 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deployment-Friendly Foundational Framework for Efficient Computational Pathology
Feb 15, 2026Pathology foundation models (PFMs) have enabled robust generalization in computational pathology through large-scale datasets and expansive architectures, but their substantial computational cost, particularly for gigapixel whole slide images, limits clinical accessibility and scalability. Here, we present LitePath, a deployment-friendly foundational framework designed to mitigate model over-parameterization and patch level redundancy. LitePath integrates LiteFM, a compact model distilled from three large PFMs (Virchow2, H-Optimus-1 and UNI2) using 190 million patches, and the Adaptive Patch Selector (APS), a lightweight component for task-specific patch selection. The framework reduces model parameters by 28x and lowers FLOPs by 403.5x relative to Virchow2, enabling deployment on low-power edge hardware such as the NVIDIA Jetson Orin Nano Super. On this device, LitePath processes 208 slides per hour, 104.5x faster than Virchow2, and consumes 0.36 kWh per 3,000 slides, 171x lower than Virchow2 on an RTX3090 GPU. We validated accuracy using 37 cohorts across four organs and 26 tasks (26 internal, 9 external, and 2 prospective), comprising 15,672 slides from 9,808 patients disjoint from the pretraining data. LitePath ranks second among 19 evaluated models and outperforms larger models including H-Optimus-1, mSTAR, UNI2 and GPFM, while retaining 99.71% of the AUC of Virchow2 on average. To quantify the balance between accuracy and efficiency, we propose the Deployability Score (D-Score), defined as the weighted geometric mean of normalized AUC and normalized FLOP, where LitePath achieves the highest value, surpassing Virchow2 by 10.64%. These results demonstrate that LitePath enables rapid, cost-effective and energy-efficient pathology image analysis on accessible hardware while maintaining accuracy comparable to state-of-the-art PFMs and reducing the carbon footprint of AI deployment.
A Graph Prompt Fine-Tuning Method for WSN Spatio-Temporal Correlation Anomaly Detection
Jan 19, 2026Anomaly detection of multi-temporal modal data in Wireless Sensor Network (WSN) can provide an important guarantee for reliable network operation. Existing anomaly detection methods in multi-temporal modal data scenarios have the problems of insufficient extraction of spatio-temporal correlation features, high cost of anomaly sample category annotation, and imbalance of anomaly samples. In this paper, a graph neural network anomaly detection backbone network incorporating spatio-temporal correlation features and a multi-task self-supervised training strategy of "pre-training - graph prompting - fine-tuning" are designed for the characteristics of WSN graph structure data. First, the anomaly detection backbone network is designed by improving the Mamba model based on a multi-scale strategy and inter-modal fusion method, and combining it with a variational graph convolution module, which is capable of fully extracting spatio-temporal correlation features in the multi-node, multi-temporal modal scenarios of WSNs. Secondly, we design a three-subtask learning "pre-training" method with no-negative comparative learning, prediction, and reconstruction to learn generic features of WSN data samples from unlabeled data, and design a "graph prompting-fine-tuning" mechanism to guide the pre-trained self-supervised learning. The model is fine-tuned through the "graph prompting-fine-tuning" mechanism to guide the pre-trained self-supervised learning model to complete the parameter fine-tuning, thereby reducing the training cost and enhancing the detection generalization performance. The F1 metrics obtained from experiments on the public dataset and the actual collected dataset are up to 91.30% and 92.31%, respectively, which provides better detection performance and generalization ability than existing methods designed by the method.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Persistent Backdoor Attacks under Continual Fine-Tuning of LLMs
Dec 12, 2025Backdoor attacks embed malicious behaviors into Large Language Models (LLMs), enabling adversaries to trigger harmful outputs or bypass safety controls. However, the persistence of the implanted backdoors under user-driven post-deployment continual fine-tuning has been rarely examined. Most prior works evaluate the effectiveness and generalization of implanted backdoors only at releasing and empirical evidence shows that naively injected backdoor persistence degrades after updates. In this work, we study whether and how implanted backdoors persist through a multi-stage post-deployment fine-tuning. We propose P-Trojan, a trigger-based attack algorithm that explicitly optimizes for backdoor persistence across repeated updates. By aligning poisoned gradients with those of clean tasks on token embeddings, the implanted backdoor mapping is less likely to be suppressed or forgotten during subsequent updates. Theoretical analysis shows the feasibility of such persistent backdoor attacks after continual fine-tuning. And experiments conducted on the Qwen2.5 and LLaMA3 families of LLMs, as well as diverse task sequences, demonstrate that P-Trojan achieves over 99% persistence while preserving clean-task accuracy. Our findings highlight the need for persistence-aware evaluation and stronger defenses in realistic model adaptation pipelines.
