 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffPattern-Flex: Efficient Layout Pattern Generation via Discrete Diffusion
May 07, 2025Recent advancements in layout pattern generation have been dominated by deep generative models. However, relying solely on neural networks for legality guarantees raises concerns in many practical applications. In this paper, we present \tool{DiffPattern}-Flex, a novel approach designed to generate reliable layout patterns efficiently. \tool{DiffPattern}-Flex incorporates a new method for generating diverse topologies using a discrete diffusion model while maintaining a lossless and compute-efficient layout representation. To ensure legal pattern generation, we employ {an} optimization-based, white-box pattern assessment process based on specific design rules. Furthermore, fast sampling and efficient legalization technologies are employed to accelerate the generation process. Experimental results across various benchmarks demonstrate that \tool{DiffPattern}-Flex significantly outperforms existing methods and excels at producing reliable layout patterns.
TARAC: Mitigating Hallucination in LVLMs via Temporal Attention Real-time Accumulative Connection
Apr 05, 2025



Large Vision-Language Models have demonstrated remarkable performance across various tasks; however, the challenge of hallucinations constrains their practical applications. The hallucination problem arises from multiple factors, including the inherent hallucinations in language models, the limitations of visual encoders in perception, and biases introduced by multimodal data. Extensive research has explored ways to mitigate hallucinations. For instance, OPERA prevents the model from overly focusing on "anchor tokens", thereby reducing hallucinations, whereas VCD mitigates hallucinations by employing a contrastive decoding approach. In this paper, we investigate the correlation between the decay of attention to image tokens and the occurrence of hallucinations. Based on this finding, we propose Temporal Attention Real-time Accumulative Connection (TARAC), a novel training-free method that dynamically accumulates and updates LVLMs' attention on image tokens during generation. By enhancing the model's attention to image tokens, TARAC mitigates hallucinations caused by the decay of attention on image tokens. We validate the effectiveness of TARAC across multiple models and datasets, demonstrating that our approach substantially mitigates hallucinations. In particular, TARAC reduces $C_S$ by 25.2 and $C_I$ by 8.7 compared to VCD on the CHAIR benchmark.
ChatPattern: Layout Pattern Customization via Natural Language
Mar 15, 2024



