 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
Harnessing On-Device Large Language Model: Empirical Results and Implications for AI PC
May 22, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
Harnessing Large Language Models Locally: Empirical Results and Implications for AI PC
May 21, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
ToTRL: Unlock LLM Tree-of-Thoughts Reasoning Potential through Puzzles Solving
May 19, 2025



Large language models (LLMs) demonstrate significant reasoning capabilities, particularly through long chain-of-thought (CoT) processes, which can be elicited by reinforcement learning (RL). However, prolonged CoT reasoning presents limitations, primarily verbose outputs due to excessive introspection. The reasoning process in these LLMs often appears to follow a trial-and-error methodology rather than a systematic, logical deduction. In contrast, tree-of-thoughts (ToT) offers a conceptually more advanced approach by modeling reasoning as an exploration within a tree structure. This reasoning structure facilitates the parallel generation and evaluation of multiple reasoning branches, allowing for the active identification, assessment, and pruning of unproductive paths. This process can potentially lead to improved performance and reduced token costs. Building upon the long CoT capability of LLMs, we introduce tree-of-thoughts RL (ToTRL), a novel on-policy RL framework with a rule-based reward. ToTRL is designed to guide LLMs in developing the parallel ToT strategy based on the sequential CoT strategy. Furthermore, we employ LLMs as players in a puzzle game during the ToTRL training process. Solving puzzle games inherently necessitates exploring interdependent choices and managing multiple constraints, which requires the construction and exploration of a thought tree, providing challenging tasks for cultivating the ToT reasoning capability. Our empirical evaluations demonstrate that our ToTQwen3-8B model, trained with our ToTRL, achieves significant improvement in performance and reasoning efficiency on complex reasoning tasks.
Architect of the Bits World: Masked Autoregressive Modeling for Circuit Generation Guided by Truth Table
Feb 18, 2025Logic synthesis, a critical stage in electronic design automation (EDA), optimizes gate-level circuits to minimize power consumption and area occupancy in integrated circuits (ICs). Traditional logic synthesis tools rely on human-designed heuristics, often yielding suboptimal results. Although differentiable architecture search (DAS) has shown promise in generating circuits from truth tables, it faces challenges such as high computational complexity, convergence to local optima, and extensive hyperparameter tuning. Consequently, we propose a novel approach integrating conditional generative models with DAS for circuit generation. Our approach first introduces CircuitVQ, a circuit tokenizer trained based on our Circuit AutoEncoder We then develop CircuitAR, a masked autoregressive model leveraging CircuitVQ as the tokenizer. CircuitAR can generate preliminary circuit structures from truth tables, which guide DAS in producing functionally equivalent circuits. Notably, we observe the scalability and emergent capability in generating complex circuit structures of our CircuitAR models. Extensive experiments also show the superior performance of our method. This research bridges the gap between probabilistic generative models and precise circuit generation, offering a robust solution for logic synthesis.
Efficient Bayesian Optimization with Deep Kernel Learning and Transformer Pre-trained on Multiple Heterogeneous Datasets
Aug 09, 2023



Bayesian optimization (BO) is widely adopted in black-box optimization problems and it relies on a surrogate model to approximate the black-box response function. With the increasing number of black-box optimization tasks solved and even more to solve, the ability to learn from multiple prior tasks to jointly pre-train a surrogate model is long-awaited to further boost optimization efficiency. In this paper, we propose a simple approach to pre-train a surrogate, which is a Gaussian process (GP) with a kernel defined on deep features learned from a Transformer-based encoder, using datasets from prior tasks with possibly heterogeneous input spaces. In addition, we provide a simple yet effective mix-up initialization strategy for input tokens corresponding to unseen input variables and therefore accelerate new tasks' convergence. Experiments on both synthetic and real benchmark problems demonstrate the effectiveness of our proposed pre-training and transfer BO strategy over existing methods.
