 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Generation with Endpoint Regulation and Momentum-Aware Dynamics for Visually Impaired Scenarios
Feb 25, 2026Trajectory generation for visually impaired scenarios requires smooth and temporally consistent state in structured, low-speed dynamic environments. However, traditional jerk-based heuristic trajectory sampling with independent segment generation and conventional smoothness penalties often lead to unstable terminal behavior and state discontinuities under frequent regenerating. This paper proposes a trajectory generation approach that integrates endpoint regulation to stabilize terminal states within each segment and momentum-aware dynamics to regularize the evolution of velocity and acceleration for segment consistency. Endpoint regulation is incorporated into trajectory sampling to stabilize terminal behavior, while a momentum-aware dynamics enforces consistent velocity and acceleration evolution across consecutive trajectory segments. Experimental results demonstrate reduced acceleration peaks and lower jerk levels with decreased dispersion, smoother velocity and acceleration profiles, more stable endpoint distributions, and fewer infeasible trajectory candidates compared with a baseline planner.
Mitigating Cultural Bias in LLMs via Multi-Agent Cultural Debate
Jan 17, 2026Large language models (LLMs) exhibit systematic Western-centric bias, yet whether prompting in non-Western languages (e.g., Chinese) can mitigate this remains understudied. Answering this question requires rigorous evaluation and effective mitigation, but existing approaches fall short on both fronts: evaluation methods force outputs into predefined cultural categories without a neutral option, while mitigation relies on expensive multi-cultural corpora or agent frameworks that use functional roles (e.g., Planner--Critique) lacking explicit cultural representation. To address these gaps, we introduce CEBiasBench, a Chinese--English bilingual benchmark, and Multi-Agent Vote (MAV), which enables explicit ``no bias'' judgments. Using this framework, we find that Chinese prompting merely shifts bias toward East Asian perspectives rather than eliminating it. To mitigate such persistent bias, we propose Multi-Agent Cultural Debate (MACD), a training-free framework that assigns agents distinct cultural personas and orchestrates deliberation via a "Seeking Common Ground while Reserving Differences" strategy. Experiments demonstrate that MACD achieves 57.6% average No Bias Rate evaluated by LLM-as-judge and 86.0% evaluated by MAV (vs. 47.6% and 69.0% baseline using GPT-4o as backbone) on CEBiasBench and generalizes to the Arabic CAMeL benchmark, confirming that explicit cultural representation in agent frameworks is essential for cross-cultural fairness.
IFDNS: An Iterative Feedback-Driven Neuro-Symbolic Method for Faithful Logical Reasoning
Jan 12, 2026Large language models (LLMs) have demonstrated impressive capabilities across a wide range of reasoning tasks, including logical and mathematical problem-solving. While prompt-based methods like Chain-of-Thought (CoT) can enhance LLM reasoning abilities to some extent, they often suffer from a lack of faithfulness, where the derived conclusions may not align with the generated reasoning chain. To address this issue, researchers have explored neuro-symbolic approaches to bolster LLM logical reasoning capabilities. However, existing neuro-symbolic methods still face challenges with information loss during the process. To overcome these limitations, we introduce Iterative Feedback-Driven Neuro-Symbolic (IFDNS), a novel prompt-based method that employs a multi-round feedback mechanism to address LLM limitations in handling complex logical relationships. IFDNS utilizes iterative feedback during the logic extraction phase to accurately extract causal relationship statements and translate them into propositional and logical implication expressions, effectively mitigating information loss issues. Furthermore, IFDNS is orthogonal to existing prompt methods, allowing for seamless integration with various prompting approaches. Empirical evaluations across six datasets demonstrate the effectiveness of IFDNS in significantly improving the performance of CoT and Chain-of-Thought with Self-Consistency (CoT-SC). Specifically, IFDNS achieves a +9.40% accuracy boost for CoT on the LogiQA dataset and a +11.70% improvement for CoT-SC on the PrOntoQA dataset.
