 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliberation on Priors: Trustworthy Reasoning of Large Language Models on Knowledge Graphs
May 21, 2025Knowledge graph-based retrieval-augmented generation seeks to mitigate hallucinations in Large Language Models (LLMs) caused by insufficient or outdated knowledge. However, existing methods often fail to fully exploit the prior knowledge embedded in knowledge graphs (KGs), particularly their structural information and explicit or implicit constraints. The former can enhance the faithfulness of LLMs' reasoning, while the latter can improve the reliability of response generation. Motivated by these, we propose a trustworthy reasoning framework, termed Deliberation over Priors (DP), which sufficiently utilizes the priors contained in KGs. Specifically, DP adopts a progressive knowledge distillation strategy that integrates structural priors into LLMs through a combination of supervised fine-tuning and Kahneman-Tversky optimization, thereby improving the faithfulness of relation path generation. Furthermore, our framework employs a reasoning-introspection strategy, which guides LLMs to perform refined reasoning verification based on extracted constraint priors, ensuring the reliability of response generation. Extensive experiments on three benchmark datasets demonstrate that DP achieves new state-of-the-art performance, especially a Hit@1 improvement of 13% on the ComplexWebQuestions dataset, and generates highly trustworthy responses. We also conduct various analyses to verify its flexibility and practicality. The code is available at https://github.com/reml-group/Deliberation-on-Priors.
GBCT: An Efficient and Adaptive Granular-Ball Clustering Algorithm for Complex Data
Oct 17, 2024
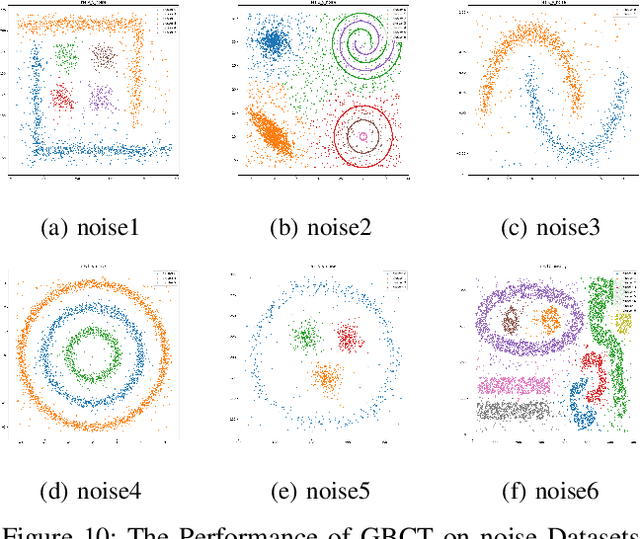
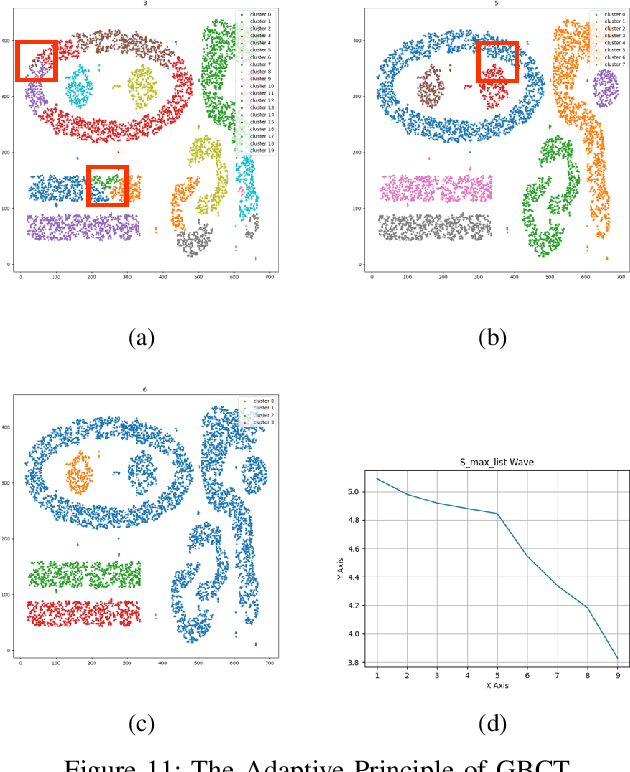
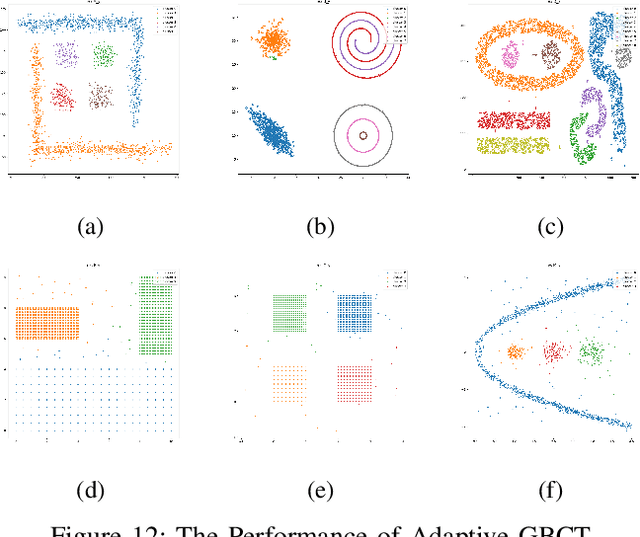
