 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Tree of Thoughts: Deliberate Manipulation Planning with Embodied World Model
Dec 09, 2025World models have emerged as a pivotal component in robot manipulation planning, enabling agents to predict future environmental states and reason about the consequences of actions before execution. While video-generation models are increasingly adopted, they often lack rigorous physical grounding, leading to hallucinations and a failure to maintain consistency in long-horizon physical constraints. To address these limitations, we propose Embodied Tree of Thoughts (EToT), a novel Real2Sim2Real planning framework that leverages a physics-based interactive digital twin as an embodied world model. EToT formulates manipulation planning as a tree search expanded through two synergistic mechanisms: (1) Priori Branching, which generates diverse candidate execution paths based on semantic and spatial analysis; and (2) Reflective Branching, which utilizes VLMs to diagnose execution failures within the simulator and iteratively refine the planning tree with corrective actions. By grounding high-level reasoning in a physics simulator, our framework ensures that generated plans adhere to rigid-body dynamics and collision constraints. We validate EToT on a suite of short- and long-horizon manipulation tasks, where it consistently outperforms baselines by effectively predicting physical dynamics and adapting to potential failures. Website at https://embodied-tree-of-thoughts.github.io .
Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models
Sep 26, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks but their performance in complex logical reasoning tasks remains unsatisfactory. Although some prompting methods, such as Chain-of-Thought, can improve the reasoning ability of LLMs to some extent, they suffer from an unfaithful issue where derived conclusions may not align with the generated reasoning chain. To address this issue, some studies employ the approach of propositional logic to further enhance logical reasoning abilities of LLMs. However, the potential omissions in the extraction of logical expressions in these methods can cause information loss in the logical reasoning process, thereby generating incorrect results. To this end, we propose Logic-of-Thought (LoT) prompting which employs propositional logic to generate expanded logical information from input context, and utilizes the generated logical information as an additional augmentation to the input prompts, thereby enhancing the capability of logical reasoning. The LoT is orthogonal to existing prompting methods and can be seamlessly integrated with them. Extensive experiments demonstrate that LoT boosts the performance of various prompting methods with a striking margin across five logical reasoning tasks. In particular, the LoT enhances Chain-of-Thought's performance on the ReClor dataset by +4.35%; moreover, it improves Chain-of-Thought with Self-Consistency's performance on LogiQA by +5%; additionally, it boosts performance of Tree-of-Thoughts on ProofWriter dataset by +8%.
GroupDebate: Enhancing the Efficiency of Multi-Agent Debate Using Group Discussion
Sep 21, 2024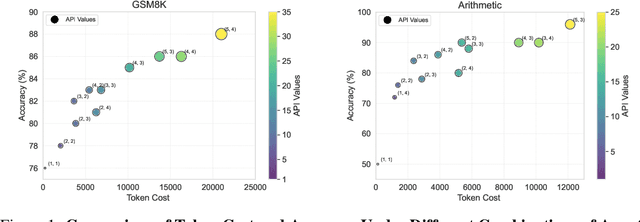
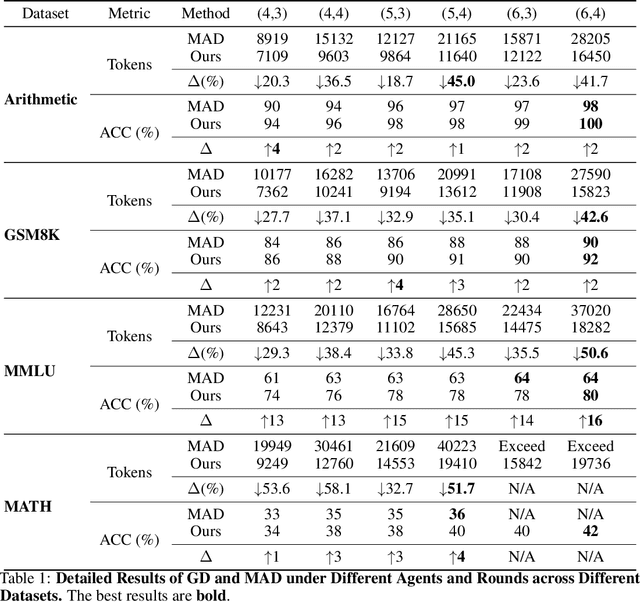
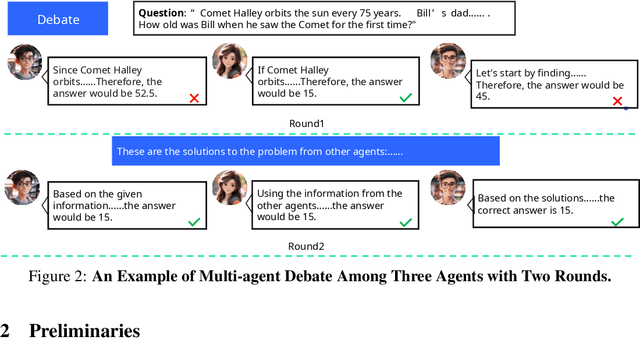
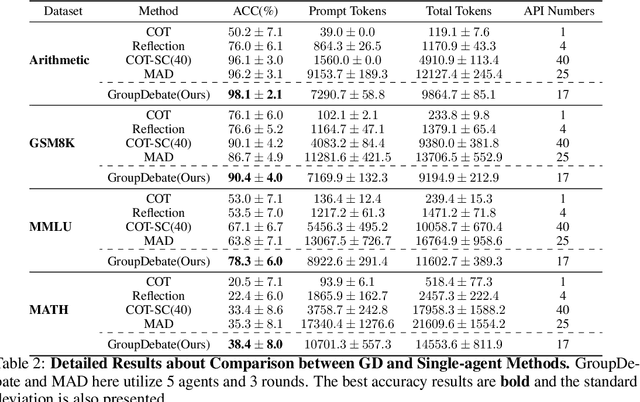
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse NLP tasks. Extensive research has explored how to enhance the logical reasoning abilities such as Chain-of-Thought, Chain-of-Thought with Self-Consistency, Tree-Of-Thoughts, and multi-agent debates. In the context of multi-agent debates, significant performance improvements can be achieved with an increasing number of agents and debate rounds. However, the escalation in the number of agents and debate rounds can drastically raise the tokens cost of debates, thereby limiting the scalability of the multi-agent debate technique. To better harness the advantages of multi-agent debates in logical reasoning tasks, this paper proposes a method to significantly reduce token cost in multi-agent debates. This approach involves dividing all agents into multiple debate groups, with agents engaging in debates within their respective groups and sharing interim debate results between groups. Comparative experiments across multiple datasets have demonstrated that this method can reduce the total tokens by up to 51.7% during debates and while potentially enhancing accuracy by as much as 25%. Our method significantly enhances the performance and efficiency of interactions in the multi-agent debate.