 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Ensembled Multiagent Q-Learning with Hypernet Regularizer
Feb 04, 2025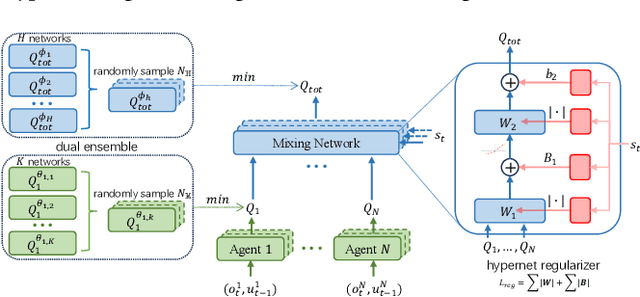
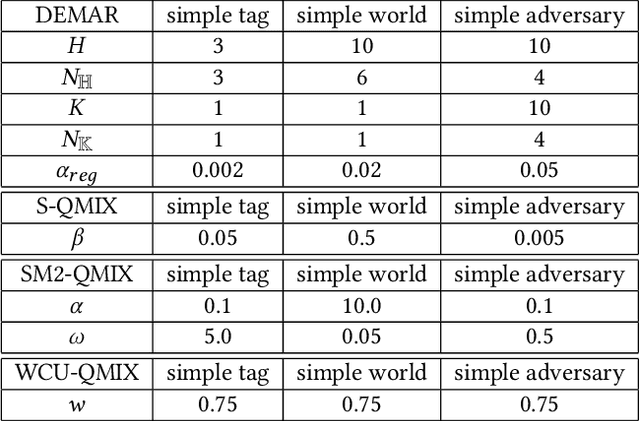
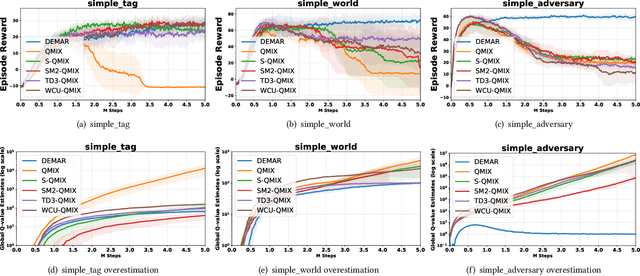
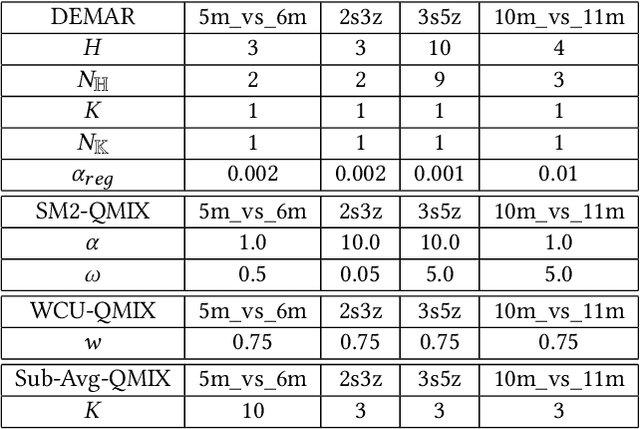
Overestimation in single-agent reinforcement learning has been extensively studied. In contrast, overestimation in the multiagent setting has received comparatively little attention although it increases with the number of agents and leads to severe learning instability. Previous works concentrate on reducing overestimation in the estimation process of target Q-value. They ignore the follow-up optimization process of online Q-network, thus making it hard to fully address the complex multiagent overestimation problem. To solve this challenge, in this study, we first establish an iterative estimation-optimization analysis framework for multiagent value-mixing Q-learning. Our analysis reveals that multiagent overestimation not only comes from the computation of target Q-value but also accumulates in the online Q-network's optimization. Motivated by it, we propose the Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer algorithm to tackle multiagent overestimation from two aspects. First, we extend the random ensemble technique into the estimation of target individual and global Q-values to derive a lower update target. Second, we propose a novel hypernet regularizer on hypernetwork weights and biases to constrain the optimization of online global Q-network to prevent overestimation accumulation. Extensive experiments in MPE and SMAC show that the proposed method successfully addresses overestimation across various tasks.
