 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting In-Silicon Directed Evolution with Fine-Tuned Protein Language Model and Tree Search
Nov 19, 2025Protein evolution through amino acid sequence mutations is a cornerstone of life sciences. While current in-silicon directed evolution algorithms largely focus on designing heuristic search strategies, they overlook how to integrate the transformative protein language models, which encode rich evolutionary patterns, with reinforcement learning to learn to directly evolve proteins. To bridge this gap, we propose AlphaDE, a novel framework to optimize protein sequences by harnessing the innovative paradigms of large language models such as fine-tuning and test-time inference. First, AlphaDE fine-tunes pretrained protein language models using masked language modeling on homologous protein sequences to activate the evolutionary plausibility for the interested protein class. Second, AlphaDE introduces test-time inference based on Monte Carlo tree search, which effectively evolves proteins with evolutionary guidance from the fine-tuned protein language model. Extensive benchmark experiments show that AlphaDE remarkably outperforms previous state-of-the-art methods even with few-shot fine-tuning. A further case study demonstrates that AlphaDE supports condensing the protein sequence space of avGFP through computational evolution.
Excavate the potential of Single-Scale Features: A Decomposition Network for Water-Related Optical Image Enhancement
Aug 06, 2025Underwater image enhancement (UIE) techniques aim to improve visual quality of images captured in aquatic environments by addressing degradation issues caused by light absorption and scattering effects, including color distortion, blurring, and low contrast. Current mainstream solutions predominantly employ multi-scale feature extraction (MSFE) mechanisms to enhance reconstruction quality through multi-resolution feature fusion. However, our extensive experiments demonstrate that high-quality image reconstruction does not necessarily rely on multi-scale feature fusion. Contrary to popular belief, our experiments show that single-scale feature extraction alone can match or surpass the performance of multi-scale methods, significantly reducing complexity. To comprehensively explore single-scale feature potential in underwater enhancement, we propose an innovative Single-Scale Decomposition Network (SSD-Net). This architecture introduces an asymmetrical decomposition mechanism that disentangles input image into clean layer along with degradation layer. The former contains scene-intrinsic information and the latter encodes medium-induced interference. It uniquely combines CNN's local feature extraction capabilities with Transformer's global modeling strengths through two core modules: 1) Parallel Feature Decomposition Block (PFDB), implementing dual-branch feature space decoupling via efficient attention operations and adaptive sparse transformer; 2) Bidirectional Feature Communication Block (BFCB), enabling cross-layer residual interactions for complementary feature mining and fusion. This synergistic design preserves feature decomposition independence while establishing dynamic cross-layer information pathways, effectively enhancing degradation decoupling capacity.
Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer
Feb 04, 2025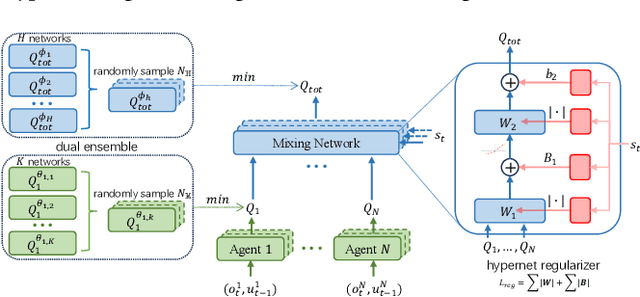
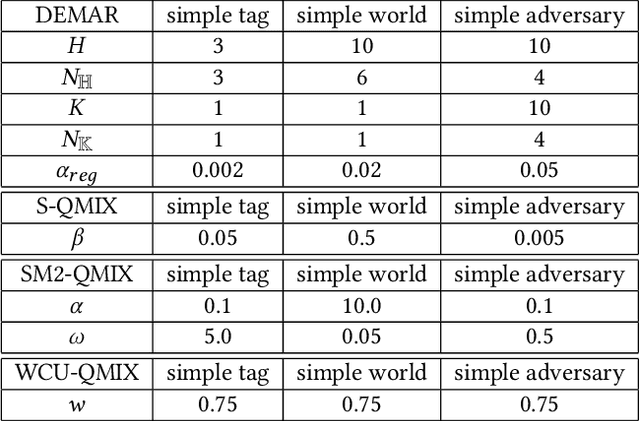
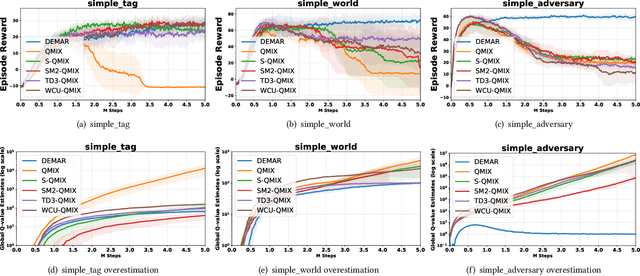
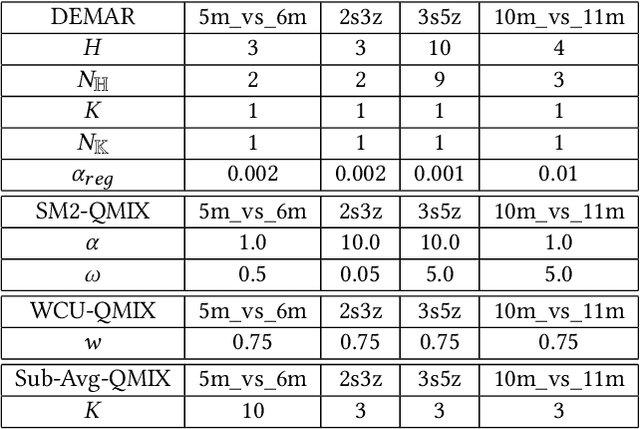
Overestimation in single-agent reinforcement learning has been extensively studied. In contrast, overestimation in the multiagent setting has received comparatively little attention although it increases with the number of agents and leads to severe learning instability. Previous works concentrate on reducing overestimation in the estimation process of target Q-value. They ignore the follow-up optimization process of online Q-network, thus making it hard to fully address the complex multiagent overestimation problem. To solve this challenge, in this study, we first establish an iterative estimation-optimization analysis framework for multiagent value-mixing Q-learning. Our analysis reveals that multiagent overestimation not only comes from the computation of target Q-value but also accumulates in the online Q-network's optimization. Motivated by it, we propose the Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer algorithm to tackle multiagent overestimation from two aspects. First, we extend the random ensemble technique into the estimation of target individual and global Q-values to derive a lower update target. Second, we propose a novel hypernet regularizer on hypernetwork weights and biases to constrain the optimization of online global Q-network to prevent overestimation accumulation. Extensive experiments in MPE and SMAC show that the proposed method successfully addresses overestimation across various tasks.
Point Cloud Understanding via Attention-Driven Contrastive Learning
Nov 22, 2024



Recently Transformer-based models have advanced point cloud understanding by leveraging self-attention mechanisms, however, these methods often overlook latent information in less prominent regions, leading to increased sensitivity to perturbations and limited global comprehension. To solve this issue, we introduce PointACL, an attention-driven contrastive learning framework designed to address these limitations. Our method employs an attention-driven dynamic masking strategy that guides the model to focus on under-attended regions, enhancing the understanding of global structures within the point cloud. Then we combine the original pre-training loss with a contrastive learning loss, improving feature discrimination and generalization. Extensive experiments validate the effectiveness of PointACL, as it achieves state-of-the-art performance across a variety of 3D understanding tasks, including object classification, part segmentation, and few-shot learning. Specifically, when integrated with different Transformer backbones like Point-MAE and PointGPT, PointACL demonstrates improved performance on datasets such as ScanObjectNN, ModelNet40, and ShapeNetPart. This highlights its superior capability in capturing both global and local features, as well as its enhanced robustness against perturbations and incomplete data.
