 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlloGen: Conformation-Selective Binder Generation with Differential State Scoring
Jun 03, 2026Protein binder design has largely optimized for affinity alone, leaving conformational selectivity unaddressed: for allosteric targets such as kinases, nuclear receptors, and GPCRs, a binder that engages both active and inactive states provides no functional specificity regardless of how tightly it binds. We introduce AlloGen, a modular framework that decouples backbone generation from a learned state-selectivity scorer $Q_θ$, an SE(3)-invariant interface graph transformer trained via a two-phase curriculum that first learns interface geometry before imposing conformational discrimination. Because $Q_θ$ is fully differentiable and generator-agnostic, it integrates with any backbone generator as a passive reranker or an active gradient-based guide without retraining. Across a diverse benchmark of proteins spanning multiple families and conformational mechanisms, AlloGen consistently identifies binders that preferentially recognize desired structural states while rejecting alternative conformations. Experimental validation on calmodulin further demonstrates that these computational selectivity signals translate to physical molecules, yielding de novo peptides that bind the desired holo conformation while exhibiting no detectable binding to the apo state. Together, these results establish conformational selectivity as a learnable property and provide a general framework for state-selective protein binder design.
TD3B: Transition-Directed Discrete Diffusion for Allosteric Binder Generation
May 10, 2026Protein function is often controlled by ligands that bias the direction of state transitions, such as agonists and antagonists, rather than stabilizing a single conformation. This is especially important for clinically relevant G protein-coupled receptors (GPCRs), where therapeutic efficacy depends on functional directionality. Structure-based design methods optimize binding to static conformations and cannot represent non-reversible, directional effects or systematically distinguish agonist from antagonist behavior. To address this gap, we introduce Transition-Directed Discrete Diffusion for Allosteric Binder Design (TD3B), a sequence-based generative framework that designs binders with specified agonist or antagonist behavior via a directional transition control objective. TD3B combines a target-aware Direction Oracle, a soft binding-affinity gate, and amortized fine-tuning of a pre-trained discrete diffusion model, enabling targeted agonist and antagonist generation decoupled from binding affinity and unattainable by equilibrium-based or inference-only guidance baselines. The code and checkpoints are available at https://huggingface.co/ChatterjeeLab/TD3B.
PARM: Pipeline-Adapted Reward Model
Apr 20, 2026Reward models (RMs) are central to aligning large language models (LLMs) with human preferences, powering RLHF and advanced decoding strategies. While most prior work focuses on single-step generation, real-world applications increasingly adopt multi-stage LLM pipelines, where effective reward guidance remains underexplored. We investigate this through code generation for combinatorial optimization, constructing a pipeline that integrates reward models into both formulation and solution stages. We identify a critical challenge: inconsistency between reward model predictions and actual pipeline execution outcomes. To address this, we propose the Pipeline-Adapted Reward Model (PARM), which leverages pipeline-specific data and direct preference optimization to align rewards with downstream feedback. We instantiate PARM as a two-stage pipeline (formulation -> code generation) and evaluate it on four public optimization benchmarks, measuring execution rate and solving accuracy against baselines and sampling methods. A supplementary cross-domain experiment on GSM8K assesses transferability. Results demonstrate that PARM consistently improves pipeline output quality and stability, providing new insights into reward modeling for multi-stage LLM reasoning.
RiboSphere: Learning Unified and Efficient Representations of RNA Structures
Mar 20, 2026Accurate RNA structure modeling remains difficult because RNA backbones are highly flexible, non-canonical interactions are prevalent, and experimentally determined 3D structures are comparatively scarce. We introduce \emph{RiboSphere}, a framework that learns \emph{discrete} geometric representations of RNA by combining vector quantization with flow matching. Our design is motivated by the modular organization of RNA architecture: complex folds are composed from recurring structural motifs. RiboSphere uses a geometric transformer encoder to produce SE(3)-invariant (rotation/translation-invariant) features, which are discretized with finite scalar quantization (FSQ) into a finite vocabulary of latent codes. Conditioned on these discrete codes, a flow-matching decoder reconstructs atomic coordinates, enabling high-fidelity structure generation. We find that the learned code indices are enriched for specific RNA motifs, suggesting that the model captures motif-level compositional structure rather than acting as a purely compressive bottleneck. Across benchmarks, RiboSphere achieves strong performance in structure reconstruction (RMSD 1.25\,Å, TM-score 0.84), and its pretrained discrete representations transfer effectively to inverse folding and RNA--ligand binding prediction, with robust generalization in data-scarce regimes.
Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer
Feb 04, 2025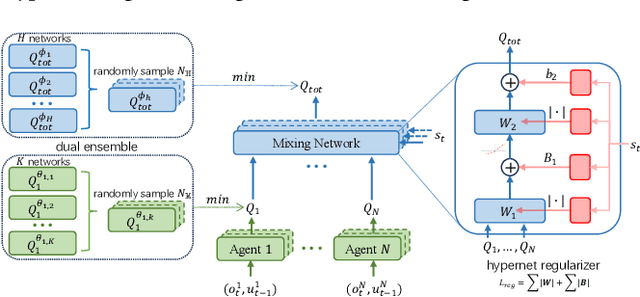
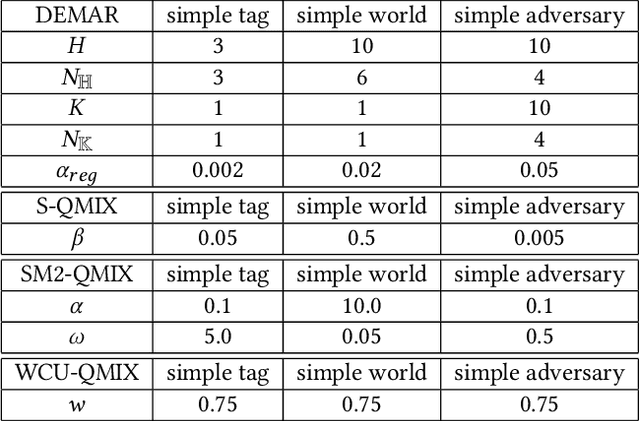
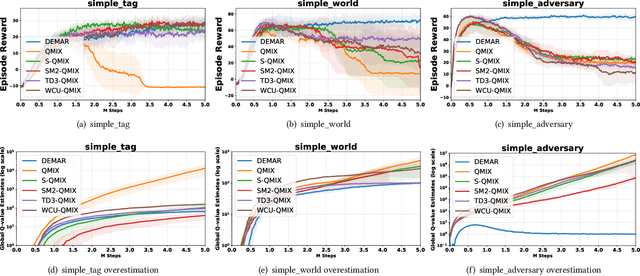
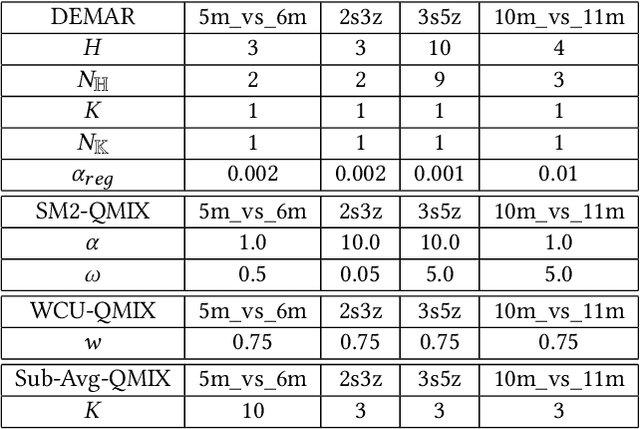
Overestimation in single-agent reinforcement learning has been extensively studied. In contrast, overestimation in the multiagent setting has received comparatively little attention although it increases with the number of agents and leads to severe learning instability. Previous works concentrate on reducing overestimation in the estimation process of target Q-value. They ignore the follow-up optimization process of online Q-network, thus making it hard to fully address the complex multiagent overestimation problem. To solve this challenge, in this study, we first establish an iterative estimation-optimization analysis framework for multiagent value-mixing Q-learning. Our analysis reveals that multiagent overestimation not only comes from the computation of target Q-value but also accumulates in the online Q-network's optimization. Motivated by it, we propose the Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer algorithm to tackle multiagent overestimation from two aspects. First, we extend the random ensemble technique into the estimation of target individual and global Q-values to derive a lower update target. Second, we propose a novel hypernet regularizer on hypernetwork weights and biases to constrain the optimization of online global Q-network to prevent overestimation accumulation. Extensive experiments in MPE and SMAC show that the proposed method successfully addresses overestimation across various tasks.