Traditional clustering algorithms often focus on the most fine-grained information and achieve clustering by calculating the distance between each pair of data points or implementing other calculations based on points. This way is not inconsistent with the cognitive mechanism of "global precedence" in human brain, resulting in those methods' bad performance in efficiency, generalization ability and robustness. To address this problem, we propose a new clustering algorithm called granular-ball clustering (GBCT) via granular-ball computing. Firstly, GBCT generates a smaller number of granular-balls to represent the original data, and forms clusters according to the relationship between granular-balls, instead of the traditional point relationship. At the same time, its coarse-grained characteristics are not susceptible to noise, and the algorithm is efficient and robust; besides, as granular-balls can fit various complex data, GBCT performs much better in non-spherical data sets than other traditional clustering methods. The completely new coarse granularity representation method of GBCT and cluster formation mode can also used to improve other traditional methods.
A Performance Analysis Modeling Framework for Extended Reality Applications in Edge-Assisted Wireless Networks
May 11, 2024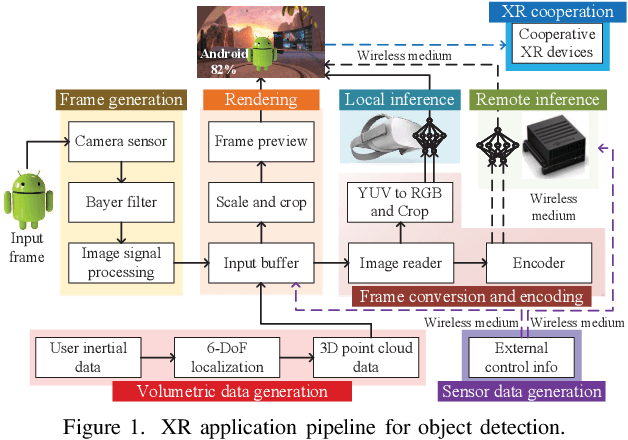
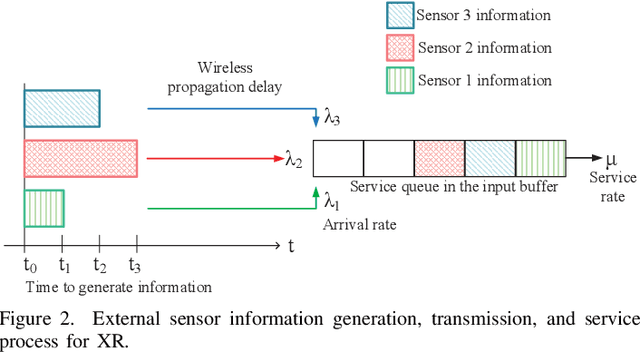
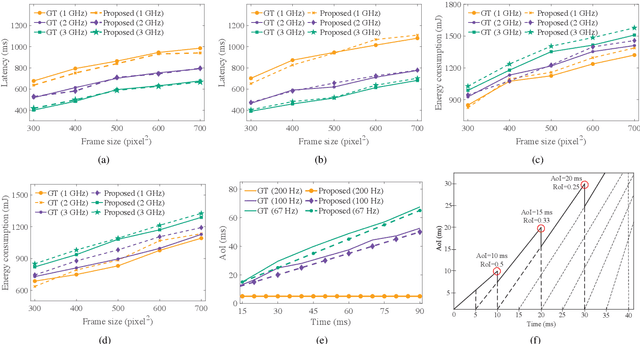
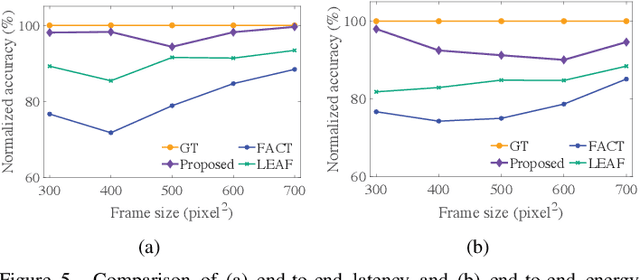
Extended reality (XR) is at the center of attraction in the research community due to the emergence of augmented, mixed, and virtual reality applications. The performance of such applications needs to be uptight to maintain the requirements of latency, energy consumption, and freshness of data. Therefore, a comprehensive performance analysis model is required to assess the effectiveness of an XR application but is challenging to design due to the dependence of the performance metrics on several difficult-to-model parameters, such as computing resources and hardware utilization of XR and edge devices, which are controlled by both their operating systems and the application itself. Moreover, the heterogeneity in devices and wireless access networks brings additional challenges in modeling. In this paper, we propose a novel modeling framework for performance analysis of XR applications