 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefixAgent: An LLM-Powered Design Framework for Efficient Prefix Adder Optimization
Jul 08, 2025Prefix adders are fundamental arithmetic circuits, but their design space grows exponentially with bit-width, posing significant optimization challenges. Previous works face limitations in performance, generalization, and scalability. To address these challenges, we propose PrefixAgent, a large language model (LLM)-powered framework that enables efficient prefix adder optimization. Specifically, PrefixAgent reformulates the problem into subtasks including backbone synthesis and structure refinement, which effectively reduces the search space. More importantly, this new design perspective enables us to efficiently collect enormous high-quality data and reasoning traces with E-graph, which further results in an effective fine-tuning of LLM. Experimental results show that PrefixAgent synthesizes prefix adders with consistently smaller areas compared to baseline methods, while maintaining scalability and generalization in commercial EDA flows.
PICBench: Benchmarking LLMs for Photonic Integrated Circuits Design
Feb 05, 2025While large language models (LLMs) have shown remarkable potential in automating various tasks in digital chip design, the field of Photonic Integrated Circuits (PICs)-a promising solution to advanced chip designs-remains relatively unexplored in this context. The design of PICs is time-consuming and prone to errors due to the extensive and repetitive nature of code involved in photonic chip design. In this paper, we introduce PICBench, the first benchmarking and evaluation framework specifically designed to automate PIC design generation using LLMs, where the generated output takes the form of a netlist. Our benchmark consists of dozens of meticulously crafted PIC design problems, spanning from fundamental device designs to more complex circuit-level designs. It automatically evaluates both the syntax and functionality of generated PIC designs by comparing simulation outputs with expert-written solutions, leveraging an open-source simulator. We evaluate a range of existing LLMs, while also conducting comparative tests on various prompt engineering techniques to enhance LLM performance in automated PIC design. The results reveal the challenges and potential of LLMs in the PIC design domain, offering insights into the key areas that require further research and development to optimize automation in this field. Our benchmark and evaluation code is available at https://github.com/PICDA/PICBench.
