and video generation models, demonstrating strong efficiency and generalization.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
VideoMaker: Zero-shot Customized Video Generation with the Inherent Force of Video Diffusion Models
Dec 27, 2024


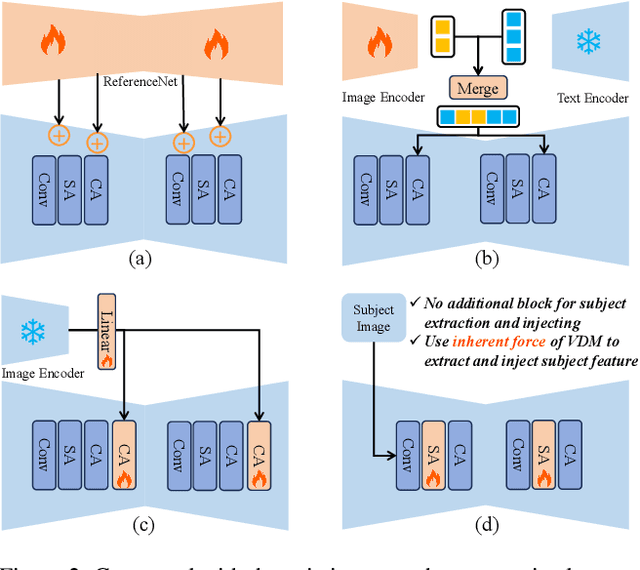
Zero-shot customized video generation has gained significant attention due to its substantial application potential. Existing methods rely on additional models to extract and inject reference subject features, assuming that the Video Diffusion Model (VDM) alone is insufficient for zero-shot customized video generation. However, these methods often struggle to maintain consistent subject appearance due to suboptimal feature extraction and injection techniques. In this paper, we reveal that VDM inherently possesses the force to extract and inject subject features. Departing from previous heuristic approaches, we introduce a novel framework that leverages VDM's inherent force to enable high-quality zero-shot customized video generation. Specifically, for feature extraction, we directly input reference images into VDM and use its intrinsic feature extraction process, which not only provides fine-grained features but also significantly aligns with VDM's pre-trained knowledge. For feature injection, we devise an innovative bidirectional interaction between subject features and generated content through spatial self-attention within VDM, ensuring that VDM has better subject fidelity while maintaining the diversity of the generated video.Experiments on both customized human and object video generation validate the effectiveness of our framework.
ChatDiT: A Training-Free Baseline for Task-Agnostic Free-Form Chatting with Diffusion Transformers
Dec 17, 2024



Recent research arXiv:2410.15027 arXiv:2410.23775 has highlighted the inherent in-context generation capabilities of pretrained diffusion transformers (DiTs), enabling them to seamlessly adapt to diverse visual tasks with minimal or no architectural modifications. These capabilities are unlocked by concatenating self-attention tokens across multiple input and target images, combined with grouped and masked generation pipelines. Building upon this foundation, we present ChatDiT, a zero-shot, general-purpose, and interactive visual generation framework that leverages pretrained diffusion transformers in their original form, requiring no additional tuning, adapters, or modifications. Users can interact with ChatDiT to create interleaved text-image articles, multi-page picture books, edit images, design IP derivatives, or develop character design settings, all through free-form natural language across one or more conversational rounds. At its core, ChatDiT employs a multi-agent system comprising three key components: an Instruction-Parsing agent that interprets user-uploaded images and instructions, a Strategy-Planning agent that devises single-step or multi-step generation actions, and an Execution agent that performs these actions using an in-context toolkit of diffusion transformers. We thoroughly evaluate ChatDiT on IDEA-Bench arXiv:2412.11767, comprising 100 real-world design tasks and 275 cases with diverse instructions and varying numbers of input and target images. Despite its simplicity and training-free approach, ChatDiT surpasses all competitors, including those specifically designed and trained on extensive multi-task datasets. We further identify key limitations of pretrained DiTs in zero-shot adapting to tasks. We release all code, agents, results, and intermediate outputs to facilitate further research at https://github.com/ali-vilab/ChatDiT
IDEA-Bench: How Far are Generative Models from Professional Designing?
Dec 16, 2024



