 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Calibration-Aware Policy Optimization for Reasoning LLMs
Apr 14, 2026Group Relative Policy Optimization (GRPO) enhances LLM reasoning but often induces overconfidence, where incorrect responses yield lower perplexity than correct ones, degrading relative calibration as described by the Area Under the Curve (AUC). Existing approaches either yield limited improvements in calibration or sacrifice gains in reasoning accuracy. We first prove that this degradation in GRPO-style algorithms stems from their uncertainty-agnostic advantage estimation, which inevitably misaligns optimization gradients with calibration. This leads to improved accuracy at the expense of degraded calibration. We then propose Calibration-Aware Policy Optimization (CAPO). It adopts a logistic AUC surrogate loss that is theoretically consistent and admits regret bound, enabling uncertainty-aware advantage estimation. By further incorporating a noise masking mechanism, CAPO achieves stable learning dynamics that jointly optimize calibration and accuracy. Experiments on multiple mathematical reasoning benchmarks show that CAPO-1.5B significantly improves calibration by up to 15% while achieving accuracy comparable to or better than GRPO, and further boosts accuracy on downstream inference-time scaling tasks by up to 5%. Moreover, when allowed to abstain under low-confidence conditions, CAPO achieves a Pareto-optimal precision-coverage trade-off, highlighting its practical value for hallucination mitigation.
Persistent Backdoor Attacks under Continual Fine-Tuning of LLMs
Dec 12, 2025Backdoor attacks embed malicious behaviors into Large Language Models (LLMs), enabling adversaries to trigger harmful outputs or bypass safety controls. However, the persistence of the implanted backdoors under user-driven post-deployment continual fine-tuning has been rarely examined. Most prior works evaluate the effectiveness and generalization of implanted backdoors only at releasing and empirical evidence shows that naively injected backdoor persistence degrades after updates. In this work, we study whether and how implanted backdoors persist through a multi-stage post-deployment fine-tuning. We propose P-Trojan, a trigger-based attack algorithm that explicitly optimizes for backdoor persistence across repeated updates. By aligning poisoned gradients with those of clean tasks on token embeddings, the implanted backdoor mapping is less likely to be suppressed or forgotten during subsequent updates. Theoretical analysis shows the feasibility of such persistent backdoor attacks after continual fine-tuning. And experiments conducted on the Qwen2.5 and LLaMA3 families of LLMs, as well as diverse task sequences, demonstrate that P-Trojan achieves over 99% persistence while preserving clean-task accuracy. Our findings highlight the need for persistence-aware evaluation and stronger defenses in realistic model adaptation pipelines.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
May 26, 2025The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
Uncertainty-Aware Diffusion Guided Refinement of 3D Scenes
Mar 19, 2025Reconstructing 3D scenes from a single image is a fundamentally ill-posed task due to the severely under-constrained nature of the problem. Consequently, when the scene is rendered from novel camera views, existing single image to 3D reconstruction methods render incoherent and blurry views. This problem is exacerbated when the unseen regions are far away from the input camera. In this work, we address these inherent limitations in existing single image-to-3D scene feedforward networks. To alleviate the poor performance due to insufficient information beyond the input image's view, we leverage a strong generative prior in the form of a pre-trained latent video diffusion model, for iterative refinement of a coarse scene represented by optimizable Gaussian parameters. To ensure that the style and texture of the generated images align with that of the input image, we incorporate on-the-fly Fourier-style transfer between the generated images and the input image. Additionally, we design a semantic uncertainty quantification module that calculates the per-pixel entropy and yields uncertainty maps used to guide the refinement process from the most confident pixels while discarding the remaining highly uncertain ones. We conduct extensive experiments on real-world scene datasets, including in-domain RealEstate-10K and out-of-domain KITTI-v2, showing that our approach can provide more realistic and high-fidelity novel view synthesis results compared to existing state-of-the-art methods.
EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning
Feb 18, 2025
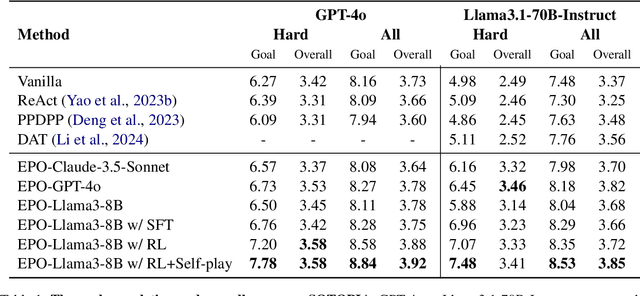
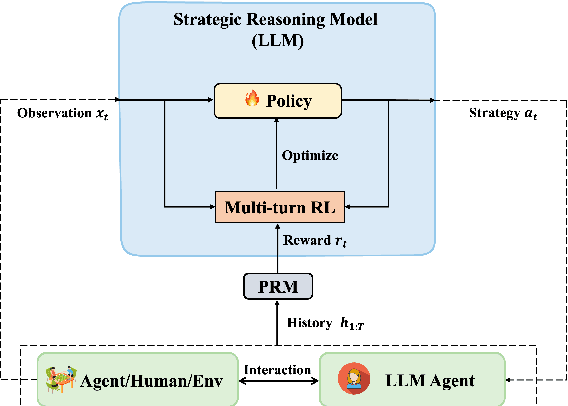
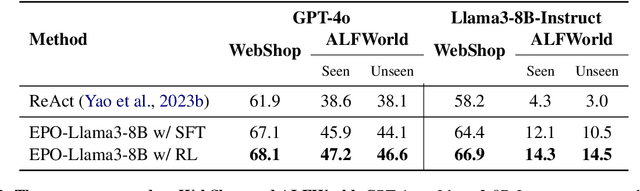
Large Language Models (LLMs) have shown impressive reasoning capabilities in well-defined problems with clear solutions, such as mathematics and coding. However, they still struggle with complex real-world scenarios like business negotiations, which require strategic reasoning-an ability to navigate dynamic environments and align long-term goals amidst uncertainty. Existing methods for strategic reasoning face challenges in adaptability, scalability, and transferring strategies to new contexts. To address these issues, we propose explicit policy optimization (EPO) for strategic reasoning, featuring an LLM that provides strategies in open-ended action space and can be plugged into arbitrary LLM agents to motivate goal-directed behavior. To improve adaptability and policy transferability, we train the strategic reasoning model via multi-turn reinforcement learning (RL) using process rewards and iterative self-play, without supervised fine-tuning (SFT) as a preliminary step. Experiments across social and physical domains demonstrate EPO's ability of long-term goal alignment through enhanced strategic reasoning, achieving state-of-the-art performance on social dialogue and web navigation tasks. Our findings reveal various collaborative reasoning mechanisms emergent in EPO and its effectiveness in generating novel strategies, underscoring its potential for strategic reasoning in real-world applications.
