 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemDLM: Memory-Enhanced DLM Training
Mar 23, 2026Diffusion Language Models (DLMs) offer attractive advantages over Auto-Regressive (AR) models, such as full-attention parallel decoding and flexible generation. However, they suffer from a notable train-inference mismatch: DLMs are trained with a static, single-step masked prediction objective, but deployed through a multi-step progressive denoising trajectory. We propose MemDLM (Memory-Enhanced DLM), which narrows this gap by embedding a simulated denoising process into training via Bi-level Optimization. An inner loop updates a set of fast weights, forming a Parametric Memory that captures the local trajectory experience of each sample, while an outer loop updates the base model conditioned on this memory. By offloading memorization pressure from token representations to parameters, MemDLM yields faster convergence and lower training loss. Moreover, the inner loop can be re-enabled at inference time as an adaptation step, yielding additional gains on long-context understanding. We find that, when activated at inference time, this Parametric Memory acts as an emergent in-weight retrieval mechanism, helping MemDLM further reduce token-level attention bottlenecks on challenging Needle-in-a-Haystack retrieval tasks. Code: https://github.com/JarvisPei/MemDLM.
ReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
SCOPE: Prompt Evolution for Enhancing Agent Effectiveness
Dec 17, 2025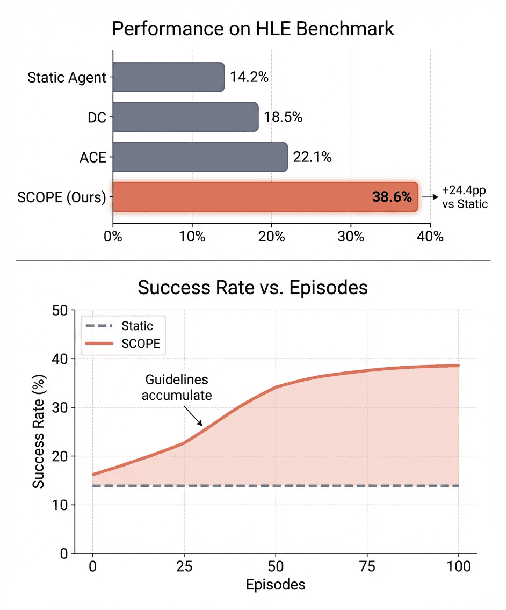
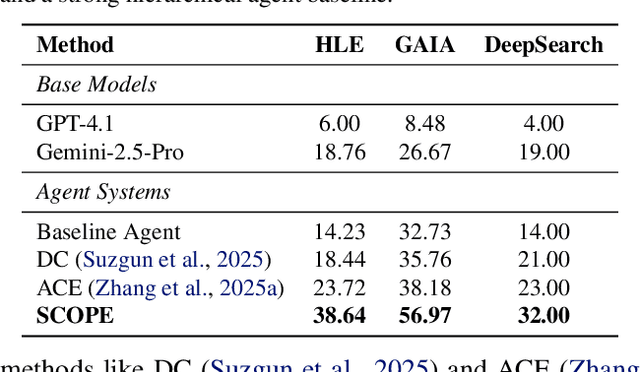
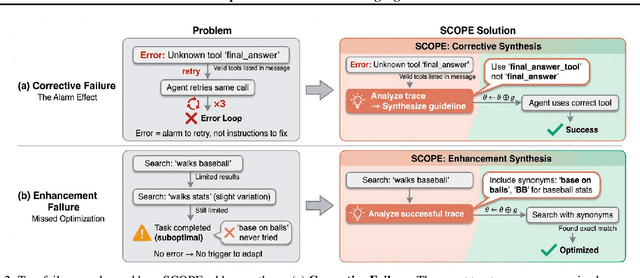
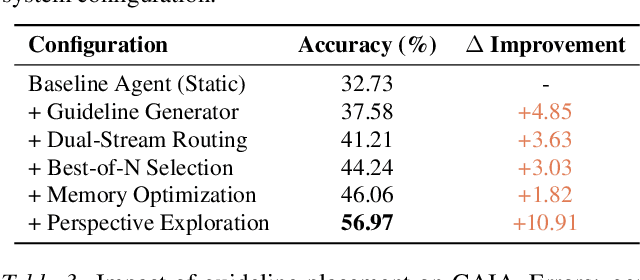
Large Language Model (LLM) agents are increasingly deployed in environments that generate massive, dynamic contexts. However, a critical bottleneck remains: while agents have access to this context, their static prompts lack the mechanisms to manage it effectively, leading to recurring Corrective and Enhancement failures. To address this capability gap, we introduce \textbf{SCOPE} (Self-evolving Context Optimization via Prompt Evolution). SCOPE frames context management as an \textit{online optimization} problem, synthesizing guidelines from execution traces to automatically evolve the agent's prompt. We propose a Dual-Stream mechanism that balances tactical specificity (resolving immediate errors) with strategic generality (evolving long-term principles). Furthermore, we introduce Perspective-Driven Exploration to maximize strategy coverage, increasing the likelihood that the agent has the correct strategy for any given task. Experiments on the HLE benchmark show that SCOPE improves task success rates from 14.23\% to 38.64\% without human intervention. We make our code publicly available at https://github.com/JarvisPei/SCOPE.