CAMO: Correlation-Aware Mask Optimization with Modulated Reinforcement Learning
Apr 01, 2024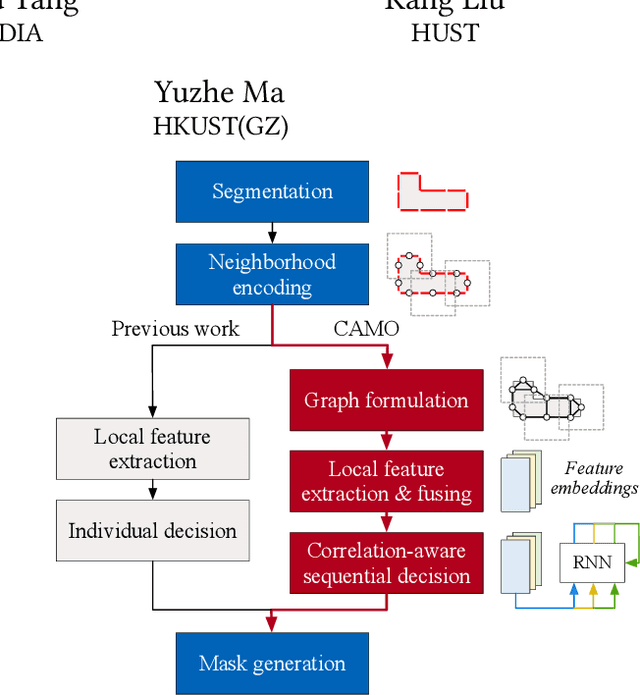
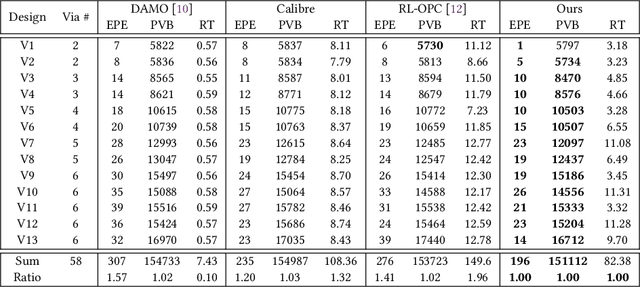
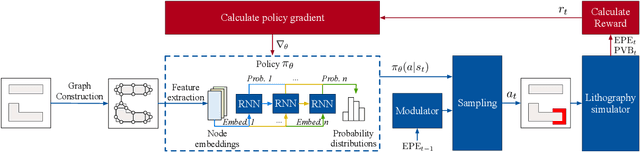
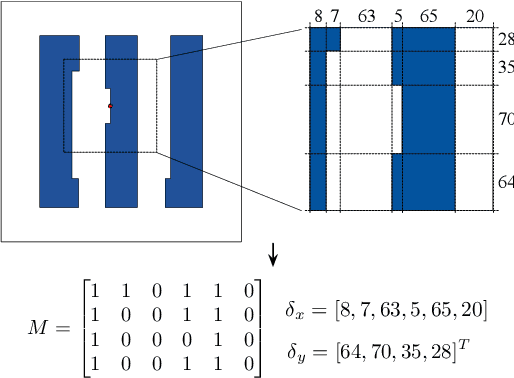
Optical proximity correction (OPC) is a vital step to ensure printability in modern VLSI manufacturing. Various OPC approaches based on machine learning have been proposed to pursue performance and efficiency, which are typically data-driven and hardly involve any particular considerations of the OPC problem, leading to potential performance or efficiency bottlenecks. In this paper, we propose CAMO, a reinforcement learning-based OPC system that specifically integrates important principles of the OPC problem. CAMO explicitly involves the spatial correlation among the movements of neighboring segments and an OPC-inspired modulation for movement action selection. Experiments are conducted on both via layer patterns and metal layer patterns. The results demonstrate that CAMO outperforms state-of-the-art OPC engines from both academia and industry.
RL-MUL: Multiplier Design Optimization with Deep Reinforcement Learning
Mar 31, 2024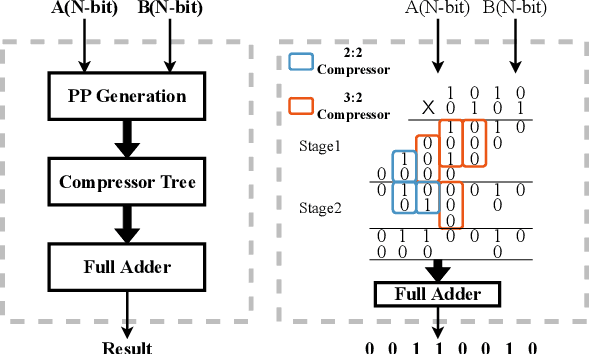
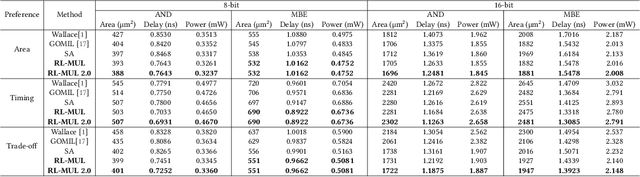
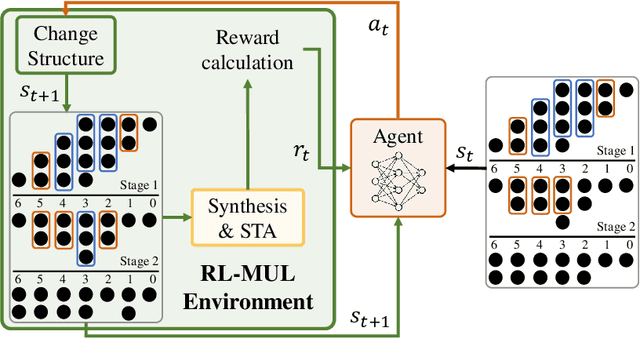

Multiplication is a fundamental operation in many applications, and multipliers are widely adopted in various circuits. However, optimizing multipliers is challenging and non-trivial due to the huge design space. In this paper, we propose RL-MUL, a multiplier design optimization framework based on reinforcement learning. Specifically, we utilize matrix and tensor representations for the compressor tree of a multiplier, based on which the convolutional neural networks can be seamlessly incorporated as the agent network. The agent can learn to optimize the multiplier structure based on a Pareto-driven reward which is customized to accommodate the trade-off between area and delay. Additionally, the capability of RL-MUL is extended to optimize the fused multiply-accumulator (MAC) designs. Experiments are conducted on different bit widths of multipliers. The results demonstrate that the multipliers produced by RL-MUL can dominate all baseline designs in terms of area and delay. The performance gain of RL-MUL is further validated by comparing the area and delay of processing element arrays using multipliers from RL-MUL and baseline approaches.