IDEA-Bench: How Far are Generative Models from Professional Designing?
Dec 16, 2024



Real-world design tasks - such as picture book creation, film storyboard development using character sets, photo retouching, visual effects, and font transfer - are highly diverse and complex, requiring deep interpretation and extraction of various elements from instructions, descriptions, and reference images. The resulting images often implicitly capture key features from references or user inputs, making it challenging to develop models that can effectively address such varied tasks. While existing visual generative models can produce high-quality images based on prompts, they face significant limitations in professional design scenarios that involve varied forms and multiple inputs and outputs, even when enhanced with adapters like ControlNets and LoRAs. To address this, we introduce IDEA-Bench, a comprehensive benchmark encompassing 100 real-world design tasks, including rendering, visual effects, storyboarding, picture books, fonts, style-based, and identity-preserving generation, with 275 test cases to thoroughly evaluate a model's general-purpose generation capabilities. Notably, even the best-performing model only achieves 22.48 on IDEA-Bench, while the best general-purpose model only achieves 6.81. We provide a detailed analysis of these results, highlighting the inherent challenges and providing actionable directions for improvement. Additionally, we provide a subset of 18 representative tasks equipped with multimodal large language model (MLLM)-based auto-evaluation techniques to facilitate rapid model development and comparison. We releases the benchmark data, evaluation toolkits, and an online leaderboard at https://github.com/ali-vilab/IDEA-Bench, aiming to drive the advancement of generative models toward more versatile and applicable intelligent design systems.
Rethinking Generalizability and Discriminability of Self-Supervised Learning from Evolutionary Game Theory Perspective
Nov 30, 2024



Representations learned by self-supervised approaches are generally considered to possess sufficient generalizability and discriminability. However, we disclose a nontrivial mutual-exclusion relationship between these critical representation properties through an exploratory demonstration on self-supervised learning. State-of-the-art self-supervised methods tend to enhance either generalizability or discriminability but not both simultaneously. Thus, learning representations jointly possessing strong generalizability and discriminability presents a specific challenge for self-supervised learning. To this end, we revisit the learning paradigm of self-supervised learning from the perspective of evolutionary game theory (EGT) and outline the theoretical roadmap to achieve a desired trade-off between these representation properties. EGT performs well in analyzing the trade-off point in a two-player game by utilizing dynamic system modeling. However, the EGT analysis requires sufficient annotated data, which contradicts the principle of self-supervised learning, i.e., the EGT analysis cannot be conducted without the annotations of the specific target domain for self-supervised learning. Thus, to enhance the methodological generalization, we propose a novel self-supervised learning method that leverages advancements in reinforcement learning to jointly benefit from the general guidance of EGT and sequentially optimize the model to chase the consistent improvement of generalizability and discriminability for specific target domains during pre-training. Theoretically, we establish that the proposed method tightens the generalization error upper bound of self-supervised learning. Empirically, our method achieves state-of-the-art performance on various benchmarks.
Uncertainty-aware Reward Model: Teaching Reward Models to Know What is Unknown
Oct 01, 2024Reward models (RM) play a critical role in aligning generations of large language models (LLM) to human expectations. However, prevailing RMs fail to capture the stochasticity within human preferences and cannot effectively evaluate the reliability of reward predictions. To address these issues, we propose Uncertain-aware RM (URM) and Uncertain-aware RM Ensemble (URME) to incorporate and manage uncertainty in reward modeling. URM can model the distribution of disentangled attributes within human preferences, while URME quantifies uncertainty through discrepancies in the ensemble, thereby identifying potential lack of knowledge during reward evaluation. Experiment results indicate that the proposed URM achieves state-of-the-art performance compared to models with the same size, demonstrating the effectiveness of modeling uncertainty within human preferences. Furthermore, empirical results show that through uncertainty quantification, URM and URME can identify unreliable predictions to improve the quality of reward evaluations.