PreMoe: Lightening MoEs on Constrained Memory by Expert Pruning and Retrieval
May 23, 2025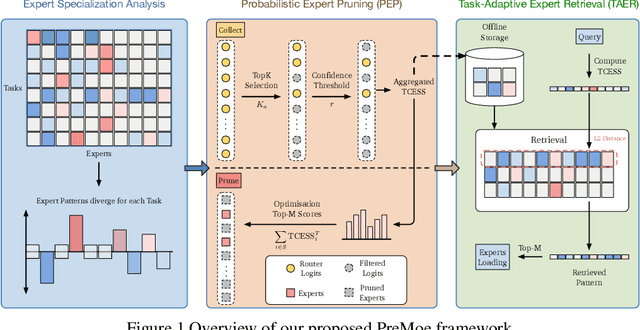
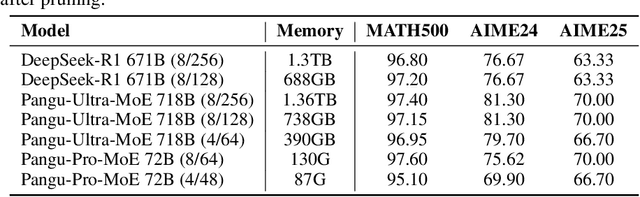
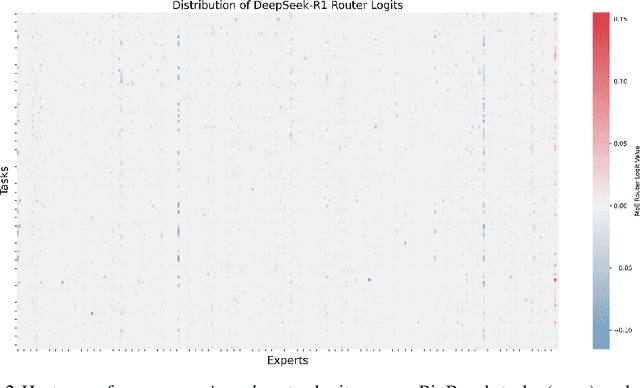
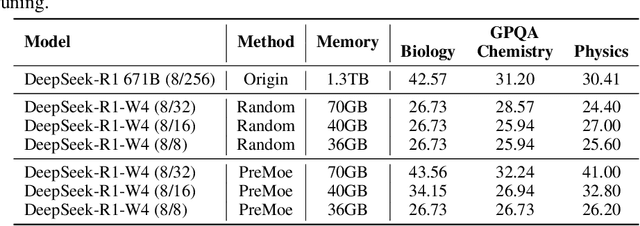
Mixture-of-experts (MoE) architectures enable scaling large language models (LLMs) to vast parameter counts without a proportional rise in computational costs. However, the significant memory demands of large MoE models hinder their deployment across various computational environments, from cloud servers to consumer devices. This study first demonstrates pronounced task-specific specialization in expert activation patterns within MoE layers. Building on this, we introduce PreMoe, a novel framework that enables efficient deployment of massive MoE models in memory-constrained environments. PreMoe features two main components: probabilistic expert pruning (PEP) and task-adaptive expert retrieval (TAER). PEP employs a new metric, the task-conditioned expected selection score (TCESS), derived from router logits to quantify expert importance for specific tasks, thereby identifying a minimal set of critical experts. TAER leverages these task-specific expert importance profiles for efficient inference. It pre-computes and stores compact expert patterns for diverse tasks. When a user query is received, TAER rapidly identifies the most relevant stored task pattern and reconstructs the model by loading only the small subset of experts crucial for that task. This approach dramatically reduces the memory footprint across all deployment scenarios. DeepSeek-R1 671B maintains 97.2\% accuracy on MATH500 when pruned to 8/128 configuration (50\% expert reduction), and still achieves 72.0\% with aggressive 8/32 pruning (87.5\% expert reduction). Pangu-Ultra-MoE 718B achieves 97.15\% on MATH500 and 81.3\% on AIME24 with 8/128 pruning, while even more aggressive pruning to 4/64 (390GB memory) preserves 96.95\% accuracy on MATH500. We make our code publicly available at https://github.com/JarvisPei/PreMoe.