Momentum-constrained Hybrid Heuristic Trajectory Optimization Framework with Residual-enhanced DRL for Visually Impaired Scenarios
Sep 19, 2025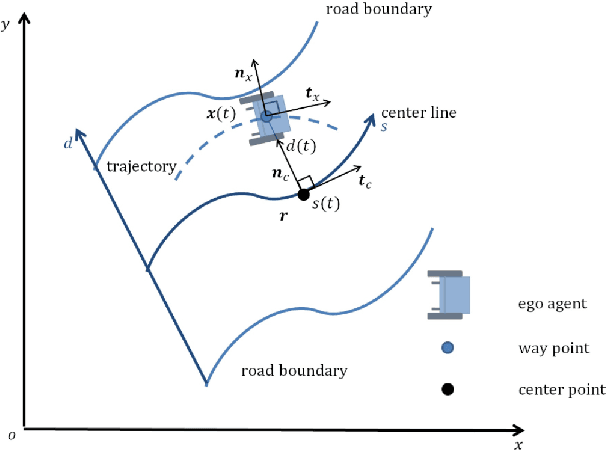
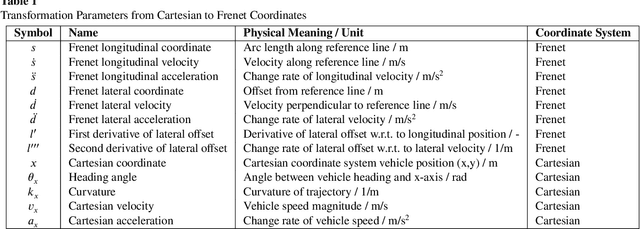
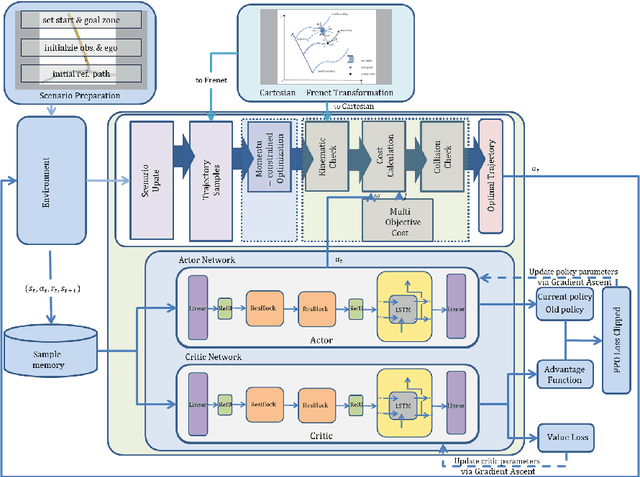

This paper proposes a momentum-constrained hybrid heuristic trajectory optimization framework (MHHTOF) tailored for assistive navigation in visually impaired scenarios, integrating trajectory sampling generation, optimization and evaluation with residual-enhanced deep reinforcement learning (DRL). In the first stage, heuristic trajectory sampling cluster (HTSC) is generated in the Frenet coordinate system using third-order interpolation with fifth-order polynomials and momentum-constrained trajectory optimization (MTO) constraints to ensure smoothness and feasibility. After first stage cost evaluation, the second stage leverages a residual-enhanced actor-critic network with LSTM-based temporal feature modeling to adaptively refine trajectory selection in the Cartesian coordinate system. A dual-stage cost modeling mechanism (DCMM) with weight transfer aligns semantic priorities across stages, supporting human-centered optimization. Experimental results demonstrate that the proposed LSTM-ResB-PPO achieves significantly faster convergence, attaining stable policy performance in approximately half the training iterations required by the PPO baseline, while simultaneously enhancing both reward outcomes and training stability. Compared to baseline method, the selected model reduces average cost and cost variance by 30.3% and 53.3%, and lowers ego and obstacle risks by over 77%. These findings validate the framework's effectiveness in enhancing robustness, safety, and real-time feasibility in complex assistive planning tasks.
Are LLMs Reliable Translators of Logical Reasoning Across Lexically Diversified Contexts?
Jun 05, 2025Neuro-symbolic approaches combining large language models (LLMs) with solvers excels in logical reasoning problems need long reasoning chains. In this paradigm, LLMs serve as translators, converting natural language reasoning problems into formal logic formulas. Then reliable symbolic solvers return correct solutions. Despite their success, we find that LLMs, as translators, struggle to handle lexical diversification, a common linguistic phenomenon, indicating that LLMs as logic translators are unreliable in real-world scenarios. Moreover, existing logical reasoning benchmarks lack lexical diversity, failing to challenge LLMs' ability to translate such text and thus obscuring this issue. In this work, we propose SCALe, a benchmark designed to address this significant gap through **logic-invariant lexical diversification**. By using LLMs to transform original benchmark datasets into lexically diversified but logically equivalent versions, we evaluate LLMs' ability to consistently map diverse expressions to uniform logical symbols on these new datasets. Experiments using SCALe further confirm that current LLMs exhibit deficiencies in this capability. Building directly on the deficiencies identified through our benchmark, we propose a new method, MenTaL, to address this limitation. This method guides LLMs to first construct a table unifying diverse expressions before performing translation. Applying MenTaL through in-context learning and supervised fine-tuning (SFT) significantly improves the performance of LLM translators on lexically diversified text. Our code is now available at https://github.com/wufeiwuwoshihua/LexicalDiver.