Real-world design tasks - such as picture book creation, film storyboard development using character sets, photo retouching, visual effects, and font transfer - are highly diverse and complex, requiring deep interpretation and extraction of various elements from instructions, descriptions, and reference images. The resulting images often implicitly capture key features from references or user inputs, making it challenging to develop models that can effectively address such varied tasks. While existing visual generative models can produce high-quality images based on prompts, they face significant limitations in professional design scenarios that involve varied forms and multiple inputs and outputs, even when enhanced with adapters like ControlNets and LoRAs. To address this, we introduce IDEA-Bench, a comprehensive benchmark encompassing 100 real-world design tasks, including rendering, visual effects, storyboarding, picture books, fonts, style-based, and identity-preserving generation, with 275 test cases to thoroughly evaluate a model's general-purpose generation capabilities. Notably, even the best-performing model only achieves 22.48 on IDEA-Bench, while the best general-purpose model only achieves 6.81. We provide a detailed analysis of these results, highlighting the inherent challenges and providing actionable directions for improvement. Additionally, we provide a subset of 18 representative tasks equipped with multimodal large language model (MLLM)-based auto-evaluation techniques to facilitate rapid model development and comparison. We releases the benchmark data, evaluation toolkits, and an online leaderboard at https://github.com/ali-vilab/IDEA-Bench, aiming to drive the advancement of generative models toward more versatile and applicable intelligent design systems.
In-Context LoRA for Diffusion Transformers
Oct 31, 2024



Recent research arXiv:2410.15027 has explored the use of diffusion transformers (DiTs) for task-agnostic image generation by simply concatenating attention tokens across images. However, despite substantial computational resources, the fidelity of the generated images remains suboptimal. In this study, we reevaluate and streamline this framework by hypothesizing that text-to-image DiTs inherently possess in-context generation capabilities, requiring only minimal tuning to activate them. Through diverse task experiments, we qualitatively demonstrate that existing text-to-image DiTs can effectively perform in-context generation without any tuning. Building on this insight, we propose a remarkably simple pipeline to leverage the in-context abilities of DiTs: (1) concatenate images instead of tokens, (2) perform joint captioning of multiple images, and (3) apply task-specific LoRA tuning using small datasets (e.g., $20\sim 100$ samples) instead of full-parameter tuning with large datasets. We name our models In-Context LoRA (IC-LoRA). This approach requires no modifications to the original DiT models, only changes to the training data. Remarkably, our pipeline generates high-fidelity image sets that better adhere to prompts. While task-specific in terms of tuning data, our framework remains task-agnostic in architecture and pipeline, offering a powerful tool for the community and providing valuable insights for further research on product-level task-agnostic generation systems. We release our code, data, and models at https://github.com/ali-vilab/In-Context-LoRA
Group Diffusion Transformers are Unsupervised Multitask Learners
Oct 19, 2024
While large language models (LLMs) have revolutionized natural language processing with their task-agnostic capabilities, visual generation tasks such as image translation, style transfer, and character customization still rely heavily on supervised, task-specific datasets. In this work, we introduce Group Diffusion Transformers (GDTs), a novel framework that unifies diverse visual generation tasks by redefining them as a group generation problem. In this approach, a set of related images is generated simultaneously, optionally conditioned on a subset of the group. GDTs build upon diffusion transformers with minimal architectural modifications by concatenating self-attention tokens across images. This allows the model to implicitly capture cross-image relationships (e.g., identities, styles, layouts, surroundings, and color schemes) through caption-based correlations. Our design enables scalable, unsupervised, and task-agnostic pretraining using extensive collections of image groups sourced from multimodal internet articles, image galleries, and video frames. We evaluate GDTs on a comprehensive benchmark featuring over 200 instructions across 30 distinct visual generation tasks, including picture book creation, font design, style transfer, sketching, colorization, drawing sequence generation, and character customization. Our models achieve competitive zero-shot performance without any additional fine-tuning or gradient updates. Furthermore, ablation studies confirm the effectiveness of key components such as data scaling, group size, and model design. These results demonstrate the potential of GDTs as scalable, general-purpose visual generation systems.
CLASH: Complementary Learning with Neural Architecture Search for Gait Recognition
Jul 04, 2024

