 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Knowledge-Enhanced Medical VLP for Chest X-Ray
Apr 23, 2024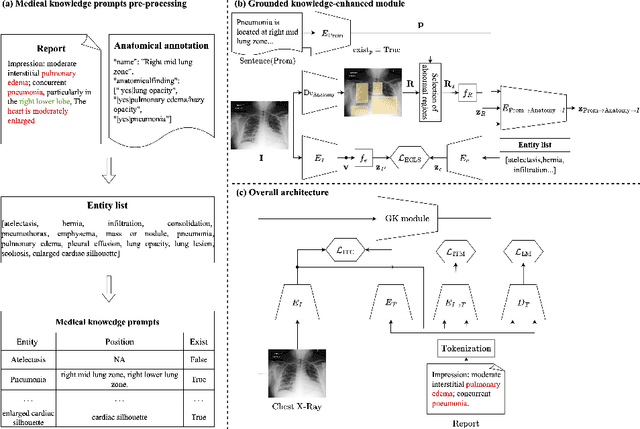
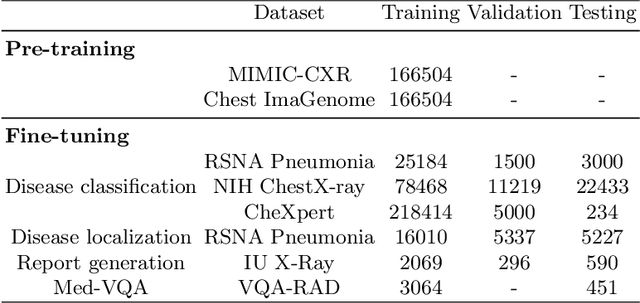
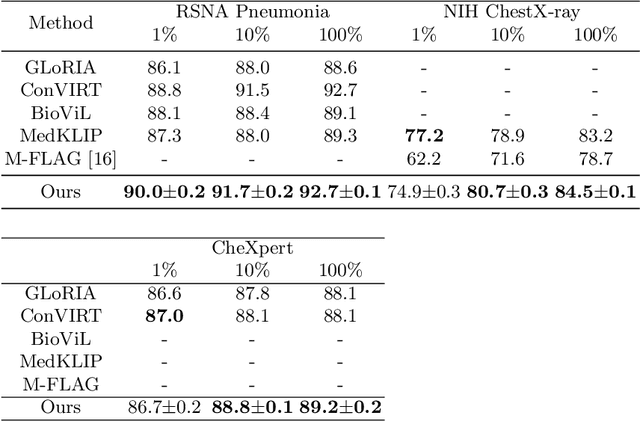
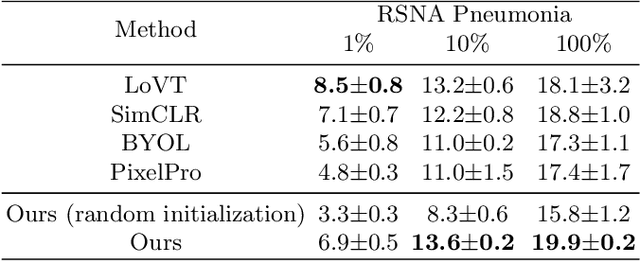
Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.
Research on Efficient Fuzzy Clustering Method Based on Local Fuzzy Granular balls
Mar 08, 2023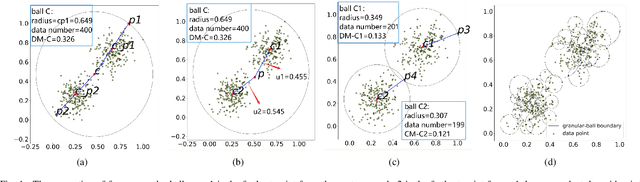

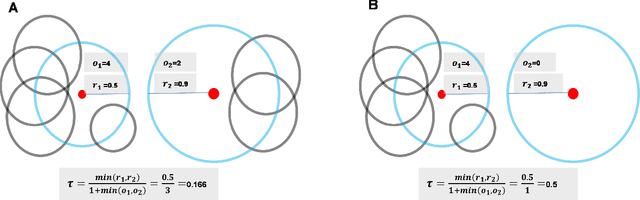

In recent years, the problem of fuzzy clustering has been widely concerned. The membership iteration of existing methods is mostly considered globally, which has considerable problems in noisy environments, and iterative calculations for clusters with a large number of different sample sizes are not accurate and efficient. In this paper, starting from the strategy of large-scale priority, the data is fuzzy iterated using granular-balls, and the membership degree of data only considers the two granular-balls where it is located, thus improving the efficiency of iteration. The formed fuzzy granular-balls set can use more processing methods in the face of different data scenarios, which enhances the practicability of fuzzy clustering calculations.
Fashion Image Retrieval with Multi-Granular Alignment
Feb 27, 2023