TARAC: Mitigating Hallucination in LVLMs via Temporal Attention Real-time Accumulative Connection
Apr 05, 2025



Large Vision-Language Models have demonstrated remarkable performance across various tasks; however, the challenge of hallucinations constrains their practical applications. The hallucination problem arises from multiple factors, including the inherent hallucinations in language models, the limitations of visual encoders in perception, and biases introduced by multimodal data. Extensive research has explored ways to mitigate hallucinations. For instance, OPERA prevents the model from overly focusing on "anchor tokens", thereby reducing hallucinations, whereas VCD mitigates hallucinations by employing a contrastive decoding approach. In this paper, we investigate the correlation between the decay of attention to image tokens and the occurrence of hallucinations. Based on this finding, we propose Temporal Attention Real-time Accumulative Connection (TARAC), a novel training-free method that dynamically accumulates and updates LVLMs' attention on image tokens during generation. By enhancing the model's attention to image tokens, TARAC mitigates hallucinations caused by the decay of attention on image tokens. We validate the effectiveness of TARAC across multiple models and datasets, demonstrating that our approach substantially mitigates hallucinations. In particular, TARAC reduces $C_S$ by 25.2 and $C_I$ by 8.7 compared to VCD on the CHAIR benchmark.
S$^2$-MAD: Breaking the Token Barrier to Enhance Multi-Agent Debate Efficiency
Feb 07, 2025



Large language models (LLMs) have demonstrated remarkable capabilities across various natural language processing (NLP) scenarios, but they still face challenges when handling complex arithmetic and logical reasoning tasks. While Chain-Of-Thought (CoT) reasoning, self-consistency (SC) and self-correction strategies have attempted to guide models in sequential, multi-step reasoning, Multi-agent Debate (MAD) has emerged as a viable approach for enhancing the reasoning capabilities of LLMs. By increasing both the number of agents and the frequency of debates, the performance of LLMs improves significantly. However, this strategy results in a significant increase in token costs, presenting a barrier to scalability. To address this challenge, we introduce a novel sparsification strategy designed to reduce token costs within MAD. This approach minimizes ineffective exchanges of information and unproductive discussions among agents, thereby enhancing the overall efficiency of the debate process. We conduct comparative experiments on multiple datasets across various models, demonstrating that our approach significantly reduces the token costs in MAD to a considerable extent. Specifically, compared to MAD, our approach achieves an impressive reduction of up to 94.5\% in token costs while maintaining performance degradation below 2.0\%.
FoPru: Focal Pruning for Efficient Large Vision-Language Models
Nov 21, 2024



Large Vision-Language Models (LVLMs) represent a significant advancement toward achieving superior multimodal capabilities by enabling powerful Large Language Models (LLMs) to understand visual input. Typically, LVLMs utilize visual encoders, such as CLIP, to transform images into visual tokens, which are then aligned with textual tokens through projection layers before being input into the LLM for inference. Although existing LVLMs have achieved significant success, their inference efficiency is still limited by the substantial number of visual tokens and the potential redundancy among them. To mitigate this issue, we propose Focal Pruning (FoPru), a training-free method that prunes visual tokens based on the attention-based token significance derived from the vision encoder. Specifically, we introduce two alternative pruning strategies: 1) the rank strategy, which leverages all token significance scores to retain more critical tokens in a global view; 2) the row strategy, which focuses on preserving continuous key information in images from a local perspective. Finally, the selected tokens are reordered to maintain their original positional relationships. Extensive experiments across various LVLMs and multimodal datasets demonstrate that our method can prune a large number of redundant tokens while maintaining high accuracy, leading to significant improvements in inference efficiency.
Leveraging LLMs for Hypothetical Deduction in Logical Inference: A Neuro-Symbolic Approach
Oct 29, 2024



Large Language Models (LLMs) have exhibited remarkable potential across a wide array of reasoning tasks, including logical reasoning. Although massive efforts have been made to empower the logical reasoning ability of LLMs via external logical symbolic solvers, crucial challenges of the poor generalization ability to questions with different features and inevitable question information loss of symbolic solver-driven approaches remain unresolved. To mitigate these issues, we introduce LINA, a LLM-driven neuro-symbolic approach for faithful logical reasoning. By enabling an LLM to autonomously perform the transition from propositional logic extraction to sophisticated logical reasoning, LINA not only bolsters the resilience of the reasoning process but also eliminates the dependency on external solvers. Additionally, through its adoption of a hypothetical-deductive reasoning paradigm, LINA effectively circumvents the expansive search space challenge that plagues traditional forward reasoning methods. Empirical evaluations demonstrate that LINA substantially outperforms both established propositional logic frameworks and conventional prompting techniques across a spectrum of five logical reasoning tasks. Specifically, LINA achieves an improvement of 24.34% over LINC on the FOLIO dataset, while also surpassing prompting strategies like CoT and CoT-SC by up to 24.02%. Our code is available at https://github.com/wufeiwuwoshihua/nshy.