considering edge-assisted wireless networks and validate the model with experimental data collected from testbeds designed specifically for XR applications. In addition, we present the challenges associated with performance analysis modeling and present methods to overcome them in detail. Finally, the performance evaluation shows that the proposed analytical model can analyze XR applications' performance with high accuracy compared to the state-of-the-art analytical models.
DeepEn2023: Energy Datasets for Edge Artificial Intelligence
Nov 30, 2023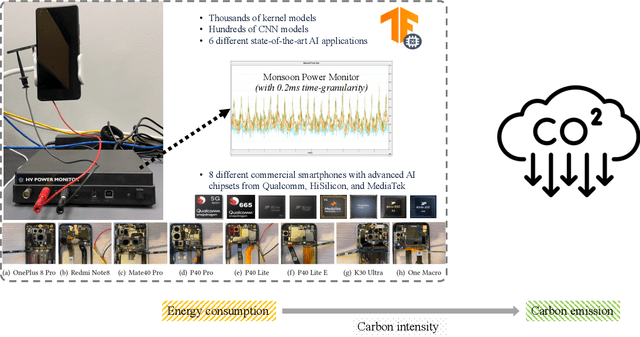

Climate change poses one of the most significant challenges to humanity. As a result of these climatic changes, the frequency of weather, climate, and water-related disasters has multiplied fivefold over the past 50 years, resulting in over 2 million deaths and losses exceeding $3.64 trillion USD. Leveraging AI-powered technologies for sustainable development and combating climate change is a promising avenue. Numerous significant publications are dedicated to using AI to improve renewable energy forecasting, enhance waste management, and monitor environmental changes in real time. However, very few research studies focus on making AI itself environmentally sustainable. This oversight regarding the sustainability of AI within the field might be attributed to a mindset gap and the absence of comprehensive energy datasets. In addition, with the ubiquity of edge AI systems and applications, especially on-device learning, there is a pressing need to measure, analyze, and optimize their environmental sustainability, such as energy efficiency. To this end, in this paper, we propose large-scale energy datasets for edge AI, named DeepEn2023, covering a wide range of kernels, state-of-the-art deep neural network models, and popular edge AI applications. We anticipate that DeepEn2023 will improve transparency in sustainability in on-device deep learning across a range of edge AI systems and applications. For more information, including access to the dataset and code, please visit https://amai-gsu.github.io/DeepEn2023.