SoMe: A Realistic Benchmark for LLM-based Social Media Agents
Dec 09, 2025Intelligent agents powered by large language models (LLMs) have recently demonstrated impressive capabilities and gained increasing popularity on social media platforms. While LLM agents are reshaping the ecology of social media, there exists a current gap in conducting a comprehensive evaluation of their ability to comprehend media content, understand user behaviors, and make intricate decisions. To address this challenge, we introduce SoMe, a pioneering benchmark designed to evaluate social media agents equipped with various agent tools for accessing and analyzing social media data. SoMe comprises a diverse collection of 8 social media agent tasks, 9,164,284 posts, 6,591 user profiles, and 25,686 reports from various social media platforms and external websites, with 17,869 meticulously annotated task queries. Compared with the existing datasets and benchmarks for social media tasks, SoMe is the first to provide a versatile and realistic platform for LLM-based social media agents to handle diverse social media tasks. By extensive quantitative and qualitative analysis, we provide the first overview insight into the performance of mainstream agentic LLMs in realistic social media environments and identify several limitations. Our evaluation reveals that both the current closed-source and open-source LLMs cannot handle social media agent tasks satisfactorily. SoMe provides a challenging yet meaningful testbed for future social media agents. Our code and data are available at https://github.com/LivXue/SoMe
PathBench: A comprehensive comparison benchmark for pathology foundation models towards precision oncology
May 26, 2025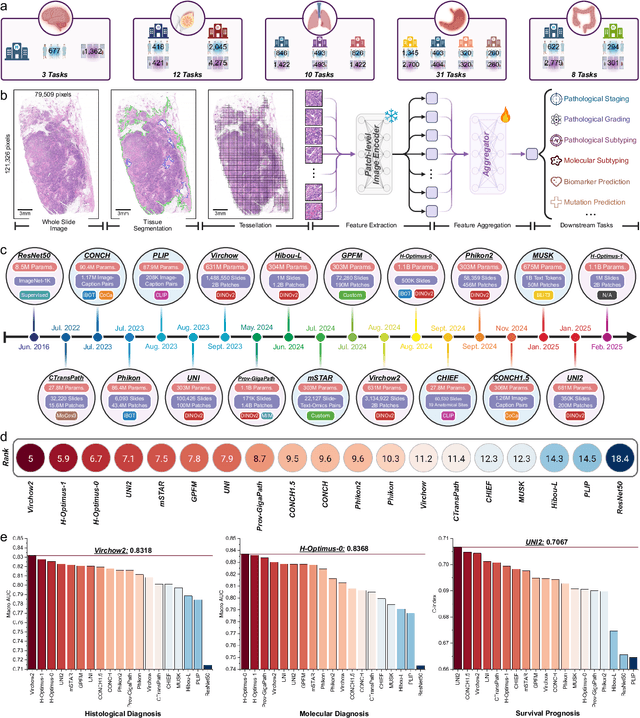



The emergence of pathology foundation models has revolutionized computational histopathology, enabling highly accurate, generalized whole-slide image analysis for improved cancer diagnosis, and prognosis assessment. While these models show remarkable potential across cancer diagnostics and prognostics, their clinical translation faces critical challenges including variability in optimal model across cancer types, potential data leakage in evaluation, and lack of standardized benchmarks. Without rigorous, unbiased evaluation, even the most advanced PFMs risk remaining confined to research settings, delaying their life-saving applications. Existing benchmarking efforts remain limited by narrow cancer-type focus, potential pretraining data overlaps, or incomplete task coverage. We present PathBench, the first comprehensive benchmark addressing these gaps through: multi-center in-hourse datasets spanning common cancers with rigorous leakage prevention, evaluation across the full clinical spectrum from diagnosis to prognosis, and an automated leaderboard system for continuous model assessment. Our framework incorporates large-scale data, enabling objective comparison of PFMs while reflecting real-world clinical complexity. All evaluation data comes from private medical providers, with strict exclusion of any pretraining usage to avoid data leakage risks. We have collected 15,888 WSIs from 8,549 patients across 10 hospitals, encompassing over 64 diagnosis and prognosis tasks. Currently, our evaluation of 19 PFMs shows that Virchow2 and H-Optimus-1 are the most effective models overall. This work provides researchers with a robust platform for model development and offers clinicians actionable insights into PFM performance across diverse clinical scenarios, ultimately accelerating the translation of these transformative technologies into routine pathology practice.