BadRL: Sparse Targeted Backdoor Attack Against Reinforcement Learning
Dec 19, 2023



Backdoor attacks in reinforcement learning (RL) have previously employed intense attack strategies to ensure attack success. However, these methods suffer from high attack costs and increased detectability. In this work, we propose a novel approach, BadRL, which focuses on conducting highly sparse backdoor poisoning efforts during training and testing while maintaining successful attacks. Our algorithm, BadRL, strategically chooses state observations with high attack values to inject triggers during training and testing, thereby reducing the chances of detection. In contrast to the previous methods that utilize sample-agnostic trigger patterns, BadRL dynamically generates distinct trigger patterns based on targeted state observations, thereby enhancing its effectiveness. Theoretical analysis shows that the targeted backdoor attack is always viable and remains stealthy under specific assumptions. Empirical results on various classic RL tasks illustrate that BadRL can substantially degrade the performance of a victim agent with minimal poisoning efforts 0.003% of total training steps) during training and infrequent attacks during testing.
Physics-Informed Optical Kernel Regression Using Complex-valued Neural Fields
Apr 02, 2023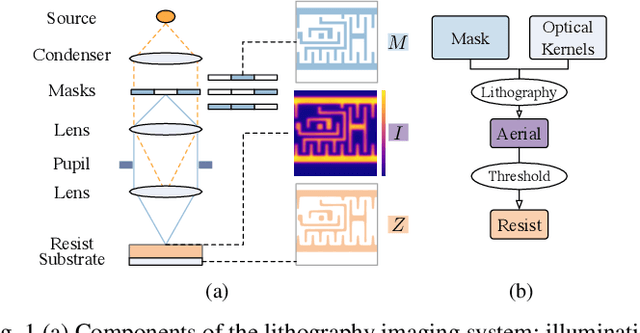
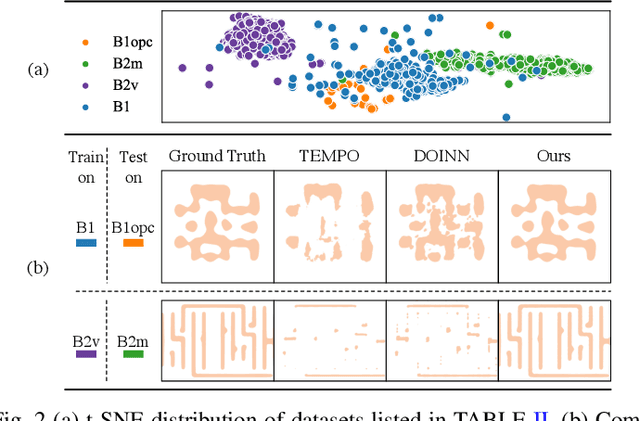
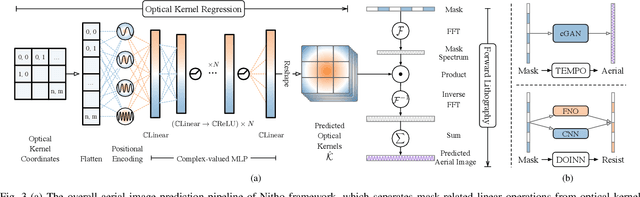
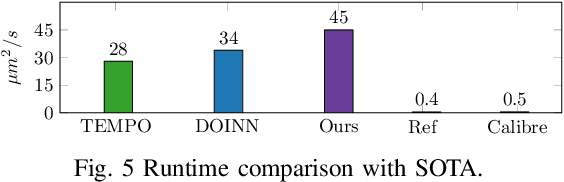
Lithography is fundamental to integrated circuit fabrication, necessitating large computation overhead. The advancement of machine learning (ML)-based lithography models alleviates the trade-offs between manufacturing process expense and capability. However, all previous methods regard the lithography system as an image-to-image black box mapping, utilizing network parameters to learn by rote mappings from massive mask-to-aerial or mask-to-resist image pairs, resulting in poor generalization capability. In this paper, we propose a new ML-based paradigm disassembling the rigorous lithographic model into non-parametric mask operations and learned optical kernels containing determinant source, pupil, and lithography information. By optimizing complex-valued neural fields to perform optical kernel regression from coordinates, our method can accurately restore lithography system using a small-scale training dataset with fewer parameters, demonstrating superior generalization capability as well. Experiments show that our framework can use 31% of parameters while achieving 69$\times$ smaller mean squared error with 1.3$\times$ higher throughput than the state-of-the-art.