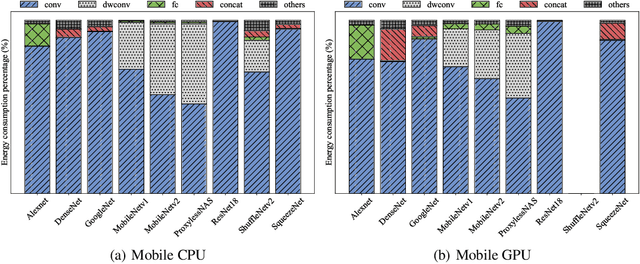
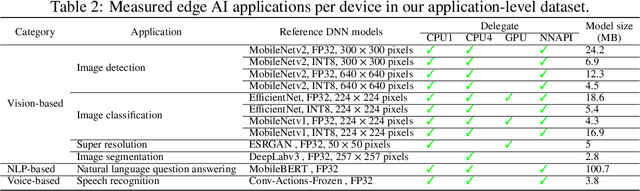
Unveiling Energy Efficiency in Deep Learning: Measurement, Prediction, and Scoring across Edge Devices
Oct 19, 2023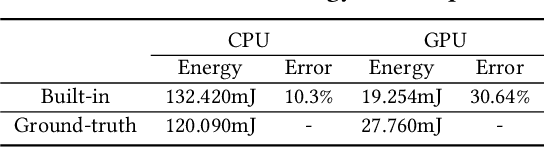

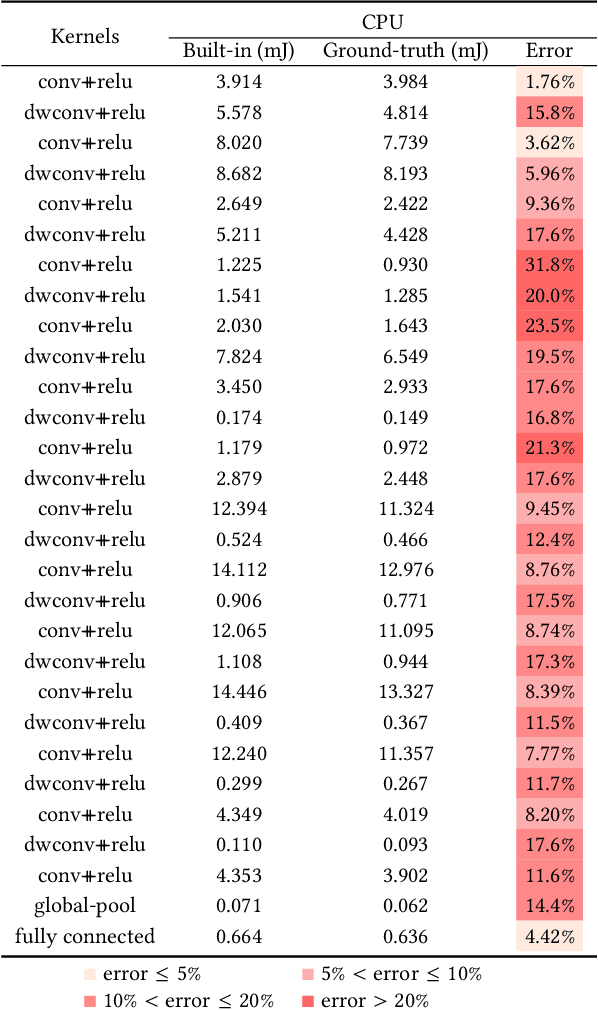
Today, deep learning optimization is primarily driven by research focused on achieving high inference accuracy and reducing latency. However, the energy efficiency aspect is often overlooked, possibly due to a lack of sustainability mindset in the field and the absence of a holistic energy dataset. In this paper, we conduct a threefold study, including energy measurement, prediction, and efficiency scoring, with an objective to foster transparency in power and energy consumption within deep learning across various edge devices. Firstly, we present a detailed, first-of-its-kind measurement study that uncovers the energy consumption characteristics of on-device deep learning. This study results in the creation of three extensive energy datasets for edge devices, covering a wide range of kernels, state-of-the-art DNN models, and popular AI applications. Secondly, we design and implement the first kernel-level energy predictors for edge devices based on our kernel-level energy dataset. Evaluation results demonstrate the ability of our predictors to provide consistent and accurate energy estimations on unseen DNN models. Lastly, we introduce two scoring metrics, PCS and IECS, developed to convert complex power and energy consumption data of an edge device into an easily understandable manner for edge device end-users. We hope our work can help shift the mindset of both end-users and the research community towards sustainability in edge computing, a principle that drives our research. Find data, code, and more up-to-date information at https://amai-gsu.github.io/DeepEn2023.