SeaDAG: Semi-autoregressive Diffusion for Conditional Directed Acyclic Graph Generation
Oct 21, 2024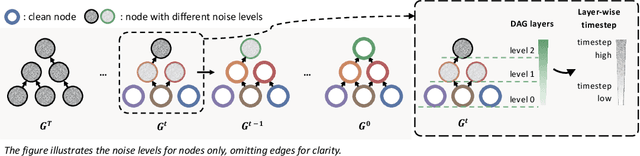
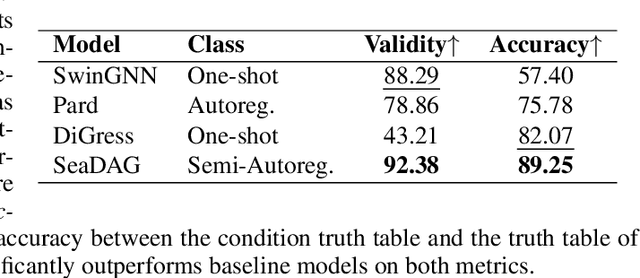
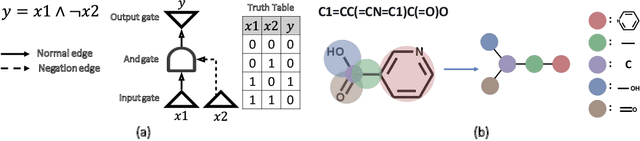
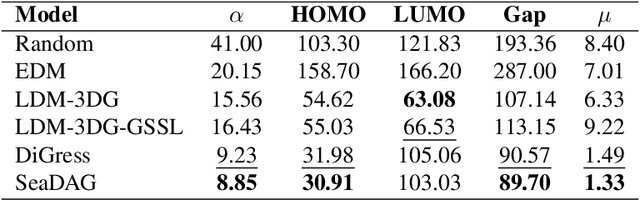
We introduce SeaDAG, a semi-autoregressive diffusion model for conditional generation of Directed Acyclic Graphs (DAGs). Considering their inherent layer-wise structure, we simulate layer-wise autoregressive generation by designing different denoising speed for different layers. Unlike conventional autoregressive generation that lacks a global graph structure view, our method maintains a complete graph structure at each diffusion step, enabling operations such as property control that require the full graph structure. Leveraging this capability, we evaluate the DAG properties during training by employing a graph property decoder. We explicitly train the model to learn graph conditioning with a condition loss, which enhances the diffusion model's capacity to generate graphs that are both realistic and aligned with specified properties. We evaluate our method on two representative conditional DAG generation tasks: (1) circuit generation from truth tables, where precise DAG structures are crucial for realizing circuit functionality, and (2) molecule generation based on quantum properties. Our approach demonstrates promising results, generating high-quality and realistic DAGs that closely align with given conditions.
Unlocking Potential Binders: Multimodal Pretraining DEL-Fusion for Denoising DNA-Encoded Libraries
Sep 07, 2024



In the realm of drug discovery, DNA-encoded library (DEL) screening technology has emerged as an efficient method for identifying high-affinity compounds. However, DEL screening faces a significant challenge: noise arising from nonspecific interactions within complex biological systems. Neural networks trained on DEL libraries have been employed to extract compound features, aiming to denoise the data and uncover potential binders to the desired therapeutic target. Nevertheless, the inherent structure of DEL, constrained by the limited diversity of building blocks, impacts the performance of compound encoders. Moreover, existing methods only capture compound features at a single level, further limiting the effectiveness of the denoising strategy. To mitigate these issues, we propose a Multimodal Pretraining DEL-Fusion model (MPDF) that enhances encoder capabilities through pretraining and integrates compound features across various scales. We develop pretraining tasks applying contrastive objectives between different compound representations and their text descriptions, enhancing the compound encoders' ability to acquire generic features. Furthermore, we propose a novel DEL-fusion framework that amalgamates compound information at the atomic, submolecular, and molecular levels, as captured by various compound encoders. The synergy of these innovations equips MPDF with enriched, multi-scale features, enabling comprehensive downstream denoising. Evaluated on three DEL datasets, MPDF demonstrates superior performance in data processing and analysis for validation tasks. Notably, MPDF offers novel insights into identifying high-affinity molecules, paving the way for improved DEL utility in drug discovery.
