 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting
Jan 05, 2026Supervised Fine-Tuning (SFT) is the standard paradigm for domain adaptation, yet it frequently incurs the cost of catastrophic forgetting. In sharp contrast, on-policy Reinforcement Learning (RL) effectively preserves general capabilities. We investigate this discrepancy and identify a fundamental distributional gap: while RL aligns with the model's internal belief, SFT forces the model to fit external supervision. This mismatch often manifests as "Confident Conflicts" tokens characterized by low probability but low entropy. In these instances, the model is highly confident in its own prediction but is forced to learn a divergent ground truth, triggering destructive gradient updates. To address this, we propose Entropy-Adaptive Fine-Tuning (EAFT). Unlike methods relying solely on prediction probability, EAFT utilizes token-level entropy as a gating mechanism to distinguish between epistemic uncertainty and knowledge conflict. This allows the model to learn from uncertain samples while suppressing gradients on conflicting data. Extensive experiments on Qwen and GLM series (ranging from 4B to 32B parameters) across mathematical, medical, and agentic domains confirm our hypothesis. EAFT consistently matches the downstream performance of standard SFT while significantly mitigating the degradation of general capabilities.
From Risk to Resilience: Towards Assessing and Mitigating the Risk of Data Reconstruction Attacks in Federated Learning
Dec 17, 2025Data Reconstruction Attacks (DRA) pose a significant threat to Federated Learning (FL) systems by enabling adversaries to infer sensitive training data from local clients. Despite extensive research, the question of how to characterize and assess the risk of DRAs in FL systems remains unresolved due to the lack of a theoretically-grounded risk quantification framework. In this work, we address this gap by introducing Invertibility Loss (InvLoss) to quantify the maximum achievable effectiveness of DRAs for a given data instance and FL model. We derive a tight and computable upper bound for InvLoss and explore its implications from three perspectives. First, we show that DRA risk is governed by the spectral properties of the Jacobian matrix of exchanged model updates or feature embeddings, providing a unified explanation for the effectiveness of defense methods. Second, we develop InvRE, an InvLoss-based DRA risk estimator that offers attack method-agnostic, comprehensive risk evaluation across data instances and model architectures. Third, we propose two adaptive noise perturbation defenses that enhance FL privacy without harming classification accuracy. Extensive experiments on real-world datasets validate our framework, demonstrating its potential for systematic DRA risk evaluation and mitigation in FL systems.
Persistent Backdoor Attacks under Continual Fine-Tuning of LLMs
Dec 12, 2025Backdoor attacks embed malicious behaviors into Large Language Models (LLMs), enabling adversaries to trigger harmful outputs or bypass safety controls. However, the persistence of the implanted backdoors under user-driven post-deployment continual fine-tuning has been rarely examined. Most prior works evaluate the effectiveness and generalization of implanted backdoors only at releasing and empirical evidence shows that naively injected backdoor persistence degrades after updates. In this work, we study whether and how implanted backdoors persist through a multi-stage post-deployment fine-tuning. We propose P-Trojan, a trigger-based attack algorithm that explicitly optimizes for backdoor persistence across repeated updates. By aligning poisoned gradients with those of clean tasks on token embeddings, the implanted backdoor mapping is less likely to be suppressed or forgotten during subsequent updates. Theoretical analysis shows the feasibility of such persistent backdoor attacks after continual fine-tuning. And experiments conducted on the Qwen2.5 and LLaMA3 families of LLMs, as well as diverse task sequences, demonstrate that P-Trojan achieves over 99% persistence while preserving clean-task accuracy. Our findings highlight the need for persistence-aware evaluation and stronger defenses in realistic model adaptation pipelines.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
Trust Under Siege: Label Spoofing Attacks against Machine Learning for Android Malware Detection
Mar 14, 2025Machine learning (ML) malware detectors rely heavily on crowd-sourced AntiVirus (AV) labels, with platforms like VirusTotal serving as a trusted source of malware annotations. But what if attackers could manipulate these labels to classify benign software as malicious? We introduce label spoofing attacks, a new threat that contaminates crowd-sourced datasets by embedding minimal and undetectable malicious patterns into benign samples. These patterns coerce AV engines into misclassifying legitimate files as harmful, enabling poisoning attacks against ML-based malware classifiers trained on those data. We demonstrate this scenario by developing AndroVenom, a methodology for polluting realistic data sources, causing consequent poisoning attacks against ML malware detectors. Experiments show that not only state-of-the-art feature extractors are unable to filter such injection, but also various ML models experience Denial of Service already with 1% poisoned samples. Additionally, attackers can flip decisions of specific unaltered benign samples by modifying only 0.015% of the training data, threatening their reputation and market share and being unable to be stopped by anomaly detectors on training data. We conclude our manuscript by raising the alarm on the trustworthiness of the training process based on AV annotations, requiring further investigation on how to produce proper labels for ML malware detectors.