Adaptive Negative Evidential Deep Learning for Open-set Semi-supervised Learning
Mar 21, 2023



Semi-supervised learning (SSL) methods assume that labeled data, unlabeled data and test data are from the same distribution. Open-set semi-supervised learning (Open-set SSL) considers a more practical scenario, where unlabeled data and test data contain new categories (outliers) not observed in labeled data (inliers). Most previous works focused on outlier detection via binary classifiers, which suffer from insufficient scalability and inability to distinguish different types of uncertainty. In this paper, we propose a novel framework, Adaptive Negative Evidential Deep Learning (ANEDL) to tackle these limitations. Concretely, we first introduce evidential deep learning (EDL) as an outlier detector to quantify different types of uncertainty, and design different uncertainty metrics for self-training and inference. Furthermore, we propose a novel adaptive negative optimization strategy, making EDL more tailored to the unlabeled dataset containing both inliers and outliers. As demonstrated empirically, our proposed method outperforms existing state-of-the-art methods across four datasets.
Uncertainty Estimation by Fisher Information-based Evidential Deep Learning
Mar 13, 2023



Uncertainty estimation is a key factor that makes deep learning reliable in practical applications. Recently proposed evidential neural networks explicitly account for different uncertainties by treating the network's outputs as evidence to parameterize the Dirichlet distribution, and achieve impressive performance in uncertainty estimation. However, for high data uncertainty samples but annotated with the one-hot label, the evidence-learning process for those mislabeled classes is over-penalized and remains hindered. To address this problem, we propose a novel method, Fisher Information-based Evidential Deep Learning ($\mathcal{I}$-EDL). In particular, we introduce Fisher Information Matrix (FIM) to measure the informativeness of evidence carried by each sample, according to which we can dynamically reweight the objective loss terms to make the network more focused on the representation learning of uncertain classes. The generalization ability of our network is further improved by optimizing the PAC-Bayesian bound. As demonstrated empirically, our proposed method consistently outperforms traditional EDL-related algorithms in multiple uncertainty estimation tasks, especially in the more challenging few-shot classification settings.
Flattening Sharpness for Dynamic Gradient Projection Memory Benefits Continual Learning
Oct 09, 2021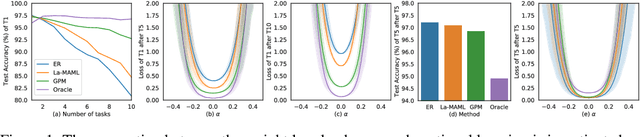
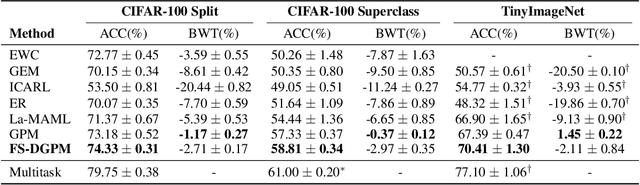
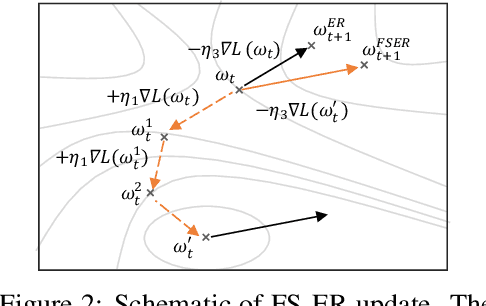
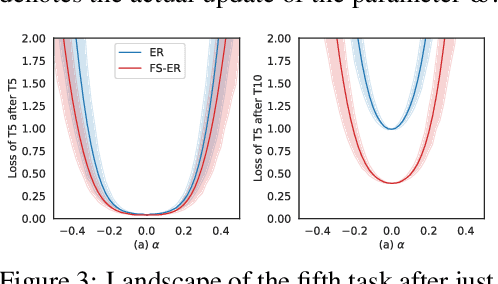
The backpropagation networks are notably susceptible to catastrophic forgetting, where networks tend to forget previously learned skills upon learning new ones. To address such the 'sensitivity-stability' dilemma, most previous efforts have been contributed to minimizing the empirical risk with different parameter regularization terms and episodic memory, but rarely exploring the usages of the weight loss landscape. In this paper, we investigate the relationship between the weight loss landscape and sensitivity-stability in the continual learning scenario, based on which, we propose a novel method, Flattening Sharpness for Dynamic Gradient Projection Memory (FS-DGPM). In particular, we introduce a soft weight to represent the importance of each basis representing past tasks in GPM, which can be adaptively learned during the learning process, so that less important bases can be dynamically released to improve the sensitivity of new skill learning. We further introduce Flattening Sharpness (FS) to reduce the generalization gap by explicitly regulating the flatness of the weight loss landscape of all seen tasks. As demonstrated empirically, our proposed method consistently outperforms baselines with the superior ability to learn new skills while alleviating forgetting effectively.