Reframed GES with a Neural Conditional Dependence Measure
Jun 17, 2022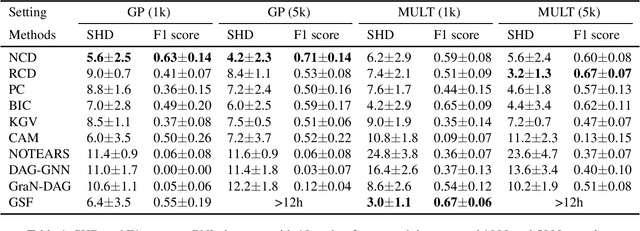
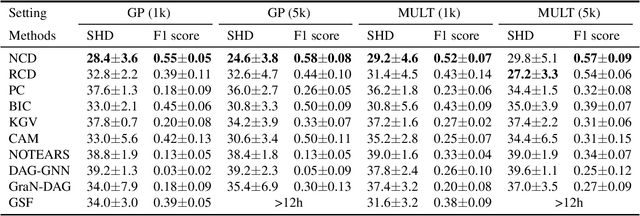
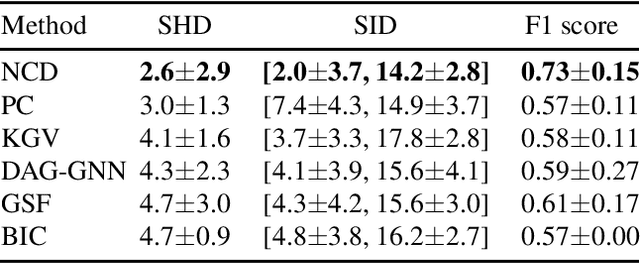
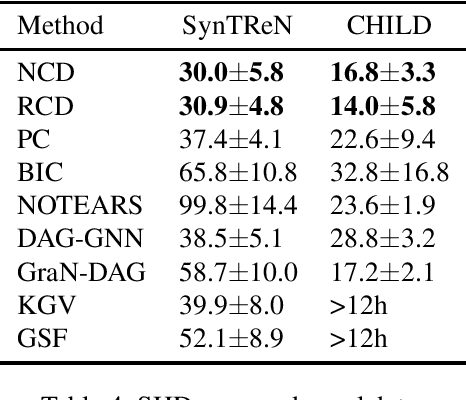
In a nonparametric setting, the causal structure is often identifiable only up to Markov equivalence, and for the purpose of causal inference, it is useful to learn a graphical representation of the Markov equivalence class (MEC). In this paper, we revisit the Greedy Equivalence Search (GES) algorithm, which is widely cited as a score-based algorithm for learning the MEC of the underlying causal structure. We observe that in order to make the GES algorithm consistent in a nonparametric setting, it is not necessary to design a scoring metric that evaluates graphs. Instead, it suffices to plug in a consistent estimator of a measure of conditional dependence to guide the search. We therefore present a reframing of the GES algorithm, which is more flexible than the standard score-based version and readily lends itself to the nonparametric setting with a general measure of conditional dependence. In addition, we propose a neural conditional dependence (NCD) measure, which utilizes the expressive power of deep neural networks to characterize conditional independence in a nonparametric manner. We establish the optimality of the reframed GES algorithm under standard assumptions and the consistency of using our NCD estimator to decide conditional independence. Together these results justify the proposed approach. Experimental results demonstrate the effectiveness of our method in causal discovery, as well as the advantages of using our NCD measure over kernel-based measures.