NeRSP: Neural 3D Reconstruction for Reflective Objects with Sparse Polarized Images
Jun 11, 2024
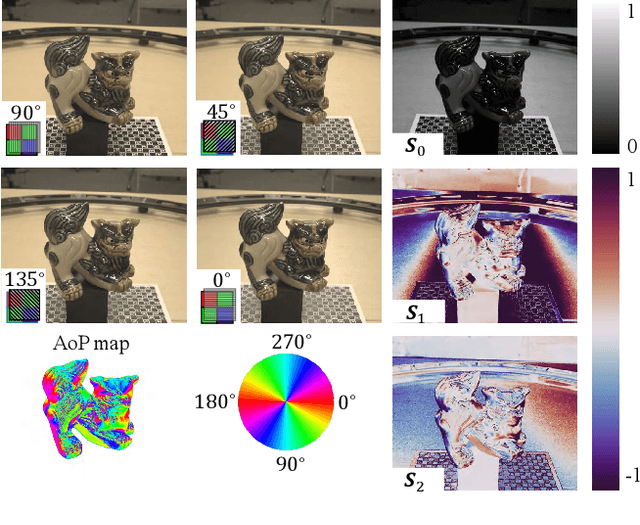
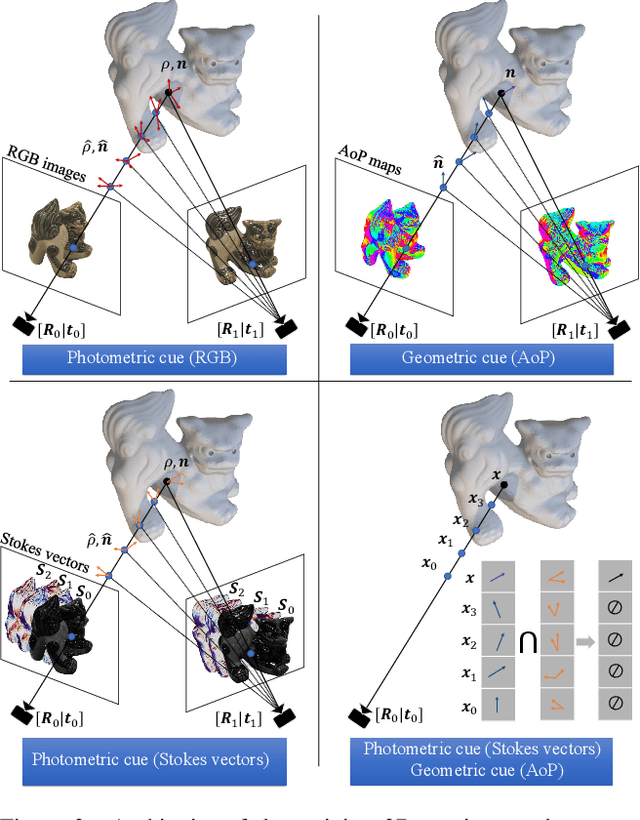
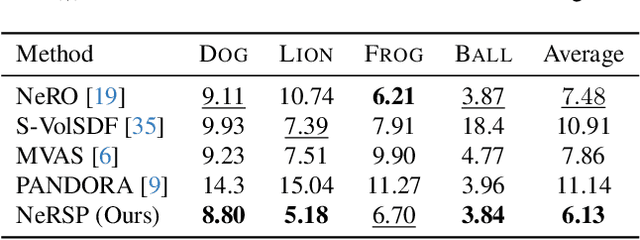
We present NeRSP, a Neural 3D reconstruction technique for Reflective surfaces with Sparse Polarized images. Reflective surface reconstruction is extremely challenging as specular reflections are view-dependent and thus violate the multiview consistency for multiview stereo. On the other hand, sparse image inputs, as a practical capture setting, commonly cause incomplete or distorted results due to the lack of correspondence matching. This paper jointly handles the challenges from sparse inputs and reflective surfaces by leveraging polarized images. We derive photometric and geometric cues from the polarimetric image formation model and multiview azimuth consistency, which jointly optimize the surface geometry modeled via implicit neural representation. Based on the experiments on our synthetic and real datasets, we achieve the state-of-the-art surface reconstruction results with only 6 views as input.
Lurking in the shadows: Unveiling Stealthy Backdoor Attacks against Personalized Federated Learning
Jun 10, 2024



Federated Learning (FL) is a collaborative machine learning technique where multiple clients work together with a central server to train a global model without sharing their private data. However, the distribution shift across non-IID datasets of clients poses a challenge to this one-model-fits-all method hindering the ability of the global model to effectively adapt to each client's unique local data. To echo this challenge, personalized FL (PFL) is designed to allow each client to create personalized local models tailored to their private data. While extensive research has scrutinized backdoor risks in FL, it has remained underexplored in PFL applications. In this study, we delve deep into the vulnerabilities of PFL to backdoor attacks. Our analysis showcases a tale of two cities. On the one hand, the personalization process in PFL can dilute the backdoor poisoning effects injected into the personalized local models. Furthermore, PFL systems can also deploy both server-end and client-end defense mechanisms to strengthen the barrier against backdoor attacks. On the other hand, our study shows that