 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mechanistic View on Video Generation as World Models: State and Dynamics
Jan 22, 2026Large-scale video generation models have demonstrated emergent physical coherence, positioning them as potential world models. However, a gap remains between contemporary "stateless" video architectures and classic state-centric world model theories. This work bridges this gap by proposing a novel taxonomy centered on two pillars: State Construction and Dynamics Modeling. We categorize state construction into implicit paradigms (context management) and explicit paradigms (latent compression), while dynamics modeling is analyzed through knowledge integration and architectural reformulation. Furthermore, we advocate for a transition in evaluation from visual fidelity to functional benchmarks, testing physical persistence and causal reasoning. We conclude by identifying two critical frontiers: enhancing persistence via data-driven memory and compressed fidelity, and advancing causality through latent factor decoupling and reasoning-prior integration. By addressing these challenges, the field can evolve from generating visually plausible videos to building robust, general-purpose world simulators.
CamPilot: Improving Camera Control in Video Diffusion Model with Efficient Camera Reward Feedback
Jan 22, 2026Recent advances in camera-controlled video diffusion models have significantly improved video-camera alignment. However, the camera controllability still remains limited. In this work, we build upon Reward Feedback Learning and aim to further improve camera controllability. However, directly borrowing existing ReFL approaches faces several challenges. First, current reward models lack the capacity to assess video-camera alignment. Second, decoding latent into RGB videos for reward computation introduces substantial computational overhead. Third, 3D geometric information is typically neglected during video decoding. To address these limitations, we introduce an efficient camera-aware 3D decoder that decodes video latent into 3D representations for reward quantization. Specifically, video latent along with the camera pose are decoded into 3D Gaussians. In this process, the camera pose not only acts as input, but also serves as a projection parameter. Misalignment between the video latent and camera pose will cause geometric distortions in the 3D structure, resulting in blurry renderings. Based on this property, we explicitly optimize pixel-level consistency between the rendered novel views and ground-truth ones as reward. To accommodate the stochastic nature, we further introduce a visibility term that selectively supervises only deterministic regions derived via geometric warping. Extensive experiments conducted on RealEstate10K and WorldScore benchmarks demonstrate the effectiveness of our proposed method. Project page: \href{https://a-bigbao.github.io/CamPilot/}{CamPilot Page}.
IdentityStory: Taming Your Identity-Preserving Generator for Human-Centric Story Generation
Dec 29, 2025Recent visual generative models enable story generation with consistent characters from text, but human-centric story generation faces additional challenges, such as maintaining detailed and diverse human face consistency and coordinating multiple characters across different images. This paper presents IdentityStory, a framework for human-centric story generation that ensures consistent character identity across multiple sequential images. By taming identity-preserving generators, the framework features two key components: Iterative Identity Discovery, which extracts cohesive character identities, and Re-denoising Identity Injection, which re-denoises images to inject identities while preserving desired context. Experiments on the ConsiStory-Human benchmark demonstrate that IdentityStory outperforms existing methods, particularly in face consistency, and supports multi-character combinations. The framework also shows strong potential for applications such as infinite-length story generation and dynamic character composition.
StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors
Dec 18, 2025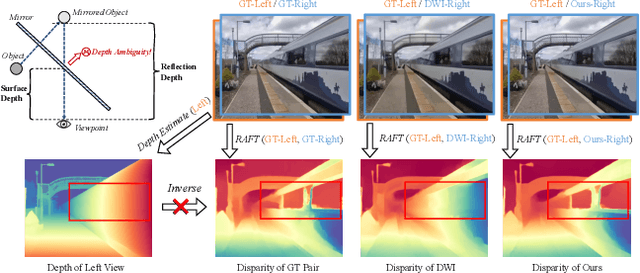

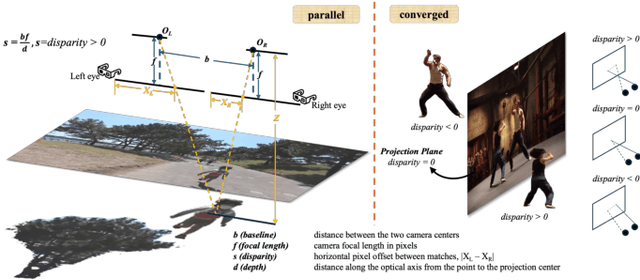

The rapid growth of stereoscopic displays, including VR headsets and 3D cinemas, has led to increasing demand for high-quality stereo video content. However, producing 3D videos remains costly and complex, while automatic Monocular-to-Stereo conversion is hindered by the limitations of the multi-stage ``Depth-Warp-Inpaint'' (DWI) pipeline. This paradigm suffers from error propagation, depth ambiguity, and format inconsistency between parallel and converged stereo configurations. To address these challenges, we introduce UniStereo, the first large-scale unified dataset for stereo video conversion, covering both stereo formats to enable fair benchmarking and robust model training. Building upon this dataset, we propose StereoPilot, an efficient feed-forward model that directly synthesizes the target view without relying on explicit depth maps or iterative diffusion sampling. Equipped with a learnable domain switcher and a cycle consistency loss, StereoPilot adapts seamlessly to different stereo formats and achieves improved consistency. Extensive experiments demonstrate that StereoPilot significantly outperforms state-of-the-art methods in both visual fidelity and computational efficiency. Project page: https://hit-perfect.github.io/StereoPilot/.