Contrastive ACE: Domain Generalization Through Alignment of Causal Mechanisms
Jun 02, 2021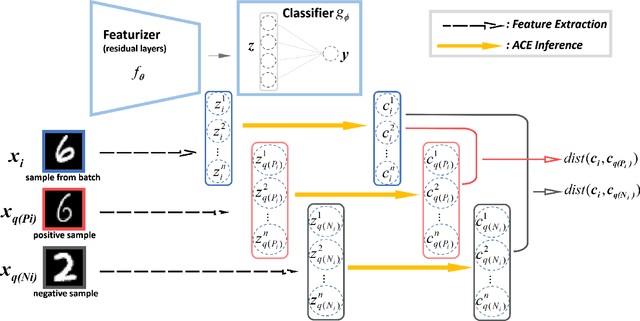
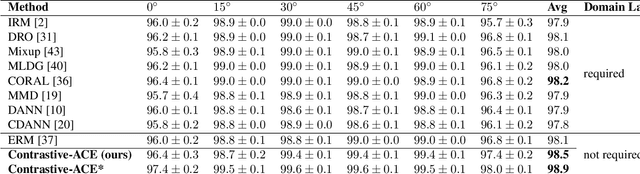
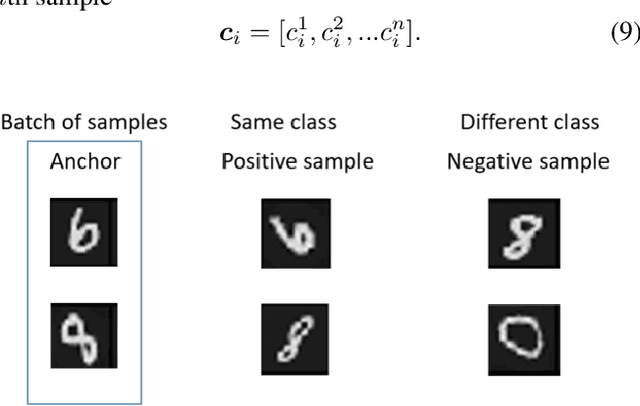
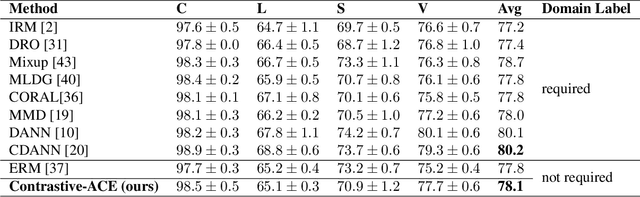
Domain generalization aims to learn knowledge invariant across different distributions while semantically meaningful for downstream tasks from multiple source domains, to improve the model's generalization ability on unseen target domains. The fundamental objective is to understand the underlying "invariance" behind these observational distributions and such invariance has been shown to have a close connection to causality. While many existing approaches make use of the property that causal features are invariant across domains, we consider the causal invariance of the average causal effect of the features to the labels. This invariance regularizes our training approach in which interventions are performed on features to enforce stability of the causal prediction by the classifier across domains. Our work thus sheds some light on the domain generalization problem by introducing invariance of the mechanisms into the learning process. Experiments on several benchmark datasets demonstrate the performance of the proposed method against SOTAs.
Clustering Causal Additive Noise Models
Jun 08, 2020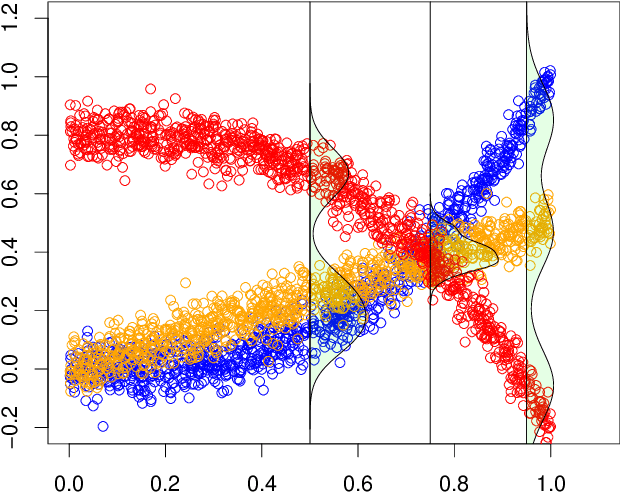
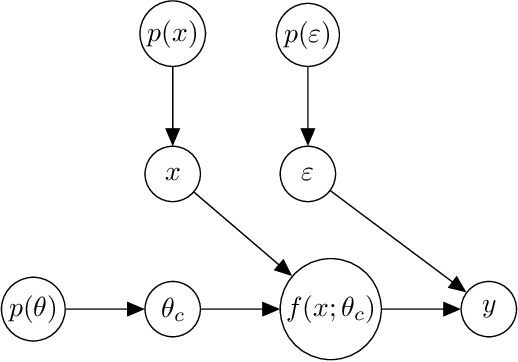
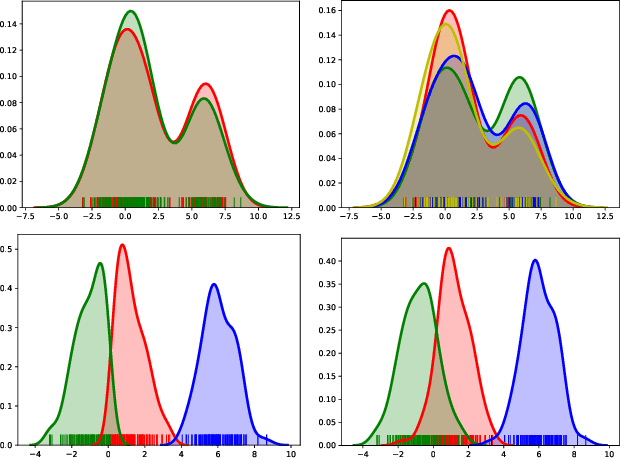
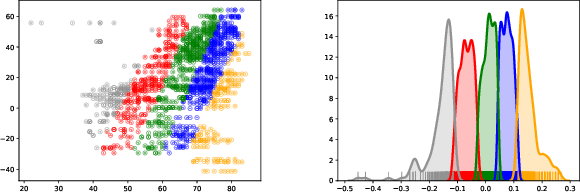