Unveiling the Generalization Power of Fine-Tuned Large Language Models
Mar 14, 2024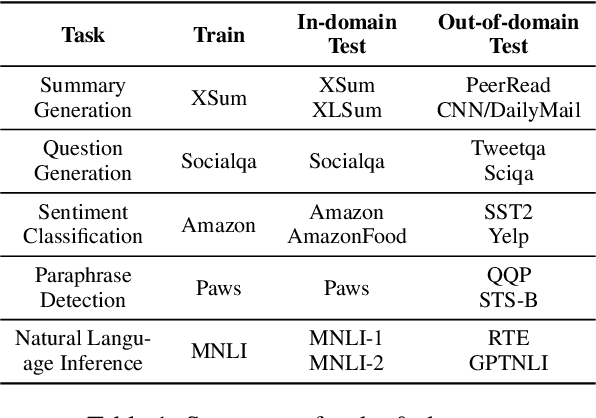
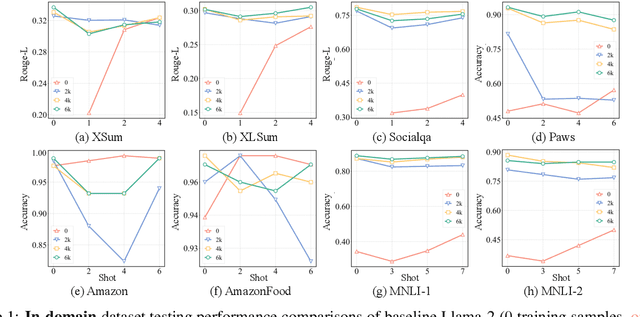
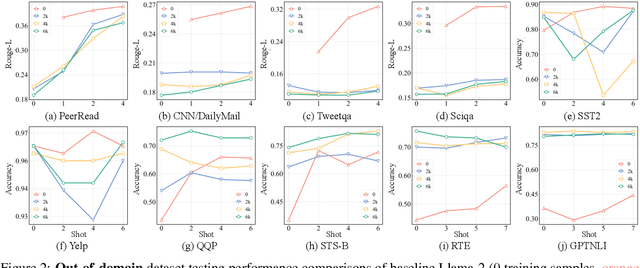
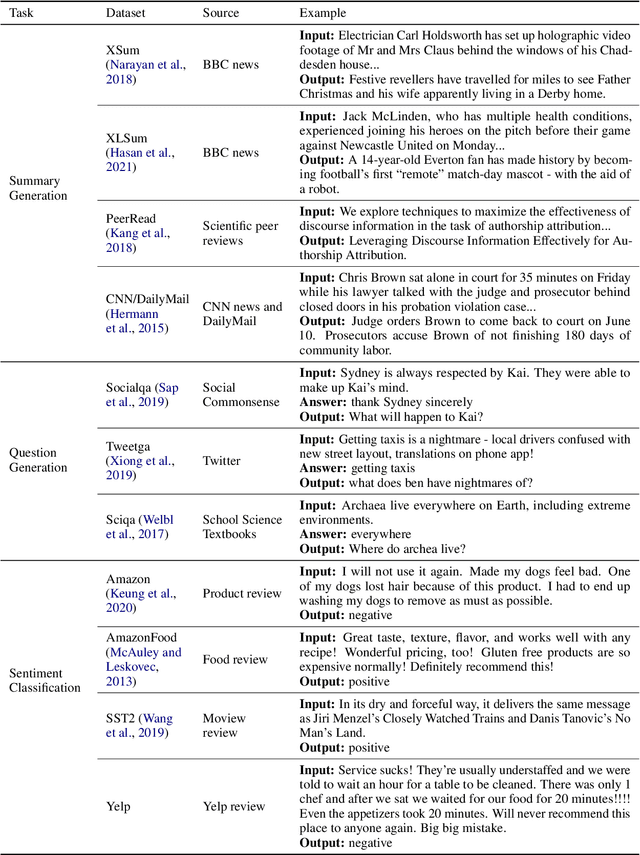
While Large Language Models (LLMs) have demonstrated exceptional multitasking abilities, fine-tuning these models on downstream, domain-specific datasets is often necessary to yield superior performance on test sets compared to their counterparts without fine-tuning. However, the comprehensive effects of fine-tuning on the LLMs' generalization ability are not fully understood. This paper delves into the differences between original, unmodified LLMs and their fine-tuned variants. Our primary investigation centers on whether fine-tuning affects the generalization ability intrinsic to LLMs. To elaborate on this, we conduct extensive experiments across five distinct language tasks on various datasets. Our main findings reveal that models fine-tuned on generation and classification tasks exhibit dissimilar behaviors in generalizing to different domains and tasks. Intriguingly, we observe that integrating the in-context learning strategy during fine-tuning on generation tasks can enhance the model's generalization ability. Through this systematic investigation, we aim to contribute valuable insights into the evolving landscape of fine-tuning practices for LLMs.
An Autonomous Large Language Model Agent for Chemical Literature Data Mining
Feb 20, 2024



Chemical synthesis, which is crucial for advancing material synthesis and drug discovery, impacts various sectors including environmental science and healthcare. The rise of technology in chemistry has generated extensive chemical data, challenging researchers to discern patterns and refine synthesis processes. Artificial intelligence (AI) helps by analyzing data to optimize synthesis and increase yields. However, AI faces challenges in processing literature data due to the