RectifiedHR: Enable Efficient High-Resolution Image Generation via Energy Rectification
Mar 04, 2025Diffusion models have achieved remarkable advances in various image generation tasks. However, their performance notably declines when generating images at resolutions higher than those used during the training period. Despite the existence of numerous methods for producing high-resolution images, they either suffer from inefficiency or are hindered by complex operations. In this paper, we propose RectifiedHR, an efficient and straightforward solution for training-free high-resolution image generation. Specifically, we introduce the noise refresh strategy, which theoretically only requires a few lines of code to unlock the model's high-resolution generation ability and improve efficiency. Additionally, we first observe the phenomenon of energy decay that may cause image blurriness during the high-resolution image generation process. To address this issue, we propose an Energy Rectification strategy, where modifying the hyperparameters of the classifier-free guidance effectively improves the generation performance. Our method is entirely training-free and boasts a simple implementation logic. Through extensive comparisons with numerous baseline methods, our RectifiedHR demonstrates superior effectiveness and efficiency.
PRM: Photometric Stereo based Large Reconstruction Model
Dec 10, 2024We propose PRM, a novel photometric stereo based large reconstruction model to reconstruct high-quality meshes with fine-grained local details. Unlike previous large reconstruction models that prepare images under fixed and simple lighting as both input and supervision, PRM renders photometric stereo images by varying materials and lighting for the purposes, which not only improves the precise local details by providing rich photometric cues but also increases the model robustness to variations in the appearance of input images. To offer enhanced flexibility of images rendering, we incorporate a real-time physically-based rendering (PBR) method and mesh rasterization for online images rendering. Moreover, in employing an explicit mesh as our 3D representation, PRM ensures the application of differentiable PBR, which supports the utilization of multiple photometric supervisions and better models the specular color for high-quality geometry optimization. Our PRM leverages photometric stereo images to achieve high-quality reconstructions with fine-grained local details, even amidst sophisticated image appearances. Extensive experiments demonstrate that PRM significantly outperforms other models.
DisEnvisioner: Disentangled and Enriched Visual Prompt for Customized Image Generation
Oct 02, 2024In the realm of image generation, creating customized images from visual prompt with additional textual instruction emerges as a promising endeavor. However, existing methods, both tuning-based and tuning-free, struggle with interpreting the subject-essential attributes from the visual prompt. This leads to subject-irrelevant attributes infiltrating the generation process, ultimately compromising the personalization quality in both editability and ID preservation. In this paper, we present DisEnvisioner, a novel approach for effectively extracting and enriching the subject-essential features while filtering out -irrelevant information, enabling exceptional customization performance, in a tuning-free manner and using only a single image. Specifically, the feature of the subject and other irrelevant components are effectively separated into distinctive visual tokens, enabling a much more accurate customization. Aiming to further improving the ID consistency, we enrich the disentangled features, sculpting them into more granular representations. Experiments demonstrate the superiority of our approach over existing methods in instruction response (editability), ID consistency, inference speed, and the overall image quality, highlighting the effectiveness and efficiency of DisEnvisioner. Project page: https://disenvisioner.github.io/.