Additive noise models are commonly used to infer the causal direction for a given set of observed data. Most causal models assume a single homogeneous population. However, observations may be collected under different conditions in practice. Such data often require models that can accommodate possible heterogeneity caused by different conditions under which data have been collected. We propose a clustering algorithm inspired by the $k$-means algorithm, but with unknown $k$. Using the proposed algorithm, both the labels and the number of components are estimated from the collected data. The estimated labels are used to adjust the causal direction test statistic. The adjustment significantly improves the performance of the test statistic in identifying the correct causal direction.
Domain Generalization via Multidomain Discriminant Analysis
Jul 25, 2019
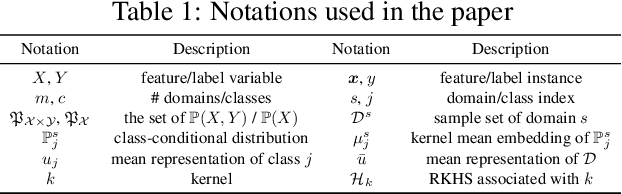

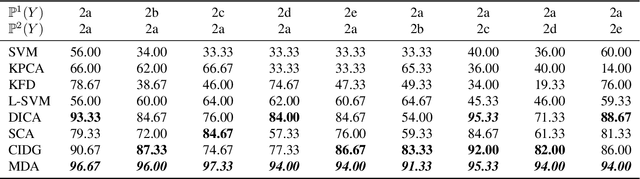
Domain generalization (DG) aims to incorporate knowledge from multiple source domains into a single model that could generalize well on unseen target domains. This problem is ubiquitous in practice since the distributions of the target data may rarely be identical to those of the source data. In this paper, we propose Multidomain Discriminant Analysis (MDA) to address DG of classification tasks in general situations. MDA learns a domain-invariant feature transformation that aims to achieve appealing properties, including a minimal divergence among domains within each class, a maximal separability among classes, and overall maximal compactness of all classes. Furthermore, we provide the bounds on excess risk and generalization error by learning theory analysis. Comprehensive experiments on synthetic and real benchmark datasets demonstrate the effectiveness of MDA.