Short-video Propagation Influence Rating: A New Real-world Dataset and A New Large Graph Model
Mar 31, 2025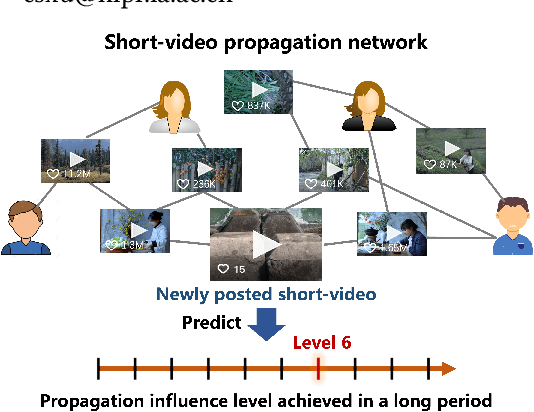


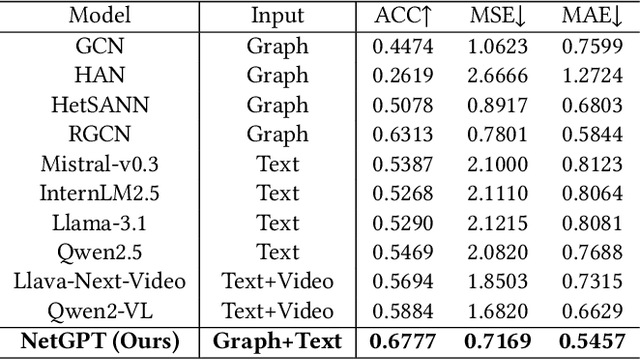
Short-video platforms have gained immense popularity, captivating the interest of millions, if not billions, of users globally. Recently, researchers have highlighted the significance of analyzing the propagation of short-videos, which typically involves discovering commercial values, public opinions, user behaviors, etc. This paper proposes a new Short-video Propagation Influence Rating (SPIR) task and aims to promote SPIR from both the dataset and method perspectives. First, we propose a new Cross-platform Short-Video (XS-Video) dataset, which aims to provide a large-scale and real-world short-video propagation network across various platforms to facilitate the research on short-video propagation. Our XS-Video dataset includes 117,720 videos, 381,926 samples, and 535 topics across 5 biggest Chinese platforms, annotated with the propagation influence from level 0 to 9. To the best of our knowledge, this is the first large-scale short-video dataset that contains cross-platform data or provides all of the views, likes, shares, collects, fans, comments, and comment content. Second, we propose a Large Graph Model (LGM) named NetGPT, based on a novel three-stage training mechanism, to bridge heterogeneous graph-structured data with the powerful reasoning ability and knowledge of Large Language Models (LLMs). Our NetGPT can comprehend and analyze the short-video propagation graph, enabling it to predict the long-term propagation influence of short-videos. Comprehensive experimental results evaluated by both classification and regression metrics on our XS-Video dataset indicate the superiority of our method for SPIR.
Recent Advances in Attack and Defense Approaches of Large Language Models
Sep 05, 2024Large Language Models (LLMs) have revolutionized artificial intelligence and machine learning through their advanced text processing and generating capabilities. However, their widespread deployment has raised significant safety and reliability concerns. Established vulnerabilities in deep neural networks, coupled with emerging threat models, may compromise security evaluations and create a false sense of security. Given the extensive research in the field of LLM security, we believe that summarizing the current state of affairs will help the research community better understand the present landscape and inform future developments. This paper reviews current research on LLM vulnerabilities and threats, and evaluates the effectiveness of contemporary defense mechanisms. We analyze recent studies on attack vectors and model weaknesses, providing insights into attack mechanisms and the evolving threat landscape. We also examine current defense strategies, highlighting their strengths and limitations. By contrasting advancements in attack and defense methodologies, we identify research gaps and propose future directions to enhance LLM security. Our goal is to advance the understanding of LLM safety challenges and guide the development of more robust security measures.
BadRL: Sparse Targeted Backdoor Attack Against Reinforcement Learning
Dec 19, 2023



Backdoor attacks in reinforcement learning (RL) have previously employed intense attack strategies to ensure attack success. However, these methods suffer from high attack costs and increased detectability. In this work, we propose a novel approach, BadRL, which focuses on conducting highly sparse backdoor poisoning efforts during training and testing while maintaining successful attacks. Our algorithm, BadRL, strategically chooses state observations with high attack values to inject triggers during training and testing, thereby reducing the chances of detection. In contrast to the previous methods that utilize sample-agnostic trigger patterns, BadRL dynamically generates distinct trigger patterns based on targeted state observations, thereby enhancing its effectiveness. Theoretical analysis shows that the targeted backdoor attack is always viable and remains stealthy under specific assumptions. Empirical results on various classic RL tasks illustrate that BadRL can substantially degrade the performance of a victim agent with minimal poisoning efforts 0.003% of total training steps) during training and infrequent attacks during testing.