DevelSet: Deep Neural Level Set for Instant Mask Optimization
Mar 18, 2023With the feature size continuously shrinking in advanced technology nodes, mask optimization is increasingly crucial in the conventional design flow, accompanied by an explosive growth in prohibitive computational overhead in optical proximity correction (OPC) methods. Recently, inverse lithography technique (ILT) has drawn significant attention and is becoming prevalent in emerging OPC solutions. However, ILT methods are either time-consuming or in weak performance of mask printability and manufacturability. In this paper, we present DevelSet, a GPU and deep neural network (DNN) accelerated level set OPC framework for metal layer. We first improve the conventional level set-based ILT algorithm by introducing the curvature term to reduce mask complexity and applying GPU acceleration to overcome computational bottlenecks. To further enhance printability and fast iterative convergence, we propose a novel deep neural network delicately designed with level set intrinsic principles to facilitate the joint optimization of DNN and GPU accelerated level set optimizer. Experimental results show that DevelSet framework surpasses the state-of-the-art methods in printability and boost the runtime performance achieving instant level (around 1 second).
AdaOPC: A Self-Adaptive Mask Optimization Framework For Real Design Patterns
Mar 15, 2023Optical proximity correction (OPC) is a widely-used resolution enhancement technique (RET) for printability optimization. Recently, rigorous numerical optimization and fast machine learning are the research focus of OPC in both academia and industry, each of which complements the other in terms of robustness or efficiency. We inspect the pattern distribution on a design layer and find that different sub-regions have different pattern complexity. Besides, we also find that many patterns repetitively appear in the design layout, and these patterns may possibly share optimized masks. We exploit these properties and propose a self-adaptive OPC framework to improve efficiency. Firstly we choose different OPC solvers adaptively for patterns of different complexity from an extensible solver pool to reach a speed/accuracy co-optimization. Apart from that, we prove the feasibility of reusing optimized masks for repeated patterns and hence, build a graph-based dynamic pattern library reusing stored masks to further speed up the OPC flow. Experimental results show that our framework achieves substantial improvement in both performance and efficiency.