SeaDAG: Semi-autoregressive Diffusion for Conditional Directed Acyclic Graph Generation
Oct 21, 2024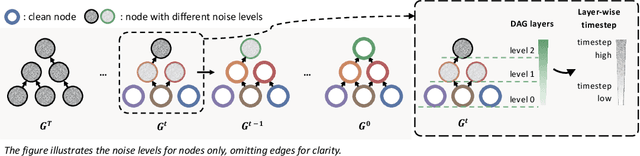
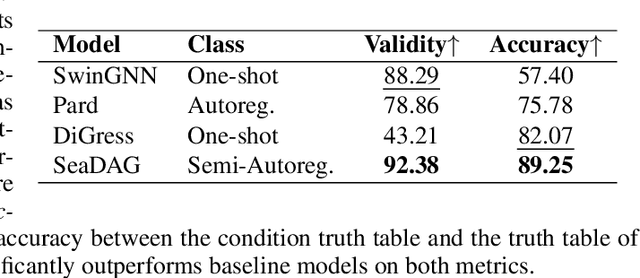
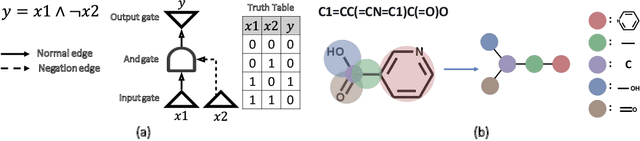
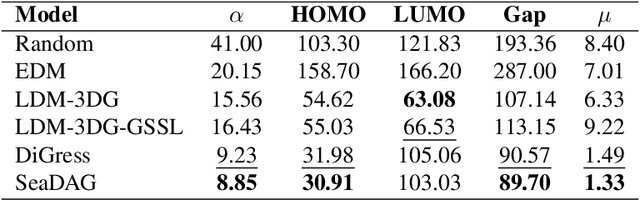
We introduce SeaDAG, a semi-autoregressive diffusion model for conditional generation of Directed Acyclic Graphs (DAGs). Considering their inherent layer-wise structure, we simulate layer-wise autoregressive generation by designing different denoising speed for different layers. Unlike conventional autoregressive generation that lacks a global graph structure view, our method maintains a complete graph structure at each diffusion step, enabling operations such as property control that require the full graph structure. Leveraging this capability, we evaluate the DAG properties during training by employing a graph property decoder. We explicitly train the model to learn graph conditioning with a condition loss, which enhances the diffusion model's capacity to generate graphs that are both realistic and aligned with specified properties. We evaluate our method on two representative conditional DAG generation tasks: (1) circuit generation from truth tables, where precise DAG structures are crucial for realizing circuit functionality, and (2) molecule generation based on quantum properties. Our approach demonstrates promising results, generating high-quality and realistic DAGs that closely align with given conditions.
MagicTailor: Component-Controllable Personalization in Text-to-Image Diffusion Models
Oct 17, 2024Recent advancements in text-to-image (T2I) diffusion models have enabled the creation of high-quality images from text prompts, but they still struggle to generate images with precise control over specific visual concepts. Existing approaches can replicate a given concept by learning from reference images, yet they lack the flexibility for fine-grained customization of the individual component within the concept. In this paper, we introduce component-controllable personalization, a novel task that pushes the boundaries of T2I models by allowing users to reconfigure specific components when personalizing visual concepts. This task is particularly challenging due to two primary obstacles: semantic pollution, where unwanted visual elements corrupt the personalized concept, and semantic imbalance, which causes disproportionate learning of the concept and component. To overcome these challenges, we design MagicTailor, an innovative framework that leverages Dynamic Masked Degradation (DM-Deg) to dynamically perturb undesired visual semantics and Dual-Stream Balancing (DS-Bal) to establish a balanced learning paradigm for desired visual semantics. Extensive comparisons, ablations, and analyses demonstrate that MagicTailor not only excels in this challenging task but also holds significant promise for practical applications, paving the way for more nuanced and creative image generation.
Unlocking Potential Binders: Multimodal Pretraining DEL-Fusion for Denoising DNA-Encoded Libraries
Sep 07, 2024



In the realm of drug discovery, DNA-encoded library (DEL) screening technology has emerged as an efficient method for identifying high-affinity compounds. However, DEL screening faces a significant challenge: noise arising from nonspecific interactions within complex biological systems. Neural networks trained on DEL libraries have been employed to extract compound features, aiming to denoise the data and uncover potential binders to the desired therapeutic target. Nevertheless, the inherent structure of DEL, constrained by the limited diversity of building blocks, impacts the performance of compound encoders. Moreover, existing methods only capture compound features at a single level, further limiting the effectiveness of the denoising strategy. To mitigate these issues, we propose a Multimodal Pretraining DEL-Fusion model (MPDF) that enhances encoder capabilities through pretraining and integrates compound features across various scales. We develop pretraining tasks applying contrastive objectives between different compound representations and their text descriptions, enhancing the compound encoders' ability to acquire generic features. Furthermore, we propose a novel DEL-fusion framework that amalgamates compound information at the atomic, submolecular, and molecular levels, as captured by various compound encoders. The synergy of these innovations equips MPDF with enriched, multi-scale features, enabling comprehensive downstream denoising. Evaluated on three DEL datasets, MPDF demonstrates superior performance in data processing and analysis for validation tasks. Notably, MPDF offers novel insights into identifying high-affinity molecules, paving the way for improved DEL utility in drug discovery.