GroupDebate: Enhancing the Efficiency of Multi-Agent Debate Using Group Discussion
Sep 21, 2024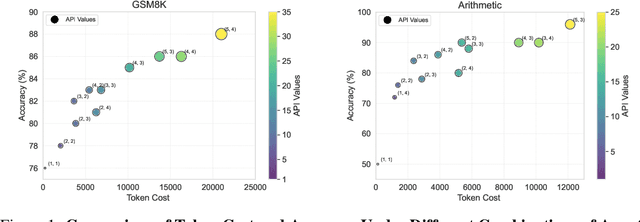
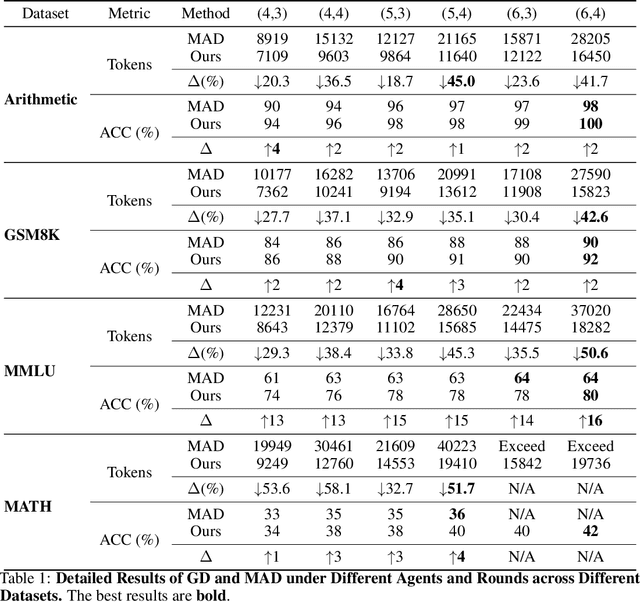
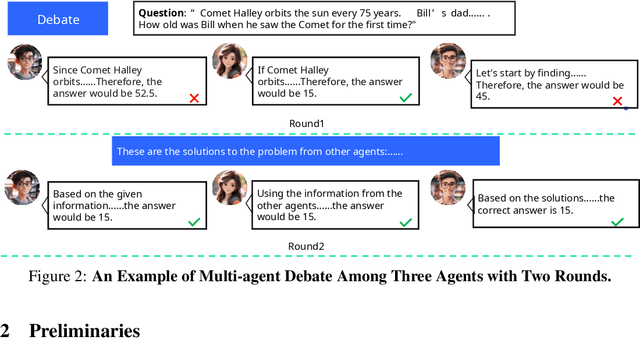
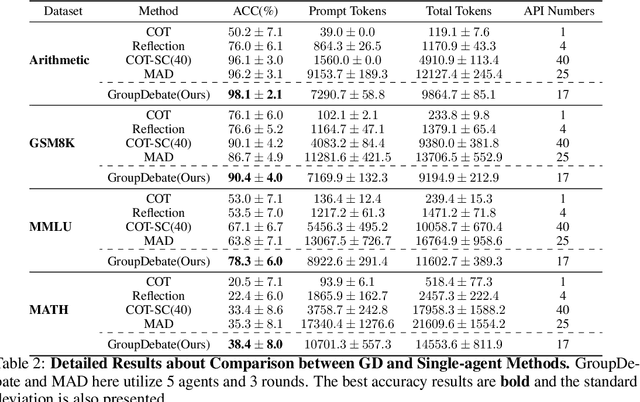
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse NLP tasks. Extensive research has explored how to enhance the logical reasoning abilities such as Chain-of-Thought, Chain-of-Thought with Self-Consistency, Tree-Of-Thoughts, and multi-agent debates. In the context of multi-agent debates, significant performance improvements can be achieved with an increasing number of agents and debate rounds. However, the escalation in the number of agents and debate rounds can drastically raise the tokens cost of debates, thereby limiting the scalability of the multi-agent debate technique. To better harness the advantages of multi-agent debates in logical reasoning tasks, this paper proposes a method to significantly reduce token cost in multi-agent debates. This approach involves dividing all agents into multiple debate groups, with agents engaging in debates within their respective groups and sharing interim debate results between groups. Comparative experiments across multiple datasets have demonstrated that this method can reduce the total tokens by up to 51.7% during debates and while potentially enhancing accuracy by as much as 25%. Our method significantly enhances the performance and efficiency of interactions in the multi-agent debate.