 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Knowledge-Enhanced Medical VLP for Chest X-Ray
Apr 23, 2024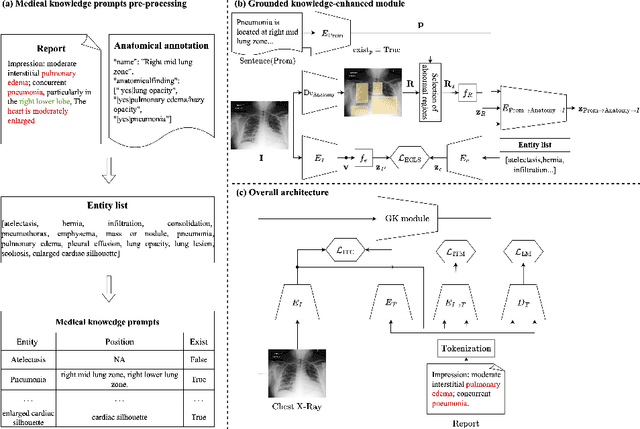
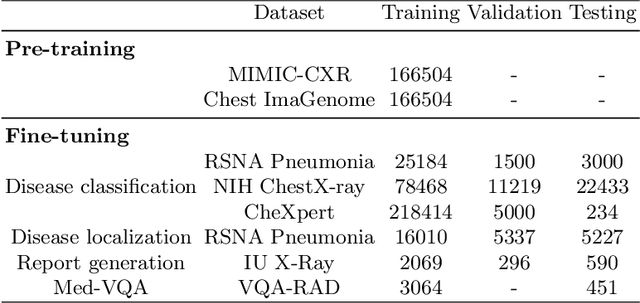
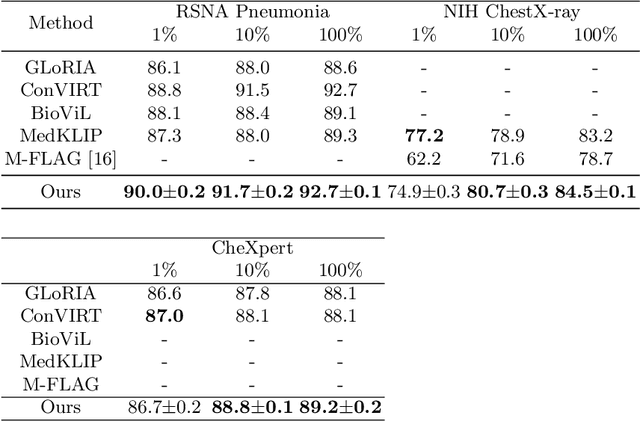
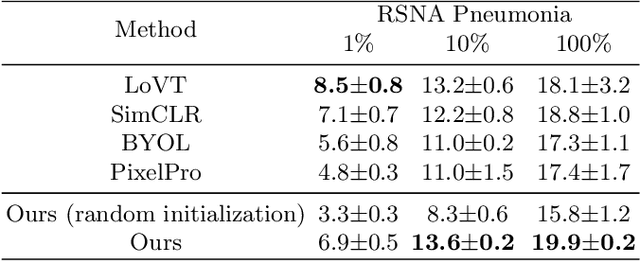
Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.
ENGNN: A General Edge-Update Empowered GNN Architecture for Radio Resource Management in Wireless Networks
Dec 14, 2022



In order to achieve high data rate and ubiquitous connectivity in future wireless networks, a key task is to efficiently manage the radio resource by judicious beamforming and power allocation. Unfortunately, the iterative nature of the commonly applied optimization-based algorithms cannot meet the low latency requirements due to the high computational complexity. For real-time implementations, deep learning-based approaches, especially the graph neural networks (GNNs), have been demonstrated with good scalability and generalization performance due to the permutation equivariance (PE) property. However, the current architectures are only equipped with the node-update mechanism, which prohibits the applications to a more general setup, where the unknown variables are also defined on the graph edges. To fill this gap, we propose an edge-update mechanism, which enables GNNs to handle both node and edge variables and prove its PE property with respect to both transmitters and receivers. Simulation results on typical radio resource management problems demonstrate that the proposed method achieves higher sum rate but with much shorter computation time than state-of-the-art methods and generalizes well on different numbers of base stations and users, different noise variances, interference levels, and transmit power budgets.