SG-Adapter: Enhancing Text-to-Image Generation with Scene Graph Guidance
May 24, 2024
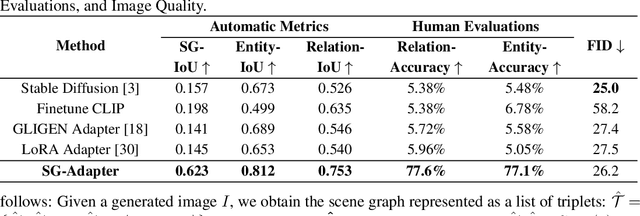
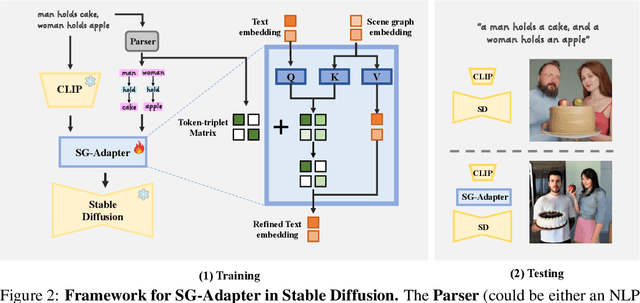
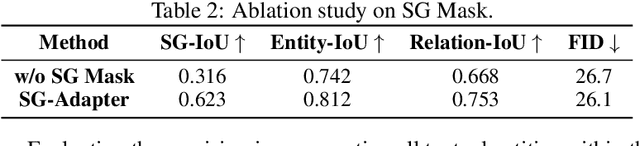
Recent advancements in text-to-image generation have been propelled by the development of diffusion models and multi-modality learning. However, since text is typically represented sequentially in these models, it often falls short in providing accurate contextualization and structural control. So the generated images do not consistently align with human expectations, especially in complex scenarios involving multiple objects and relationships. In this paper, we introduce the Scene Graph Adapter(SG-Adapter), leveraging the structured representation of scene graphs to rectify inaccuracies in the original text embeddings. The SG-Adapter's explicit and non-fully connected graph representation greatly improves the fully connected, transformer-based text representations. This enhancement is particularly notable in maintaining precise correspondence in scenarios involving multiple relationships. To address the challenges posed by low-quality annotated datasets like Visual Genome, we have manually curated a highly clean, multi-relational scene graph-image paired dataset MultiRels. Furthermore, we design three metrics derived from GPT-4V to effectively and thoroughly measure the correspondence between images and scene graphs. Both qualitative and quantitative results validate the efficacy of our approach in controlling the correspondence in multiple relationships.
Motion Inversion for Video Customization
Mar 29, 2024In this research, we present a novel approach to motion customization in video generation, addressing the widespread gap in the thorough exploration of motion representation within video generative models. Recognizing the unique challenges posed by video's spatiotemporal nature, our method introduces Motion Embeddings, a set of explicit, temporally coherent one-dimensional embeddings derived from a given video. These embeddings are designed to integrate seamlessly with the temporal transformer modules of video diffusion models, modulating self-attention computations across frames without compromising spatial integrity. Our approach offers a compact and efficient solution to motion representation and enables complex manipulations of motion characteristics through vector arithmetic in the embedding space. Furthermore, we identify the Temporal Discrepancy in video generative models, which refers to variations in how different motion modules process temporal relationships between frames. We leverage this understanding to optimize the integration of our motion embeddings. Our contributions include the introduction of a tailored motion embedding for customization tasks, insights into the temporal processing differences in video models, and a demonstration of the practical advantages and effectiveness of our method through extensive experiments.
Decompose and Realign: Tackling Condition Misalignment in Text-to-Image Diffusion Models
Jun 26, 2023Text-to-image diffusion models have advanced towards more controllable generation via supporting various image conditions (e.g., depth map) beyond text. However, these models are learned based on the premise of perfect alignment between the text and image conditions. If this alignment is not satisfied, the final output could be either dominated by one condition, or ambiguity may arise, failing to meet user expectations. To address this issue, we present a training-free approach called "Decompose and Realign'' to further improve the controllability of existing models when provided with partially aligned conditions. The ``Decompose'' phase separates conditions based on pair relationships, computing scores individually for each pair. This ensures that each pair no longer has conflicting conditions. The "Realign'' phase aligns these independently calculated scores via a cross-attention mechanism to avoid new conflicts when combing them back. Both qualitative and quantitative results demonstrate the effectiveness of our approach in handling unaligned conditions, which performs favorably against recent methods and more importantly adds flexibility to the controllable image generation process.