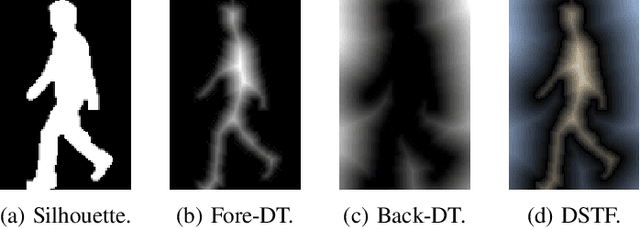

Gait recognition, which aims at identifying individuals by their walking patterns, has achieved great success based on silhouette. The binary silhouette sequence encodes the walking pattern within the sparse boundary representation. Therefore, most pixels in the silhouette are under-sensitive to the walking pattern since the sparse boundary lacks dense spatial-temporal information, which is suitable to be represented with dense texture. To enhance the sensitivity to the walking pattern while maintaining the robustness of recognition, we present a Complementary Learning with neural Architecture Search (CLASH) framework, consisting of walking pattern sensitive gait descriptor named dense spatial-temporal field (DSTF) and neural architecture search based complementary learning (NCL). Specifically, DSTF transforms the representation from the sparse binary boundary into the dense distance-based texture, which is sensitive to the walking pattern at the pixel level. Further, NCL presents a task-specific search space for complementary learning, which mutually complements the sensitivity of DSTF and the robustness of the silhouette to represent the walking pattern effectively. Extensive experiments demonstrate the effectiveness of the proposed methods under both in-the-lab and in-the-wild scenarios. On CASIA-B, we achieve rank-1 accuracy of 98.8%, 96.5%, and 89.3% under three conditions. On OU-MVLP, we achieve rank-1 accuracy of 91.9%. Under the latest in-the-wild datasets, we outperform the latest silhouette-based methods by 16.3% and 19.7% on Gait3D and GREW, respectively.
GVDIFF: Grounded Text-to-Video Generation with Diffusion Models
Jul 02, 2024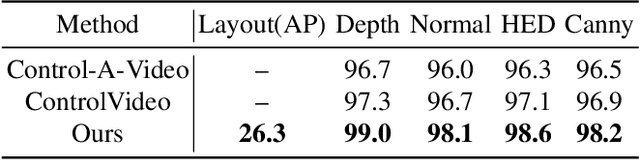
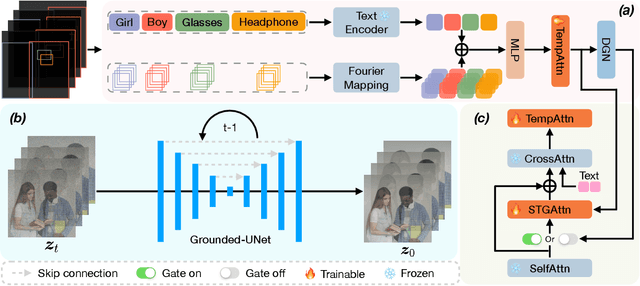