Existing works focus on fixed-size layout pattern generation, while the more practical free-size pattern generation receives limited attention. In this paper, we propose ChatPattern, a novel Large-Language-Model (LLM) powered framework for flexible pattern customization. ChatPattern utilizes a two-part system featuring an expert LLM agent and a highly controllable layout pattern generator. The LLM agent can interpret natural language requirements and operate design tools to meet specified needs, while the generator excels in conditional layout generation, pattern modification, and memory-friendly patterns extension. Experiments on challenging pattern generation setting shows the ability of ChatPattern to synthesize high-quality large-scale patterns.
On the Evaluation of Generative Models in Distributed Learning Tasks
Oct 18, 2023The evaluation of deep generative models including generative adversarial networks (GANs) and diffusion models has been extensively studied in the literature. While the existing evaluation methods mainly target a centralized learning problem with training data stored by a single client, many applications of generative models concern distributed learning settings, e.g. the federated learning scenario, where training data are collected by and distributed among several clients. In this paper, we study the evaluation of generative models in distributed learning tasks with heterogeneous data distributions. First, we focus on the Fr\'echet inception distance (FID) and consider the following FID-based aggregate scores over the clients: 1) FID-avg as the mean of clients' individual FID scores, 2) FID-all as the FID distance of the trained model to the collective dataset containing all clients' data. We prove that the model rankings according to the FID-all and FID-avg scores could be inconsistent, which can lead to different optimal generative models according to the two aggregate scores. Next, we consider the kernel inception distance (KID) and similarly define the KID-avg and KID-all aggregations. Unlike the FID case, we prove that KID-all and KID-avg result in the same rankings of generative models. We perform several numerical experiments on standard image datasets and training schemes to support our theoretical findings on the evaluation of generative models in distributed learning problems.
FedLPA: Personalized One-shot Federated Learning with Layer-Wise Posterior Aggregation
Oct 03, 2023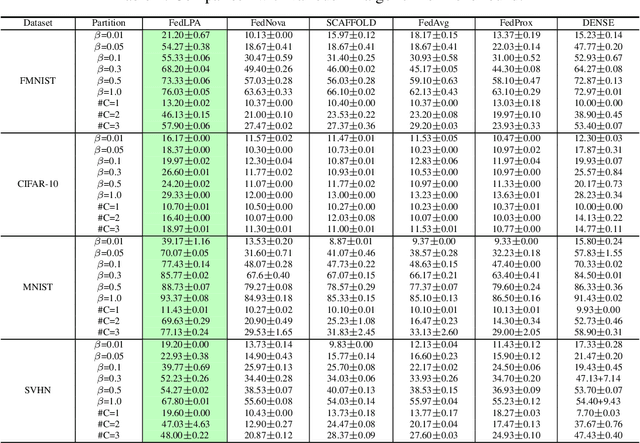
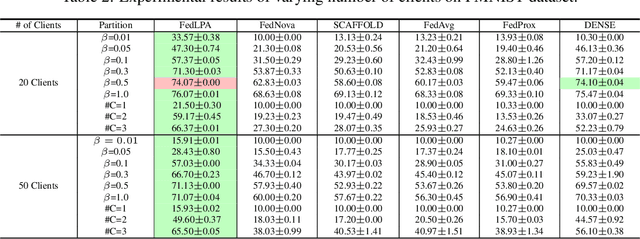
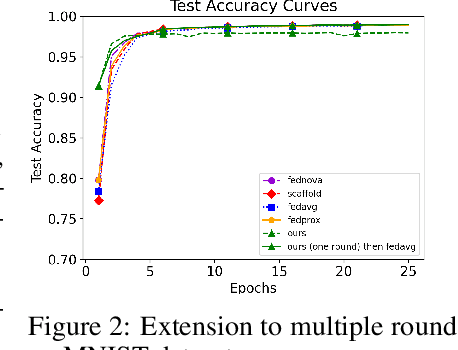
Efficiently aggregating trained neural networks from local clients into a global model on a server is a widely researched topic in federated learning. Recently, motivated by diminishing privacy concerns, mitigating potential attacks, and reducing the overhead of communication, one-shot federated learning (i.e., limiting client-server communication into a single round) has gained popularity among researchers. However, the one-shot aggregation performances are sensitively affected by the non-identical training data distribution, which exhibits high statistical heterogeneity in some real-world scenarios. To address this issue, we propose a novel one-shot aggregation method with Layer-wise Posterior Aggregation, named FedLPA. FedLPA aggregates local models to obtain a more accurate global model without requiring extra auxiliary datasets or exposing any confidential local information, e.g., label distributions. To effectively capture the statistics maintained in the biased local datasets in the practical non-IID scenario, we efficiently infer the posteriors of each layer in each local model using layer-wise Laplace approximation and aggregate them to train the global parameters. Extensive experimental results demonstrate that FedLPA significantly improves learning performance over state-of-the-art methods across several metrics.
Federated Learning with Classifier Shift for Class Imbalance
Apr 11, 2023Federated learning aims to learn a global model collaboratively while the training data belongs to different clients and is not allowed to be exchanged. However, the statistical heterogeneity challenge on non-IID data, such as class imbalance in classification, will cause client drift and significantly reduce the performance of the global model. This paper proposes a simple and effective approach named FedShift which adds the shift on the classifier output during the local training phase to alleviate the negative impact of class imbalance. We theoretically prove that the classifier shift in FedShift can make the local optimum consistent with the global optimum and ensure the convergence of the algorithm. Moreover, our experiments indicate that FedShift significantly outperforms the other state-of-the-art federated learning approaches on various datasets regarding accuracy and communication efficiency.
DiffPattern: Layout Pattern Generation via Discrete Diffusion
Mar 23, 2023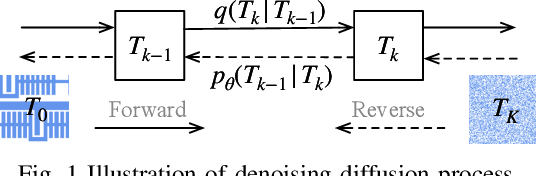



Deep generative models dominate the existing literature in layout pattern generation. However, leaving the guarantee of legality to an inexplicable neural network could be problematic in several applications. In this paper, we propose \tool{DiffPattern} to generate reliable layout patterns. \tool{DiffPattern} introduces a novel diverse topology generation method via a discrete diffusion model with compute-efficiently lossless layout pattern representation. Then a white-box pattern assessment is utilized to generate legal patterns given desired design rules. Our experiments on several benchmark settings show that \tool{DiffPattern} significantly outperforms existing baselines and is capable of synthesizing reliable layout patterns.