PFL fortified with these defense methods may offer a false sense of security. We propose \textit{PFedBA}, a stealthy and effective backdoor attack strategy applicable to PFL systems. \textit{PFedBA} ingeniously aligns the backdoor learning task with the main learning task of PFL by optimizing the trigger generation process. Our comprehensive experiments demonstrate the effectiveness of \textit{PFedBA} in seamlessly embedding triggers into personalized local models. \textit{PFedBA} yields outstanding attack performance across 10 state-of-the-art PFL algorithms, defeating the existing 6 defense mechanisms. Our study sheds light on the subtle yet potent backdoor threats to PFL systems, urging the community to bolster defenses against emerging backdoor challenges.
Cross-Context Backdoor Attacks against Graph Prompt Learning
May 28, 2024



Graph Prompt Learning (GPL) bridges significant disparities between pretraining and downstream applications to alleviate the knowledge transfer bottleneck in real-world graph learning. While GPL offers superior effectiveness in graph knowledge transfer and computational efficiency, the security risks posed by backdoor poisoning effects embedded in pretrained models remain largely unexplored. Our study provides a comprehensive analysis of GPL's vulnerability to backdoor attacks. We introduce \textit{CrossBA}, the first cross-context backdoor attack against GPL, which manipulates only the pretraining phase without requiring knowledge of downstream applications. Our investigation reveals both theoretically and empirically that tuning trigger graphs, combined with prompt transformations, can seamlessly transfer the backdoor threat from pretrained encoders to downstream applications. Through extensive experiments involving 3 representative GPL methods across 5 distinct cross-context scenarios and 5 benchmark datasets of node and graph classification tasks, we demonstrate that \textit{CrossBA} consistently achieves high attack success rates while preserving the functionality of downstream applications over clean input. We also explore potential countermeasures against \textit{CrossBA} and conclude that current defenses are insufficient to mitigate \textit{CrossBA}. Our study highlights the persistent backdoor threats to GPL systems, raising trustworthiness concerns in the practices of GPL techniques.