Listen to Minority: Encrypted Traffic Classification for Class Imbalance with Contrastive Pre-Training
Sep 06, 2023

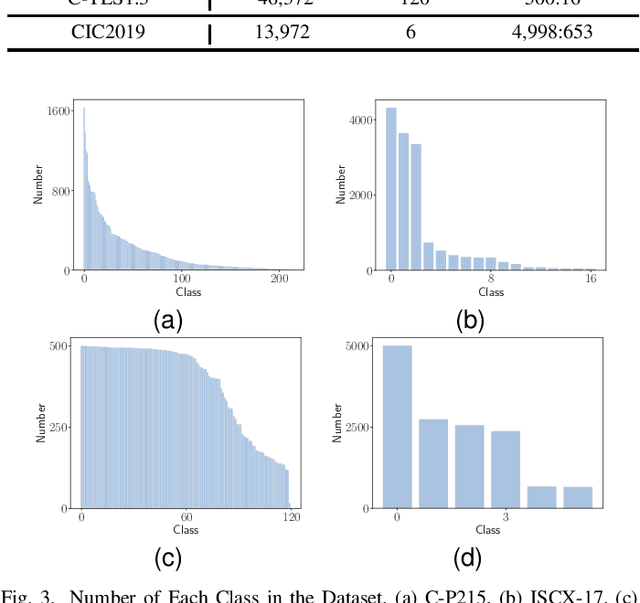
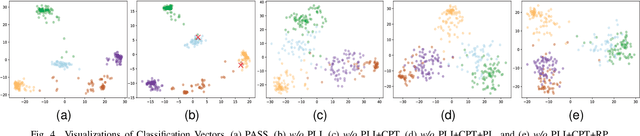
Mobile Internet has profoundly reshaped modern lifestyles in various aspects. Encrypted Traffic Classification (ETC) naturally plays a crucial role in managing mobile Internet, especially with the explosive growth of mobile apps using encrypted communication. Despite some existing learning-based ETC methods showing promising results, three-fold limitations still remain in real-world network environments, 1) label bias caused by traffic class imbalance, 2) traffic homogeneity caused by component sharing, and 3) training with reliance on sufficient labeled traffic. None of the existing ETC methods can address all these limitations. In this paper, we propose a novel Pre-trAining Semi-Supervised ETC framework, dubbed PASS. Our key insight is to resample the original train dataset and perform contrastive pre-training without using individual app labels directly to avoid label bias issues caused by class imbalance, while obtaining a robust feature representation to differentiate overlapping homogeneous traffic by pulling positive traffic pairs closer and pushing negative pairs away. Meanwhile, PASS designs a semi-supervised optimization strategy based on pseudo-label iteration and dynamic loss weighting algorithms in order to effectively utilize massive unlabeled traffic data and alleviate manual train dataset annotation workload. PASS outperforms state-of-the-art ETC methods and generic sampling approaches on four public datasets with significant class imbalance and traffic homogeneity, remarkably pushing the F1 of Cross-Platform215 with 1.31%, ISCX-17 with 9.12%. Furthermore, we validate the generality of the contrastive pre-training and pseudo-label iteration components of PASS, which can adaptively benefit ETC methods with diverse feature extractors.