SFANet: Spatial-Frequency Attention Network for Weather Forecasting
May 29, 2024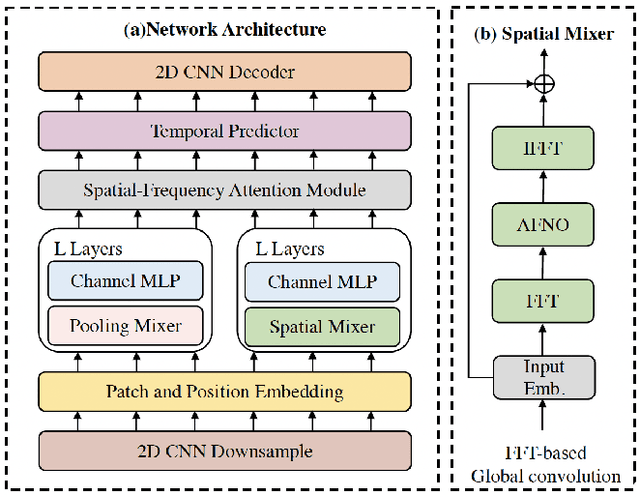

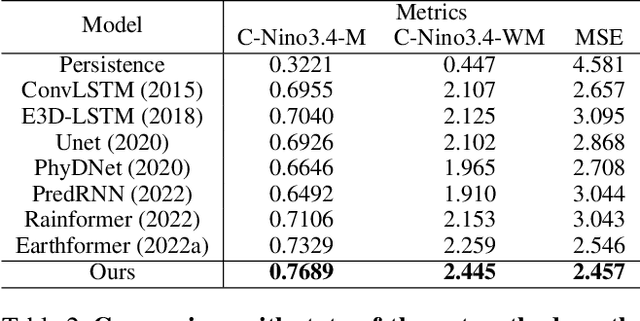
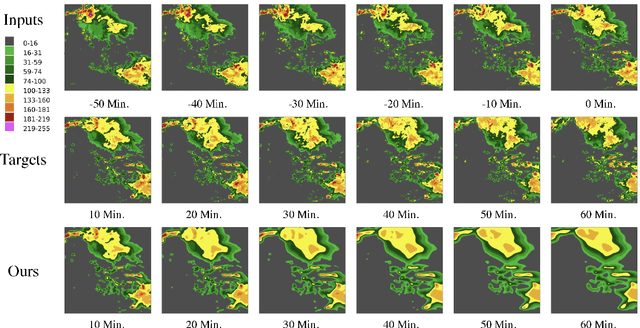
Weather forecasting plays a critical role in various sectors, driving decision-making and risk management. However, traditional methods often struggle to capture the complex dynamics of meteorological systems, particularly in the presence of high-resolution data. In this paper, we propose the Spatial-Frequency Attention Network (SFANet), a novel deep learning framework designed to address these challenges and enhance the accuracy of spatiotemporal weather prediction. Drawing inspiration from the limitations of existing methodologies, we present an innovative approach that seamlessly integrates advanced token mixing and attention mechanisms. By leveraging both pooling and spatial mixing strategies, SFANet optimizes the processing of high-dimensional spatiotemporal sequences, preserving inter-component relational information and modeling extensive long-range relationships. To further enhance feature integration, we introduce a novel spatial-frequency attention module, enabling the model to capture intricate cross-modal correlations. Our extensive experimental evaluation on two distinct datasets, the Storm EVent ImageRy (SEVIR) and the Institute for Climate and Application Research (ICAR) - El Ni\~{n}o Southern Oscillation (ENSO) dataset, demonstrates the remarkable performance of SFANet. Notably, SFANet achieves substantial advancements over state-of-the-art methods, showcasing its proficiency in forecasting precipitation patterns and predicting El Ni\~{n}o events.