Defending Jailbreak Prompts via In-Context Adversarial Game
Feb 20, 2024
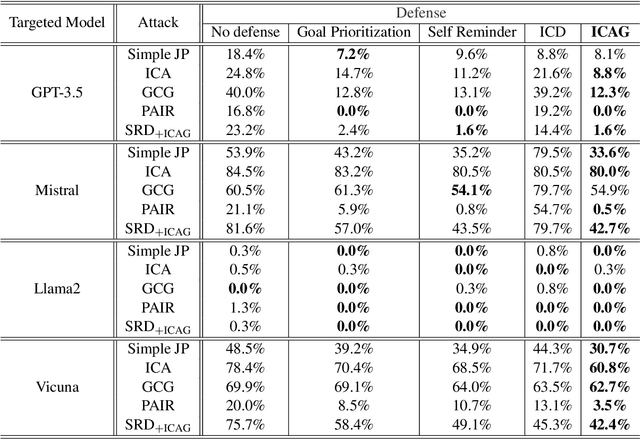

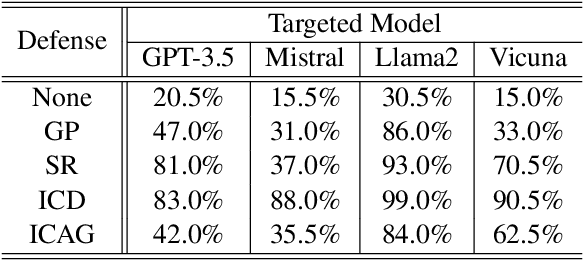
Large Language Models (LLMs) demonstrate remarkable capabilities across diverse applications. However, concerns regarding their security, particularly the vulnerability to jailbreak attacks, persist. Drawing inspiration from adversarial training in deep learning and LLM agent learning processes, we introduce the In-Context Adversarial Game (ICAG) for defending against jailbreaks without the need for fine-tuning. ICAG leverages agent learning to conduct an adversarial game, aiming to dynamically extend knowledge to defend against jailbreaks. Unlike traditional methods that rely on static datasets, ICAG employs an iterative process to enhance both the defense and attack agents. This continuous improvement process strengthens defenses against newly generated jailbreak prompts. Our empirical studies affirm ICAG's efficacy, where LLMs safeguarded by ICAG exhibit significantly reduced jailbreak success rates across various attack scenarios. Moreover, ICAG demonstrates remarkable transferability to other LLMs, indicating its potential as a versatile defense mechanism.
Manipulating Predictions over Discrete Inputs in Machine Teaching
Jan 31, 2024Machine teaching often involves the creation of an optimal (typically minimal) dataset to help a model (referred to as the `student') achieve specific goals given by a teacher. While abundant in the continuous domain, the studies on the effectiveness of machine teaching in the discrete domain are relatively limited. This paper focuses on machine teaching in the discrete domain, specifically on manipulating student models' predictions based on the goals of teachers via changing the training data efficiently. We formulate this task as a combinatorial optimization problem and solve it by proposing an iterative searching algorithm. Our algorithm demonstrates significant numerical merit in the scenarios where a teacher attempts at correcting erroneous predictions to improve the student's models, or maliciously manipulating the model to misclassify some specific samples to the target class aligned with his personal profits. Experimental results show that our proposed algorithm can have superior performance in effectively and efficiently manipulating the predictions of the model, surpassing conventional baselines.