CMoE: Fast Carving of Mixture-of-Experts for Efficient LLM Inference
Feb 06, 2025



Large language models (LLMs) achieve impressive performance by scaling model parameters, but this comes with significant inference overhead. Feed-forward networks (FFNs), which dominate LLM parameters, exhibit high activation sparsity in hidden neurons. To exploit this, researchers have proposed using a mixture-of-experts (MoE) architecture, where only a subset of parameters is activated. However, existing approaches often require extensive training data and resources, limiting their practicality. We propose CMoE (Carved MoE), a novel framework to efficiently carve MoE models from dense models. CMoE achieves remarkable performance through efficient expert grouping and lightweight adaptation. First, neurons are grouped into shared and routed experts based on activation rates. Next, we construct a routing mechanism without training from scratch, incorporating a differentiable routing process and load balancing. Using modest data, CMoE produces a well-designed, usable MoE from a 7B dense model within five minutes. With lightweight fine-tuning, it achieves high-performance recovery in under an hour. We make our code publicly available at https://github.com/JarvisPei/CMoE.
FuseGPT: Learnable Layers Fusion of Generative Pre-trained Transformers
Nov 21, 2024



Generative Pre-trained Transformers (GPTs) have demonstrated remarkable performance across diverse domains through the extensive scaling of model parameters. Recent works observe the redundancy across the transformer blocks and develop compression methods by structured pruning of the unimportant blocks. However, such straightforward elimination will always provide irreversible performance degradation. In this paper, we propose FuseGPT, a novel methodology to recycle the pruned transformer blocks to further recover the model performance. Firstly we introduce a new importance detection metric, Macro Influence (MI), to detect the long-term influence of each transformer block by calculating their loss of information after removal. Then we propose group-level layers fusion, which adopts the parameters in layers of the unimportant blocks and injects them into the corresponding layers inside the neighboring blocks. The fusion is not one-off but through iterative parameter updates by lightweight group-level fine-tuning. Specifically, these injected parameters are frozen but weighted with learnable rank decomposition matrices to reduce the overhead during fine-tuning. Our approach not only works well on large language models but also on large multimodal models. The experiments have shown that, by using modest amounts of data, FuseGPT can outperform previous works in both perplexity and zero-shot task performance.
SoLA: Solver-Layer Adaption of LLM for Better Logic Reasoning
Feb 19, 2024



Considering the challenges faced by large language models (LLMs) on logical reasoning, prior efforts have sought to transform problem-solving through tool learning. While progress has been made on small-scale problems, solving industrial cases remains difficult due to their large scale and intricate expressions. In this paper, we propose a novel solver-layer adaptation (SoLA) method, where we introduce a solver as a new layer of the LLM to differentially guide solutions towards satisfiability. In SoLA, LLM aims to comprehend the search space described in natural language and identify local solutions of the highest quality, while the solver layer focuses solely on constraints not satisfied by the initial solution. Leveraging MaxSAT as a bridge, we define forward and backward transfer gradients, enabling the final model to converge to a satisfied solution or prove unsatisfiability. The backdoor theory ensures that SoLA can obtain accurate solutions within polynomial loops. We evaluate the performance of SoLA on various datasets and empirically demonstrate its consistent outperformance against existing symbolic solvers (including Z3 and Kissat) and tool-learning methods in terms of efficiency in large-scale problem-solving.