Adversarial Attacks on Adversarial Bandits
Jan 30, 2023

We study a security threat to adversarial multi-armed bandits, in which an attacker perturbs the loss or reward signal to control the behavior of the victim bandit player. We show that the attacker is able to mislead any no-regret adversarial bandit algorithm into selecting a suboptimal target arm in every but sublinear (T-o(T)) number of rounds, while incurring only sublinear (o(T)) cumulative attack cost. This result implies critical security concern in real-world bandit-based systems, e.g., in online recommendation, an attacker might be able to hijack the recommender system and promote a desired product. Our proposed attack algorithms require knowledge of only the regret rate, thus are agnostic to the concrete bandit algorithm employed by the victim player. We also derived a theoretical lower bound on the cumulative attack cost that any victim-agnostic attack algorithm must incur. The lower bound matches the upper bound achieved by our attack, which shows that our attack is asymptotically optimal.
Rethinking Graph Neural Networks for the Graph Coloring Problem
Aug 19, 2022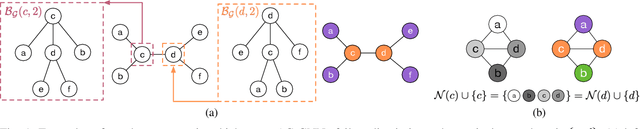
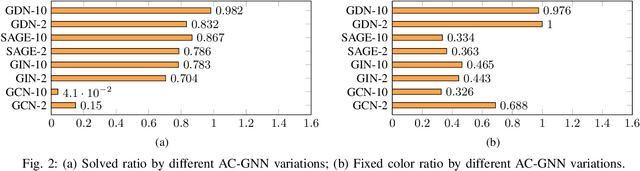

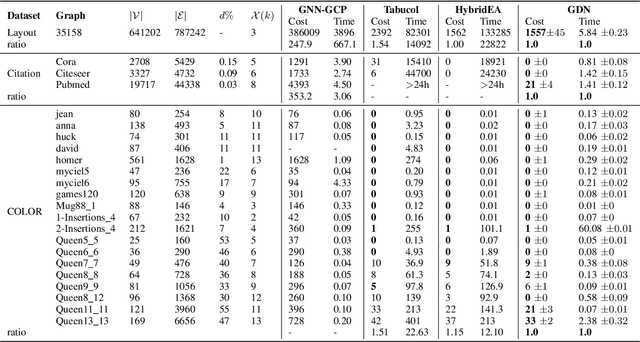
Graph coloring, a classical and critical NP-hard problem, is the problem of assigning connected nodes as different colors as possible. However, we observe that state-of-the-art GNNs are less successful in the graph coloring problem. We analyze the reasons from two perspectives. First, most GNNs fail to generalize the task under homophily to heterophily, i.e., graphs where connected nodes are assigned different colors. Second, GNNs are bounded by the network depth, making them possible to be a local method, which has been demonstrated to be non-optimal in Maximum Independent Set (MIS) problem. In this paper, we focus on the aggregation-combine GNNs (AC-GNNs), a popular class of GNNs. We first define the power of AC-GNNs in the coloring problem as the capability to assign nodes different colors. The definition is different with previous one that is based on the assumption of homophily. We identify node pairs that AC-GNNs fail to discriminate. Furthermore, we show that any AC-GNN is a local coloring method, and any local coloring method is non-optimal by exploring the limits of local methods over sparse random graphs, thereby demonstrating the non-optimality of AC-GNNs due to its local property. We then prove the positive correlation between model depth and its coloring power. Moreover, we discuss the color equivariance of graphs to tackle some practical constraints such as the pre-fixing constraints. Following the discussions above, we summarize a series of rules a series of rules that make a GNN color equivariant and powerful in the coloring problem. Then, we propose a simple AC-GNN variation satisfying these rules. We empirically validate our theoretical findings and demonstrate that our simple model substantially outperforms state-of-the-art heuristic algorithms in both quality and runtime.