TripletMix: Triplet Data Augmentation for 3D Understanding
May 28, 2024Data augmentation has proven to be a vital tool for enhancing the generalization capabilities of deep learning models, especially in the context of 3D vision where traditional datasets are often limited. Despite previous advancements, existing methods primarily cater to unimodal data scenarios, leaving a gap in the augmentation of multimodal triplet data, which integrates text, images, and point clouds. Simultaneously augmenting all three modalities enhances diversity and improves alignment across modalities, resulting in more comprehensive and robust 3D representations. To address this gap, we propose TripletMix, a novel approach to address the previously unexplored issue of multimodal data augmentation in 3D understanding. TripletMix innovatively applies the principles of mixed-based augmentation to multimodal triplet data, allowing for the preservation and optimization of cross-modal connections. Our proposed TripletMix combines feature-level and input-level augmentations to achieve dual enhancement between raw data and latent features, significantly improving the model's cross-modal understanding and generalization capabilities by ensuring feature consistency and providing diverse and realistic training samples. We demonstrate that TripletMix not only improves the baseline performance of models in various learning scenarios including zero-shot and linear probing classification but also significantly enhances model generalizability. Notably, we improved the zero-shot classification accuracy on ScanObjectNN from 51.3 percent to 61.9 percent, and on Objaverse-LVIS from 46.8 percent to 51.4 percent. Our findings highlight the potential of multimodal data augmentation to significantly advance 3D object recognition and understanding.
SG-Adapter: Enhancing Text-to-Image Generation with Scene Graph Guidance
May 24, 2024
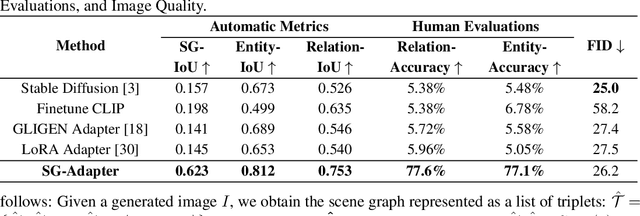
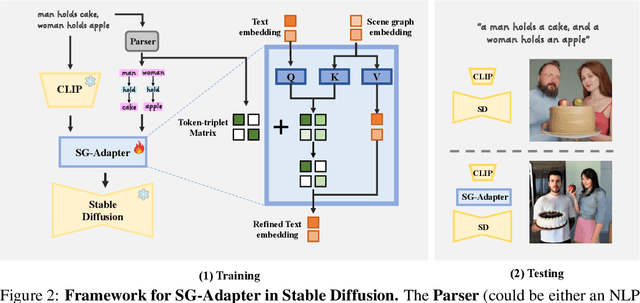
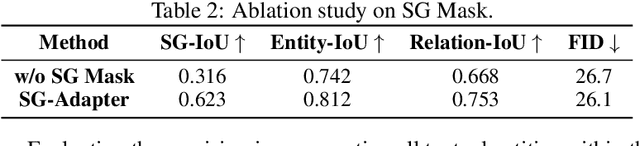
Recent advancements in text-to-image generation have been propelled by the development of diffusion models and multi-modality learning. However, since text is typically represented sequentially in these models, it often falls short in providing accurate contextualization and structural control. So the generated images do not consistently align with human expectations, especially in complex scenarios involving multiple objects and relationships. In this paper, we introduce the Scene Graph Adapter(SG-Adapter), leveraging the structured representation of scene graphs to rectify inaccuracies in the original text embeddings. The SG-Adapter's explicit and non-fully connected graph representation greatly improves the fully connected, transformer-based text representations. This enhancement is particularly notable in maintaining precise correspondence in scenarios involving multiple relationships. To address the challenges posed by low-quality annotated datasets like Visual Genome, we have manually curated a highly clean, multi-relational scene graph-image paired dataset MultiRels. Furthermore, we design three metrics derived from GPT-4V to effectively and thoroughly measure the correspondence between images and scene graphs. Both qualitative and quantitative results validate the efficacy of our approach in controlling the correspondence in multiple relationships.