Fashion image retrieval task aims to search relevant clothing items of a query image from the gallery. The previous recipes focus on designing different distance-based loss functions, pulling relevant pairs to be close and pushing irrelevant images apart. However, these methods ignore fine-grained features (e.g. neckband, cuff) of clothing images. In this paper, we propose a novel fashion image retrieval method leveraging both global and fine-grained features, dubbed Multi-Granular Alignment (MGA). Specifically, we design a Fine-Granular Aggregator(FGA) to capture and aggregate detailed patterns. Then we propose Attention-based Token Alignment (ATA) to align image features at the multi-granular level in a coarse-to-fine manner. To prove the effectiveness of our proposed method, we conduct experiments on two sub-tasks (In-Shop & Consumer2Shop) of the public fashion datasets DeepFashion. The experimental results show that our MGA outperforms the state-of-the-art methods by 1.8% and 0.6% in the two sub-tasks on the R@1 metric, respectively.
Cascaded Robust Learning at Imperfect Labels for Chest X-ray Segmentation
Apr 05, 2021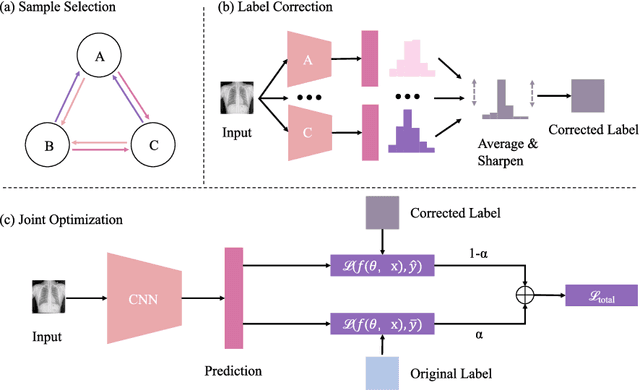
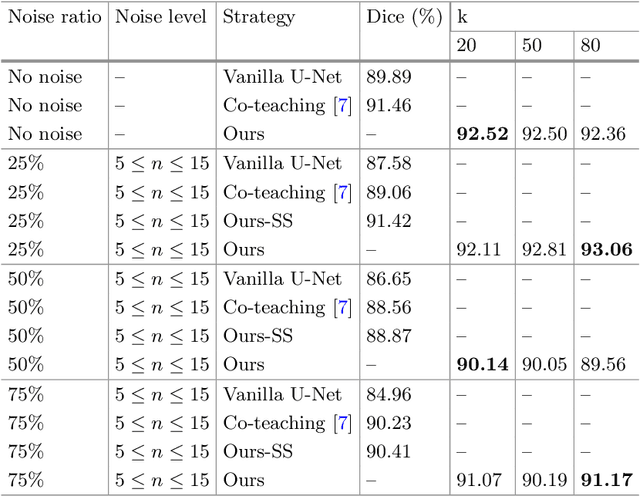

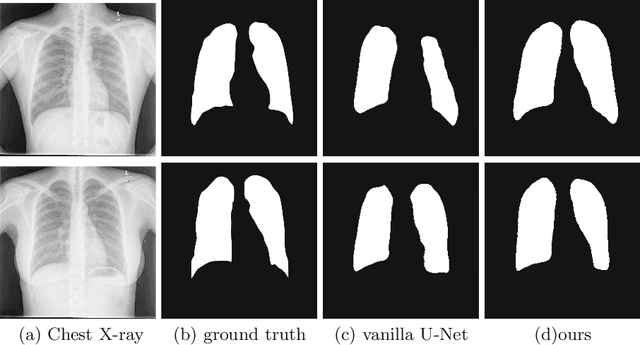
The superior performance of CNN on medical image analysis heavily depends on the annotation quality, such as the number of labeled image, the source of image, and the expert experience. The annotation requires great expertise and labour. To deal with the high inter-rater variability, the study of imperfect label has great significance in medical image segmentation tasks. In this paper, we present a novel cascaded robust learning framework for chest X-ray segmentation with imperfect annotation. Our model consists of three independent network, which can effectively learn useful information from the peer networks. The framework includes two stages. In the first stage, we select the clean annotated samples via a model committee setting, the networks are trained by minimizing a segmentation loss using the selected clean samples. In the second stage, we design a joint optimization framework with label correction to gradually correct the wrong annotation and improve the network performance. We conduct experiments on the public chest X-ray image datasets collected by Shenzhen Hospital. The results show that our methods could achieve a significant improvement on the accuracy in segmentation tasks compared to the previous methods.