 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
Harnessing On-Device Large Language Model: Empirical Results and Implications for AI PC
May 22, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
Harnessing Large Language Models Locally: Empirical Results and Implications for AI PC
May 21, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
DiffPattern-Flex: Efficient Layout Pattern Generation via Discrete Diffusion
May 07, 2025Recent advancements in layout pattern generation have been dominated by deep generative models. However, relying solely on neural networks for legality guarantees raises concerns in many practical applications. In this paper, we present \tool{DiffPattern}-Flex, a novel approach designed to generate reliable layout patterns efficiently. \tool{DiffPattern}-Flex incorporates a new method for generating diverse topologies using a discrete diffusion model while maintaining a lossless and compute-efficient layout representation. To ensure legal pattern generation, we employ {an} optimization-based, white-box pattern assessment process based on specific design rules. Furthermore, fast sampling and efficient legalization technologies are employed to accelerate the generation process. Experimental results across various benchmarks demonstrate that \tool{DiffPattern}-Flex significantly outperforms existing methods and excels at producing reliable layout patterns.
MoreauPruner: Robust Pruning of Large Language Models against Weight Perturbations
Jun 11, 2024Few-shot gradient methods have been extensively utilized in existing model pruning methods, where the model weights are regarded as static values and the effects of potential weight perturbations are not considered. However, the widely used large language models (LLMs) have several billion model parameters, which could increase the fragility of few-shot gradient pruning. In this work, we experimentally show that one-shot gradient pruning algorithms could lead to unstable results under perturbations to model weights. And the minor error of switching between data formats bfloat16 and float16 could result in drastically different outcomes. To address such instabilities, we leverage optimization analysis and propose an LLM structural pruning method, called MoreauPruner, with provable robustness against weight perturbations. In MoreauPruner, the model weight importance is estimated based on the neural network's Moreau envelope, which can be flexibly combined with $\ell_1$-norm regularization techniques to induce the sparsity required in the pruning task. We extensively evaluate the MoreauPruner algorithm on several well-known LLMs, including LLaMA-7B, LLaMA-13B, LLaMA3-8B, and Vicuna-7B. Our numerical results suggest the robustness of MoreauPruner against weight perturbations, and indicate the MoreauPruner's successful accuracy-based scores in comparison to several existing pruning methods. We have released the code in \url{https://github.com/ShiningSord/MoreauPruner}.
ChatPattern: Layout Pattern Customization via Natural Language
Mar 15, 2024



Existing works focus on fixed-size layout pattern generation, while the more practical free-size pattern generation receives limited attention. In this paper, we propose ChatPattern, a novel Large-Language-Model (LLM) powered framework for flexible pattern customization. ChatPattern utilizes a two-part system featuring an expert LLM agent and a highly controllable layout pattern generator. The LLM agent can interpret natural language requirements and operate design tools to meet specified needs, while the generator excels in conditional layout generation, pattern modification, and memory-friendly patterns extension. Experiments on challenging pattern generation setting shows the ability of ChatPattern to synthesize high-quality large-scale patterns.
Local Structure-aware Graph Contrastive Representation Learning
Aug 07, 2023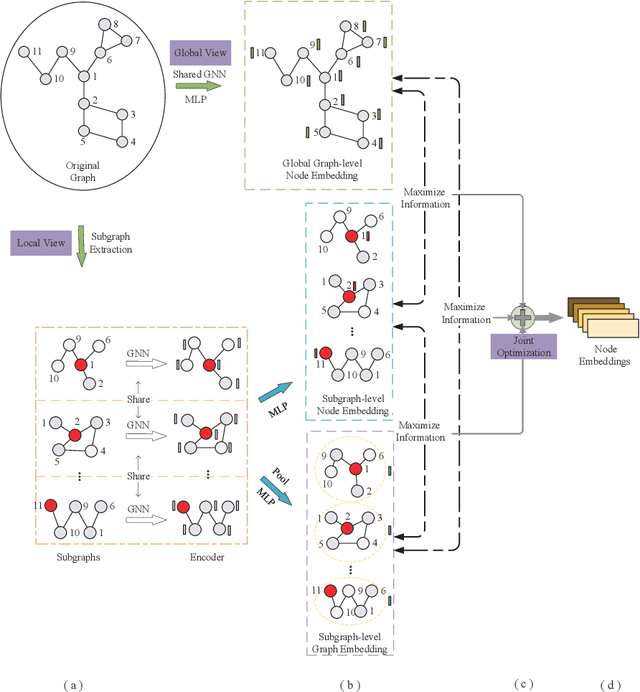