Learning Cooperative Beamforming with Edge-Update Empowered Graph Neural Networks
Nov 23, 2022Cooperative beamforming design has been recognized as an effective approach in modern wireless networks to meet the dramatically increasing demand of various wireless data traffics. It is formulated as an optimization problem in conventional approaches and solved iteratively in an instance-by-instance manner. Recently, learning-based methods have emerged with real-time implementation by approximating the mapping function from the problem instances to the corresponding solutions. Among various neural network architectures, graph neural networks (GNNs) can effectively utilize the graph topology in wireless networks to achieve better generalization ability on unseen problem sizes. However, the current GNNs are only equipped with the node-update mechanism, which restricts it from modeling more complicated problems such as the cooperative beamforming design, where the beamformers are on the graph edges of wireless networks. To fill this gap, we propose an edge-graph-neural-network (Edge-GNN) by incorporating an edge-update mechanism into the GNN, which learns the cooperative beamforming on the graph edges. Simulation results show that the proposed Edge-GNN achieves higher sum rate with much shorter computation time than state-of-the-art approaches, and generalizes well to different numbers of base stations and user equipments.
Heterogeneous Transformer: A Scale Adaptable Neural Network Architecture for Device Activity Detection
Dec 19, 2021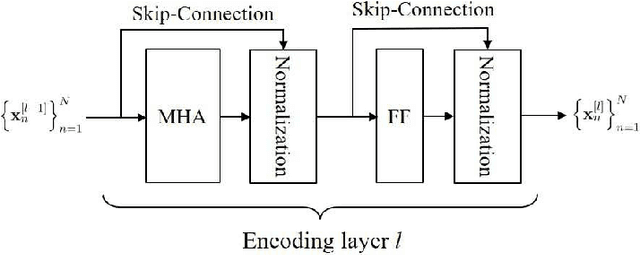
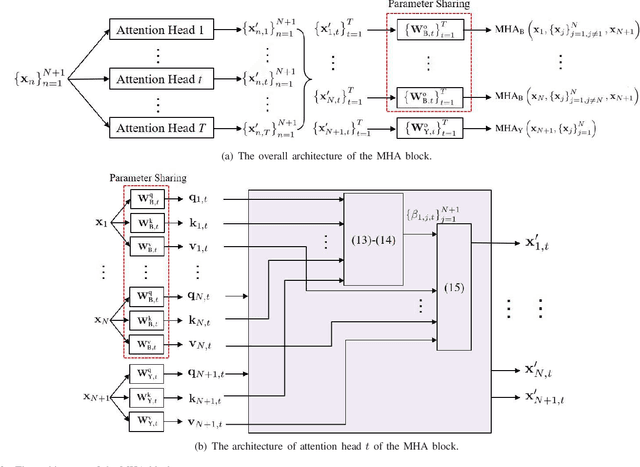
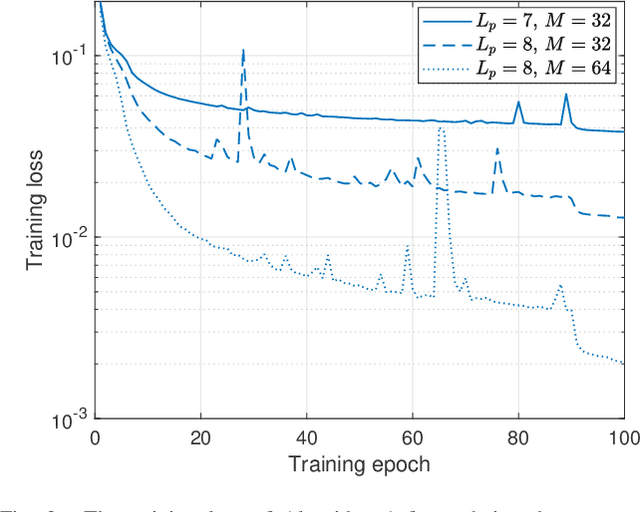
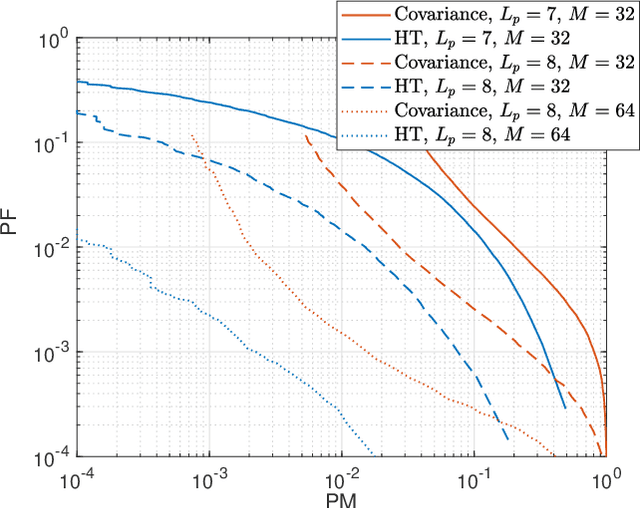
To support the modern machine-type communications, a crucial task during the random access phase is device activity detection, which is to detect the active devices from a large number of potential devices based on the received signal at the access point. By utilizing the statistical properties of the channel, state-of-the-art covariance based methods have been demonstrated to achieve better activity detection performance than compressed sensing based methods. However, covariance based methods require to solve a high dimensional nonconvex optimization problem by updating the estimate of the activity status of each device sequentially. Since the number of updates is proportional to the device number, the computational complexity and delay make the iterative updates difficult for real-time implementation especially when the device number scales up. Inspired by the success of deep learning for real-time inference, this paper proposes a learning based method with a customized heterogeneous transformer architecture for device activity detection. By adopting an attention mechanism in the architecture design, the proposed method is able to extract the relevance between device pilots and received signal, is permutation equivariant with respect to devices, and is scale adaptable to different numbers of devices. Simulation results demonstrate that the proposed method achieves better activity detection performance with much shorter computation time than state-of-the-art covariance approach, and generalizes well to different numbers of devices, BS-antennas, and different signal-to-noise ratios.