BetterV: Controlled Verilog Generation with Discriminative Guidance
Feb 03, 2024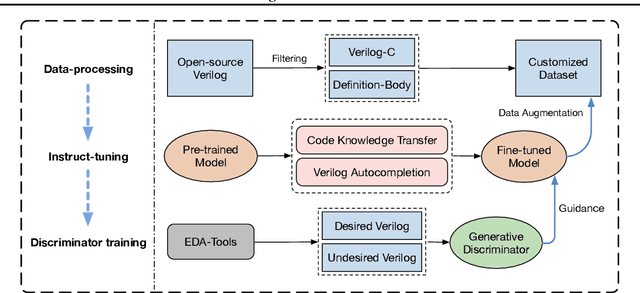
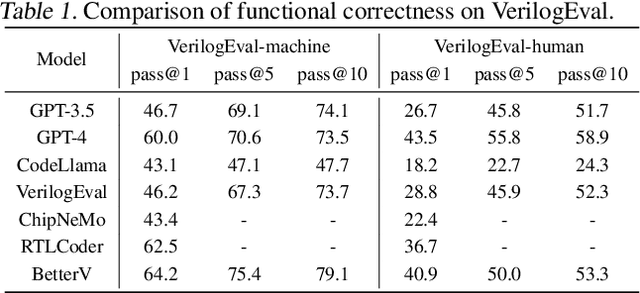

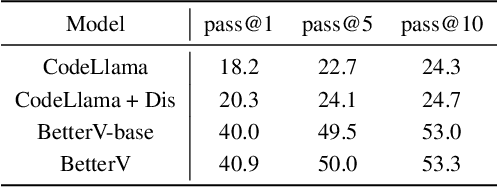
Due to the growing complexity of modern Integrated Circuits (ICs), there is a need for automated circuit design methods. Recent years have seen rising research in hardware design language generation to facilitate the design process. In this work, we propose a Verilog generation framework, BetterV, which fine-tunes the large language models (LLMs) on processed domain-specific datasets and incorporates generative discriminators for guidance on particular design demands. The Verilog modules are collected, filtered and processed from internet to form a clean and abundant dataset. Instruct-tuning methods are specially designed to fine-tuned the LLMs to understand the knowledge about Verilog. Furthermore, data are augmented to enrich the training set and also used to train a generative discriminator on particular downstream task, which leads a guidance for the LLMs to optimize the Verilog implementation. BetterV has the ability to generate syntactically and functionally correct Verilog, which can outperform GPT-4 on the VerilogEval-machine benchmark. With the help of task-specific generative discriminator, BetterV can achieve remarkable improvement on various electronic design automation (EDA) downstream tasks, including the netlist node reduction for synthesis and verification runtime reduction with Boolean Satisfiability (SAT) solving.
Physics-Informed Optical Kernel Regression Using Complex-valued Neural Fields
Apr 02, 2023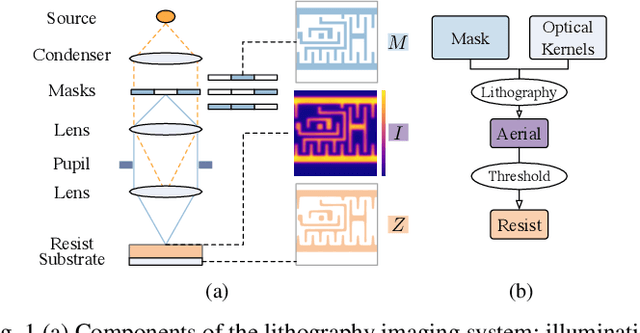
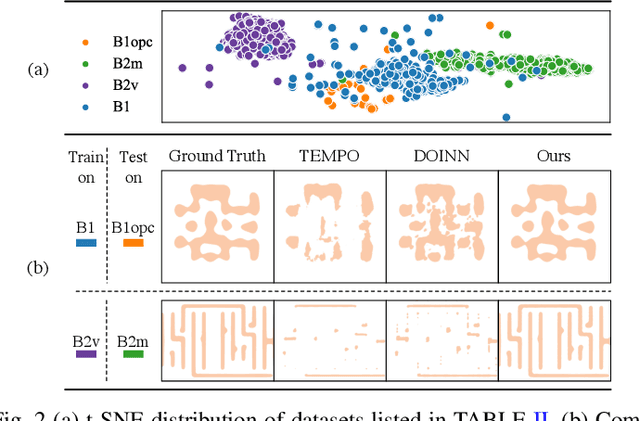
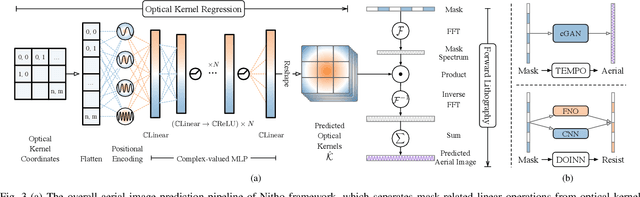
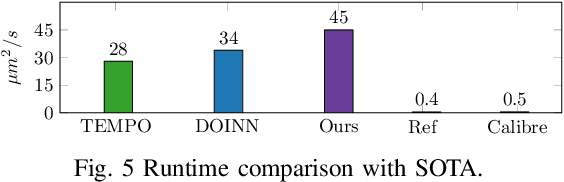
Lithography is fundamental to integrated circuit fabrication, necessitating large computation overhead. The advancement of machine learning (ML)-based lithography models alleviates the trade-offs between manufacturing process expense and capability. However, all previous methods regard the lithography system as an image-to-image black box mapping, utilizing network parameters to learn by rote mappings from massive mask-to-aerial or mask-to-resist image pairs, resulting in poor generalization capability. In this paper, we propose a new ML-based paradigm disassembling the rigorous lithographic model into non-parametric mask operations and learned optical kernels containing determinant source, pupil, and lithography information. By optimizing complex-valued neural fields to perform optical kernel regression from coordinates, our method can accurately restore lithography system using a small-scale training dataset with fewer parameters, demonstrating superior generalization capability as well. Experiments show that our framework can use 31% of parameters while achieving 69$\times$ smaller mean squared error with 1.3$\times$ higher throughput than the state-of-the-art.