Research on Efficient Fuzzy Clustering Method Based on Local Fuzzy Granular balls
Mar 08, 2023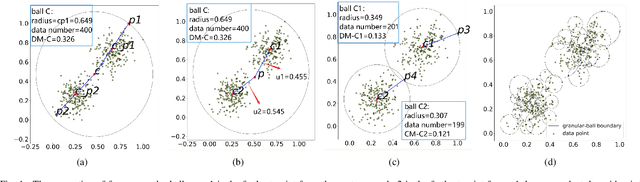


In recent years, the problem of fuzzy clustering has been widely concerned. The membership iteration of existing methods is mostly considered globally, which has considerable problems in noisy environments, and iterative calculations for clusters with a large number of different sample sizes are not accurate and efficient. In this paper, starting from the strategy of large-scale priority, the data is fuzzy iterated using granular-balls, and the membership degree of data only considers the two granular-balls where it is located, thus improving the efficiency of iteration. The formed fuzzy granular-balls set can use more processing methods in the face of different data scenarios, which enhances the practicability of fuzzy clustering calculations.
EPAM: A Predictive Energy Model for Mobile AI
Mar 02, 2023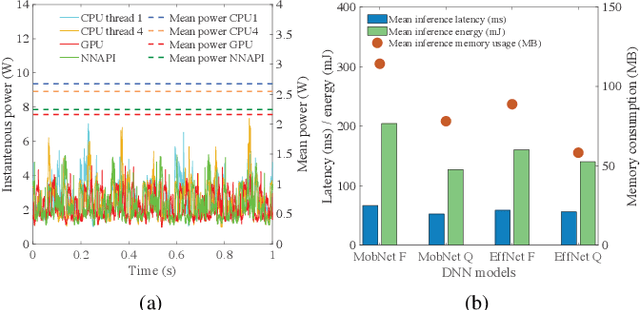
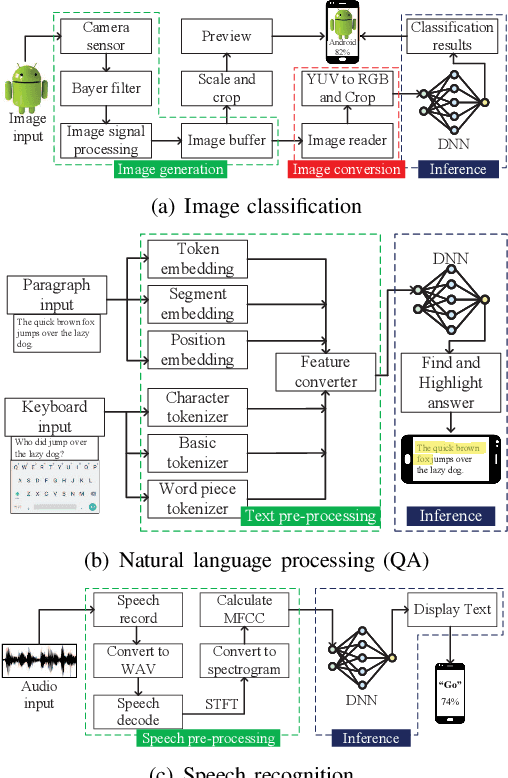
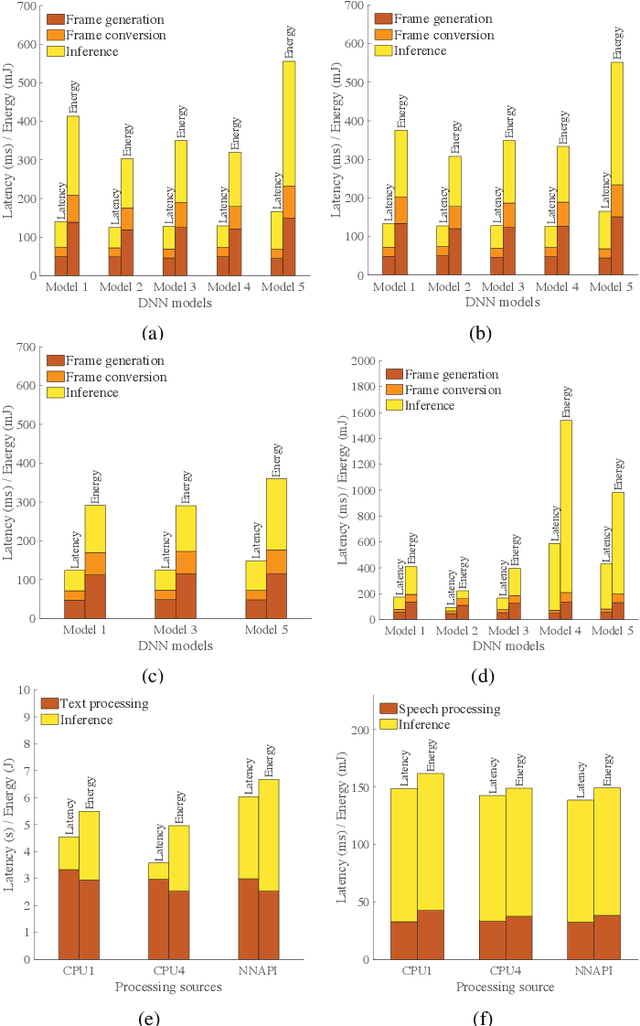
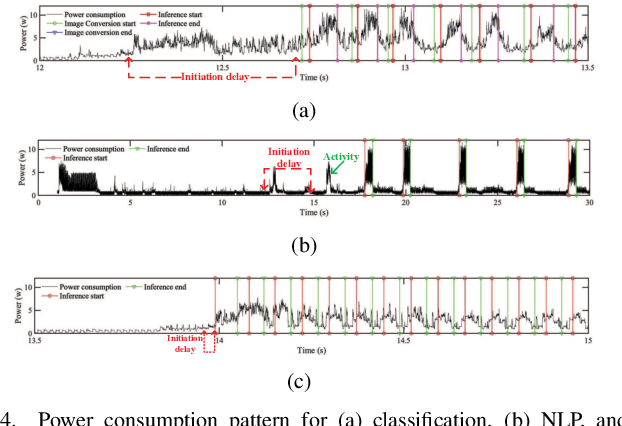
Artificial intelligence (AI) has enabled a new paradigm of smart applications -- changing our way of living entirely. Many of these AI-enabled applications have very stringent latency requirements, especially for applications on mobile devices (e.g., smartphones, wearable devices, and vehicles). Hence, smaller and quantized deep neural network (DNN) models are developed for mobile devices, which provide faster and more energy-efficient computation for mobile AI applications. However, how AI models consume energy in a mobile device is still unexplored. Predicting the energy consumption of these models, along with their different applications, such as vision and non-vision, requires a thorough investigation of their behavior using various processing sources. In this paper, we introduce a comprehensive study of mobile AI applications considering different DNN models and processing sources, focusing on computational resource utilization, delay, and energy consumption. We measure the latency, energy consumption, and memory usage of all the models using four processing sources through extensive experiments. We explain the challenges in such investigations and how we propose to overcome them. Our study highlights important insights, such as how mobile AI behaves in different applications (vision and non-vision) using CPU, GPU, and NNAPI. Finally, we propose a novel Gaussian process regression-based general predictive energy model based on DNN structures, computation resources, and processors, which can predict the energy for each complete application cycle irrespective of device configuration and application. This study provides crucial facts and an energy prediction mechanism to the AI research community to help bring energy efficiency to mobile AI applications.