unstructured format and diverse writing style of chemical literature. To overcome these difficulties, we introduce an end-to-end AI agent framework capable of high-fidelity extraction from extensive chemical literature. This AI agent employs large language models (LLMs) for prompt generation and iterative optimization. It functions as a chemistry assistant, automating data collection and analysis, thereby saving manpower and enhancing performance. Our framework's efficacy is evaluated using accuracy, recall, and F1 score of reaction condition data, and we compared our method with human experts in terms of content correctness and time efficiency. The proposed approach marks a significant advancement in automating chemical literature extraction and demonstrates the potential for AI to revolutionize data management and utilization in chemistry.
A Survey of Reasoning with Foundation Models
Dec 26, 2023

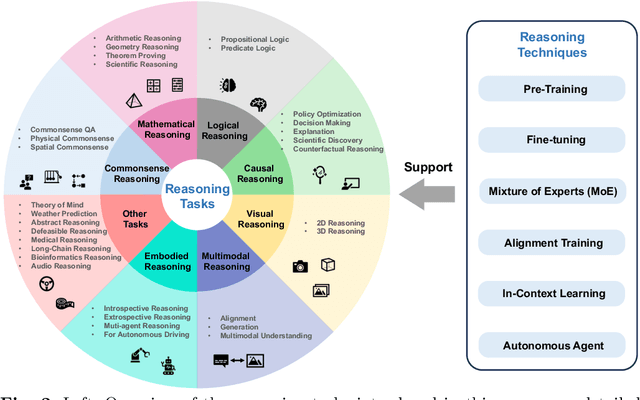

Reasoning, a crucial ability for complex problem-solving, plays a pivotal role in various real-world settings such as negotiation, medical diagnosis, and criminal investigation. It serves as a fundamental methodology in the field of Artificial General Intelligence (AGI). With the ongoing development of foundation models, there is a growing interest in exploring their abilities in reasoning tasks. In this paper, we introduce seminal foundation models proposed or adaptable for reasoning, highlighting the latest advancements in various reasoning tasks, methods, and benchmarks. We then delve into the potential future directions behind the emergence of reasoning abilities within foundation models. We also discuss the relevance of multimodal learning, autonomous agents, and super alignment in the context of reasoning. By discussing these future research directions, we hope to inspire researchers in their exploration of this field, stimulate further advancements in reasoning with foundation models, and contribute to the development of AGI.