From Beginner to Master: A Survey for Deep Learning-based Single-Image Super-Resolution
Sep 29, 2021
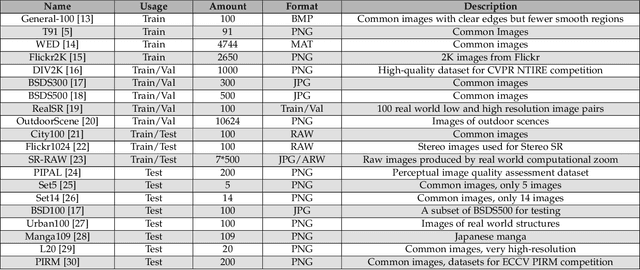
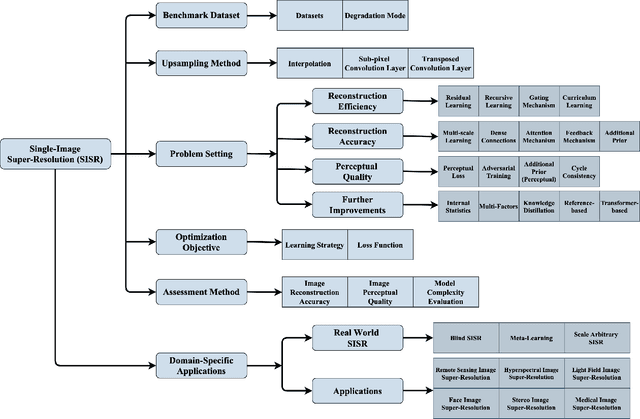
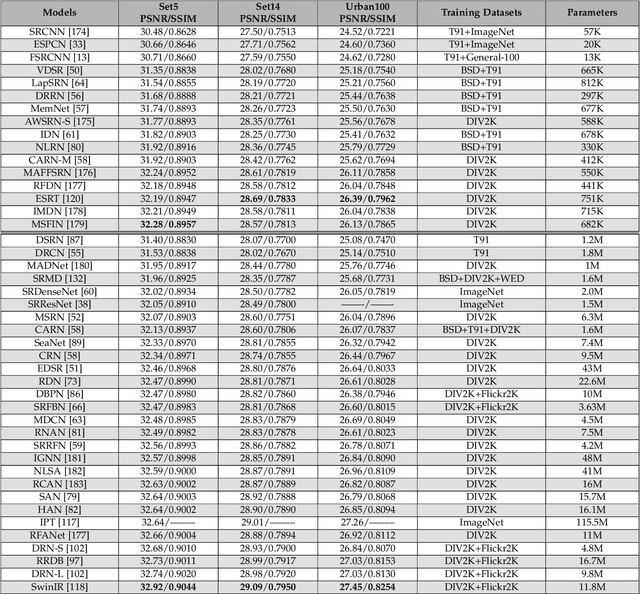
Single-image super-resolution (SISR) is an important task in image processing, which aims to enhance the resolution of imaging systems. Recently, SISR has made a huge leap and has achieved promising results with the help of deep learning (DL). In this survey, we give an overview of DL-based SISR methods and group them according to their targets, such as reconstruction efficiency, reconstruction accuracy, and perceptual accuracy. Specifically, we first introduce the problem definition, research background, and the significance of SISR. Secondly, we introduce some related works, including benchmark datasets, upsampling methods, optimization objectives, and image quality assessment methods. Thirdly, we provide a detailed investigation of SISR and give some domain-specific applications of it. Fourthly, we present the reconstruction results of some classic SISR methods to intuitively know their performance. Finally, we discuss some issues that still exist in SISR and summarize some new trends and future directions. This is an exhaustive survey of SISR, which can help researchers better understand SISR and inspire more exciting research in this field. An investigation project for SISR is provided in https://github.com/CV-JunchengLi/SISR-Survey.