Contrastive ACE: Domain Generalization Through Alignment of Causal Mechanisms
Jun 02, 2021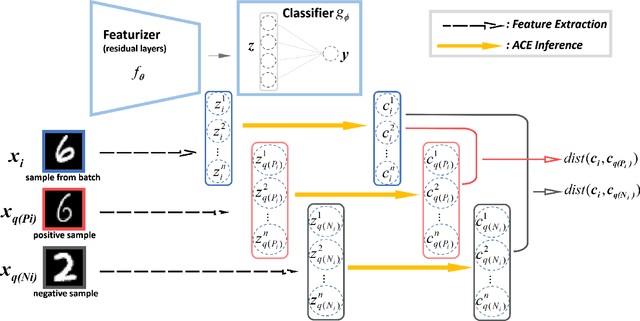
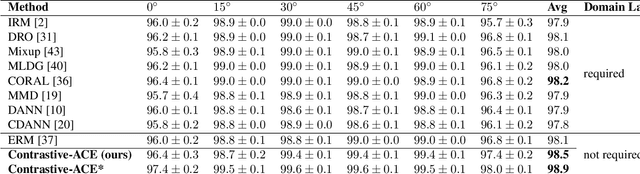
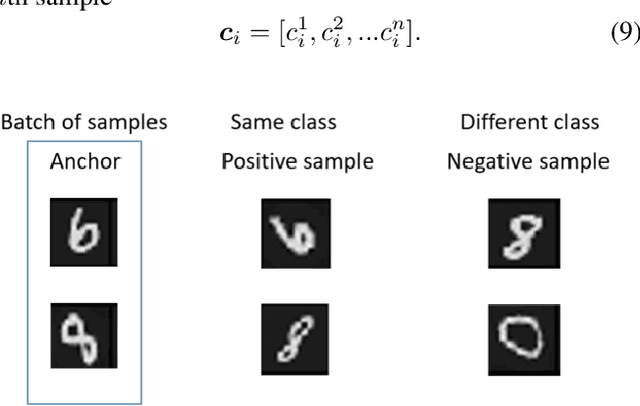
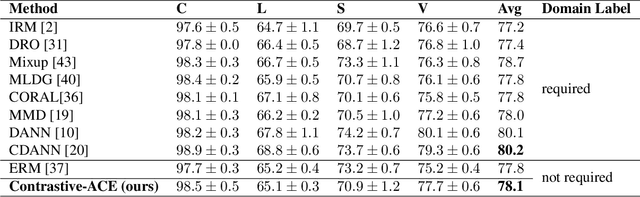
Domain generalization aims to learn knowledge invariant across different distributions while semantically meaningful for downstream tasks from multiple source domains, to improve the model's generalization ability on unseen target domains. The fundamental objective is to understand the underlying "invariance" behind these observational distributions and such invariance has been shown to have a close connection to causality. While many existing approaches make use of the property that causal features are invariant across domains, we consider the causal invariance of the average causal effect of the features to the labels. This invariance regularizes our training approach in which interventions are performed on features to enforce stability of the causal prediction by the classifier across domains. Our work thus sheds some light on the domain generalization problem by introducing invariance of the mechanisms into the learning process. Experiments on several benchmark datasets demonstrate the performance of the proposed method against SOTAs.