GBMST: An Efficient Minimum Spanning Tree Clustering Based on Granular-Ball
Mar 02, 2023


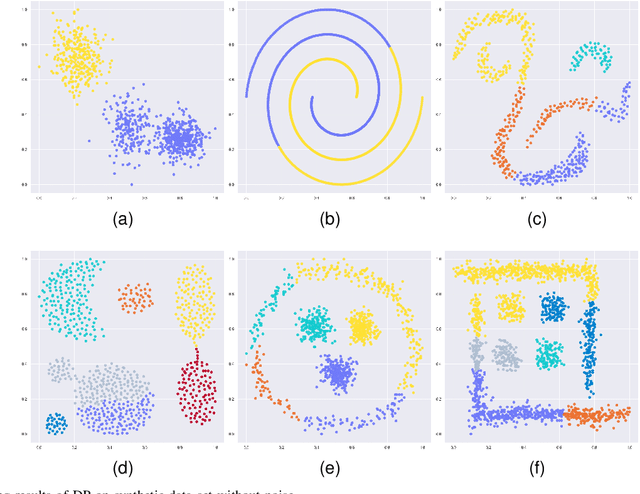
Most of the existing clustering methods are based on a single granularity of information, such as the distance and density of each data. This most fine-grained based approach is usually inefficient and susceptible to noise. Therefore, we propose a clustering algorithm that combines multi-granularity Granular-Ball and minimum spanning tree (MST). We construct coarsegrained granular-balls, and then use granular-balls and MST to implement the clustering method based on "large-scale priority", which can greatly avoid the influence of outliers and accelerate the construction process of MST. Experimental results on several data sets demonstrate the power of the algorithm. All codes have been released at https://github.com/xjnine/GBMST.
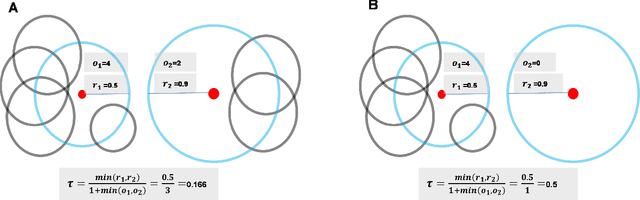
A novel cluster internal evaluation index based on hyper-balls
Dec 30, 2022
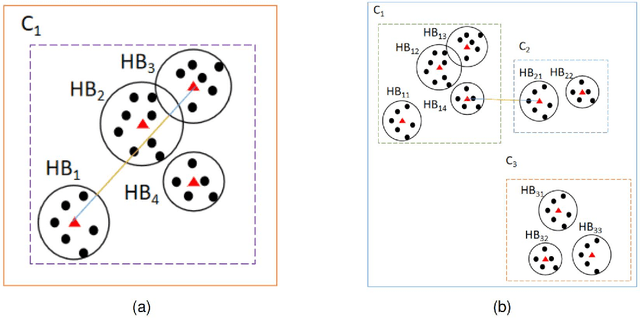

It is crucial to evaluate the quality and determine the optimal number of clusters in cluster analysis. In this paper, the multi-granularity characterization of the data set is carried out to obtain the hyper-balls. The cluster internal evaluation index based on hyper-balls(HCVI) is defined. Moreover, a general method for determining the optimal number of clusters based on HCVI is proposed. The proposed methods can evaluate the clustering results produced by the several classic methods and determine the optimal cluster number for data sets containing noises and clusters with arbitrary shapes. The experimental results on synthetic and real data sets indicate that the new index outperforms existing ones.