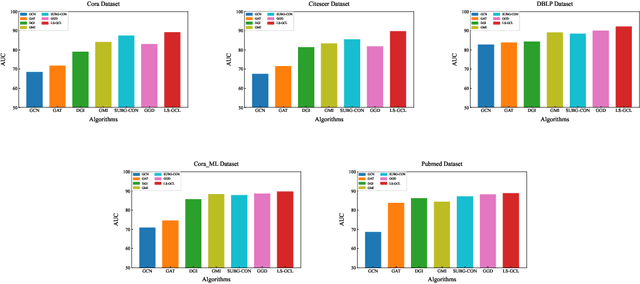
Traditional Graph Neural Network (GNN), as a graph representation learning method, is constrained by label information. However, Graph Contrastive Learning (GCL) methods, which tackle the label problem effectively, mainly focus on the feature information of the global graph or small subgraph structure (e.g., the first-order neighborhood). In the paper, we propose a Local Structure-aware Graph Contrastive representation Learning method (LS-GCL) to model the structural information of nodes from multiple views. Specifically, we construct the semantic subgraphs that are not limited to the first-order neighbors. For the local view, the semantic subgraph of each target node is input into a shared GNN encoder to obtain the target node embeddings at the subgraph-level. Then, we use a pooling function to generate the subgraph-level graph embeddings. For the global view, considering the original graph preserves indispensable semantic information of nodes, we leverage the shared GNN encoder to learn the target node embeddings at the global graph-level. The proposed LS-GCL model is optimized to maximize the common information among similar instances at three various perspectives through a multi-level contrastive loss function. Experimental results on five datasets illustrate that our method outperforms state-of-the-art graph representation learning approaches for both node classification and link prediction tasks.
DiffPattern: Layout Pattern Generation via Discrete Diffusion
Mar 23, 2023



Deep generative models dominate the existing literature in layout pattern generation. However, leaving the guarantee of legality to an inexplicable neural network could be problematic in several applications. In this paper, we propose \tool{DiffPattern} to generate reliable layout patterns. \tool{DiffPattern} introduces a novel diverse topology generation method via a discrete diffusion model with compute-efficiently lossless layout pattern representation. Then a white-box pattern assessment is utilized to generate legal patterns given desired design rules. Our experiments on several benchmark settings show that \tool{DiffPattern} significantly outperforms existing baselines and is capable of synthesizing reliable layout patterns.
A High-Performance Accelerator for Super-Resolution Processing on Embedded GPU
Mar 16, 2023Recent years have witnessed impressive progress in super-resolution (SR) processing. However, its real-time inference requirement sets a challenge not only for the model design but also for the on-chip implementation. In this paper, we implement a full-stack SR acceleration framework on embedded GPU devices. The special dictionary learning algorithm used in SR models was analyzed in detail and accelerated via a novel dictionary selective strategy. Besides, the hardware programming architecture together with the model structure is analyzed to guide the optimal design of computation kernels to minimize the inference latency under the resource constraints. With these novel techniques, the communication and computation bottlenecks in the deep dictionary learning-based SR models are tackled perfectly. The experiments on the edge embedded NVIDIA NX and 2080Ti show that our method outperforms the state-of-the-art NVIDIA TensorRT significantly, and can achieve real-time performance.
AdaOPC: A Self-Adaptive Mask Optimization Framework For Real Design Patterns
Mar 15, 2023Optical proximity correction (OPC) is a widely-used resolution enhancement technique (RET) for printability optimization. Recently, rigorous numerical optimization and fast machine learning are the research focus of OPC in both academia and industry, each of which complements the other in terms of robustness or efficiency. We inspect the pattern distribution on a design layer and find that different sub-regions have different pattern complexity. Besides, we also find that many patterns repetitively appear in the design layout, and these patterns may possibly share optimized masks. We exploit these properties and propose a self-adaptive OPC framework to improve efficiency. Firstly we choose different OPC solvers adaptively for patterns of different complexity from an extensible solver pool to reach a speed/accuracy co-optimization. Apart from that, we prove the feasibility of reusing optimized masks for repeated patterns and hence, build a graph-based dynamic pattern library reusing stored masks to further speed up the OPC flow. Experimental results show that our framework achieves substantial improvement in both performance and efficiency.