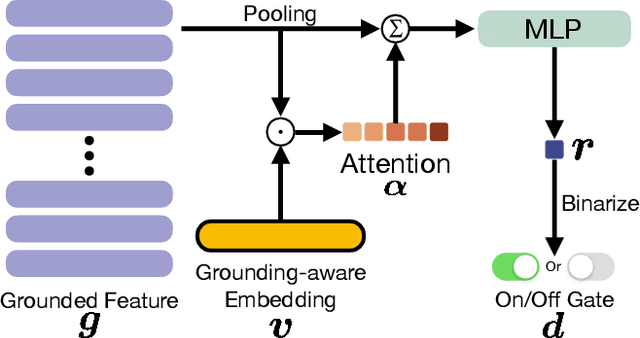
In text-to-video (T2V) generation, significant attention has been directed toward its development, yet unifying discrete and continuous grounding conditions in T2V generation remains under-explored. This paper proposes a Grounded text-to-Video generation framework, termed GVDIFF. First, we inject the grounding condition into the self-attention through an uncertainty-based representation to explicitly guide the focus of the network. Second, we introduce a spatial-temporal grounding layer that connects the grounding condition with target objects and enables the model with the grounded generation capacity in the spatial-temporal domain. Third, our dynamic gate network adaptively skips the redundant grounding process to selectively extract grounding information and semantics while improving efficiency. We extensively evaluate the grounded generation capacity of GVDIFF and demonstrate its versatility in applications, including long-range video generation, sequential prompts, and object-specific editing.
ScanFormer: Referring Expression Comprehension by Iteratively Scanning
Jun 26, 2024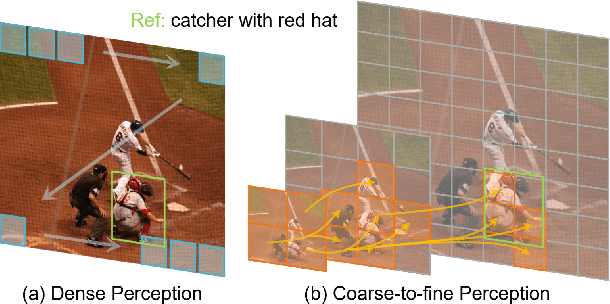
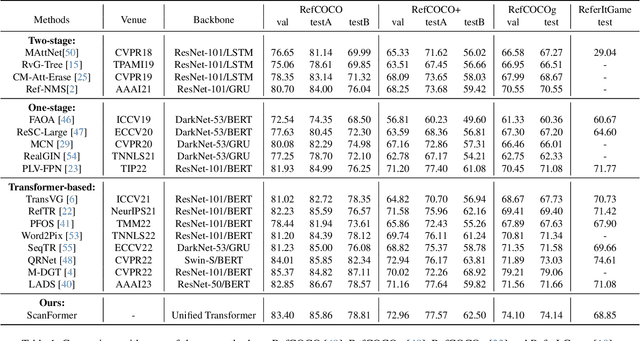
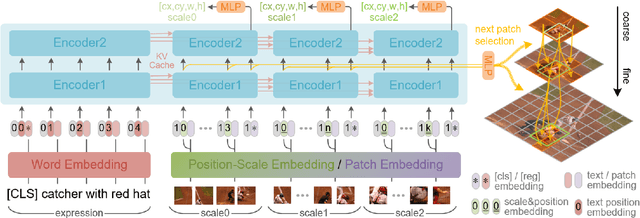
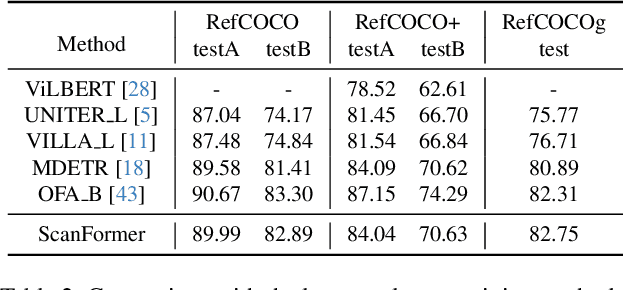
Referring Expression Comprehension (REC) aims to localize the target objects specified by free-form natural language descriptions in images. While state-of-the-art methods achieve impressive performance, they perform a dense perception of images, which incorporates redundant visual regions unrelated to linguistic queries, leading to additional computational overhead. This inspires us to explore a question: can we eliminate linguistic-irrelevant redundant visual regions to improve the efficiency of the model? Existing relevant methods primarily focus on fundamental visual tasks, with limited exploration in vision-language fields. To address this, we propose a coarse-to-fine iterative perception framework, called ScanFormer. It can iteratively exploit the image scale pyramid to extract linguistic-relevant visual patches from top to bottom. In each iteration, irrelevant patches are discarded by our designed informativeness prediction. Furthermore, we propose a patch selection strategy for discarded patches to accelerate inference. Experiments on widely used datasets, namely RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, verify the effectiveness of our method, which can strike a balance between accuracy and efficiency.