 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mechanistic View on Video Generation as World Models: State and Dynamics
Jan 22, 2026Large-scale video generation models have demonstrated emergent physical coherence, positioning them as potential world models. However, a gap remains between contemporary "stateless" video architectures and classic state-centric world model theories. This work bridges this gap by proposing a novel taxonomy centered on two pillars: State Construction and Dynamics Modeling. We categorize state construction into implicit paradigms (context management) and explicit paradigms (latent compression), while dynamics modeling is analyzed through knowledge integration and architectural reformulation. Furthermore, we advocate for a transition in evaluation from visual fidelity to functional benchmarks, testing physical persistence and causal reasoning. We conclude by identifying two critical frontiers: enhancing persistence via data-driven memory and compressed fidelity, and advancing causality through latent factor decoupling and reasoning-prior integration. By addressing these challenges, the field can evolve from generating visually plausible videos to building robust, general-purpose world simulators.
DB-MSMUNet:Dual Branch Multi-scale Mamba UNet for Pancreatic CT Scans Segmentation
Jan 08, 2026Accurate segmentation of the pancreas and its lesions in CT scans is crucial for the precise diagnosis and treatment of pancreatic cancer. However, it remains a highly challenging task due to several factors such as low tissue contrast with surrounding organs, blurry anatomical boundaries, irregular organ shapes, and the small size of lesions. To tackle these issues, we propose DB-MSMUNet (Dual-Branch Multi-scale Mamba UNet), a novel encoder-decoder architecture designed specifically for robust pancreatic segmentation. The encoder is constructed using a Multi-scale Mamba Module (MSMM), which combines deformable convolutions and multi-scale state space modeling to enhance both global context modeling and local deformation adaptation. The network employs a dual-decoder design: the edge decoder introduces an Edge Enhancement Path (EEP) to explicitly capture boundary cues and refine fuzzy contours, while the area decoder incorporates a Multi-layer Decoder (MLD) to preserve fine-grained details and accurately reconstruct small lesions by leveraging multi-scale deep semantic features. Furthermore, Auxiliary Deep Supervision (ADS) heads are added at multiple scales to both decoders, providing more accurate gradient feedback and further enhancing the discriminative capability of multi-scale features. We conduct extensive experiments on three datasets: the NIH Pancreas dataset, the MSD dataset, and a clinical pancreatic tumor dataset provided by collaborating hospitals. DB-MSMUNet achieves Dice Similarity Coefficients of 89.47%, 87.59%, and 89.02%, respectively, outperforming most existing state-of-the-art methods in terms of segmentation accuracy, edge preservation, and robustness across different datasets. These results demonstrate the effectiveness and generalizability of the proposed method for real-world pancreatic CT segmentation tasks.
VideoMemory: Toward Consistent Video Generation via Memory Integration
Jan 07, 2026Maintaining consistent characters, props, and environments across multiple shots is a central challenge in narrative video generation. Existing models can produce high-quality short clips but often fail to preserve entity identity and appearance when scenes change or when entities reappear after long temporal gaps. We present VideoMemory, an entity-centric framework that integrates narrative planning with visual generation through a Dynamic Memory Bank. Given a structured script, a multi-agent system decomposes the narrative into shots, retrieves entity representations from memory, and synthesizes keyframes and videos conditioned on these retrieved states. The Dynamic Memory Bank stores explicit visual and semantic descriptors for characters, props, and backgrounds, and is updated after each shot to reflect story-driven changes while preserving identity. This retrieval-update mechanism enables consistent portrayal of entities across distant shots and supports coherent long-form generation. To evaluate this setting, we construct a 54-case multi-shot consistency benchmark covering character-, prop-, and background-persistent scenarios. Extensive experiments show that VideoMemory achieves strong entity-level coherence and high perceptual quality across diverse narrative sequences.
PresentCoach: Dual-Agent Presentation Coaching through Exemplars and Interactive Feedback
Nov 19, 2025Effective presentation skills are essential in education, professional communication, and public speaking, yet learners often lack access to high-quality exemplars or personalized coaching. Existing AI tools typically provide isolated functionalities such as speech scoring or script generation without integrating reference modeling and interactive feedback into a cohesive learning experience. We introduce a dual-agent system that supports presentation practice through two complementary roles: the Ideal Presentation Agent and the Coach Agent. The Ideal Presentation Agent converts user-provided slides into model presentation videos by combining slide processing, visual-language analysis, narration script generation, personalized voice synthesis, and synchronized video assembly. The Coach Agent then evaluates user-recorded presentations against these exemplars, conducting multimodal speech analysis and delivering structured feedback in an Observation-Impact-Suggestion (OIS) format. To enhance the authenticity of the learning experience, the Coach Agent incorporates an Audience Agent, which simulates the perspective of a human listener and provides humanized feedback reflecting audience reactions and engagement. Together, these agents form a closed loop of observation, practice, and feedback. Implemented on a robust backend with multi-model integration, voice cloning, and error handling mechanisms, the system demonstrates how AI-driven agents can provide engaging, human-centered, and scalable support for presentation skill development in both educational and professional contexts.
PreGenie: An Agentic Framework for High-quality Visual Presentation Generation
May 27, 2025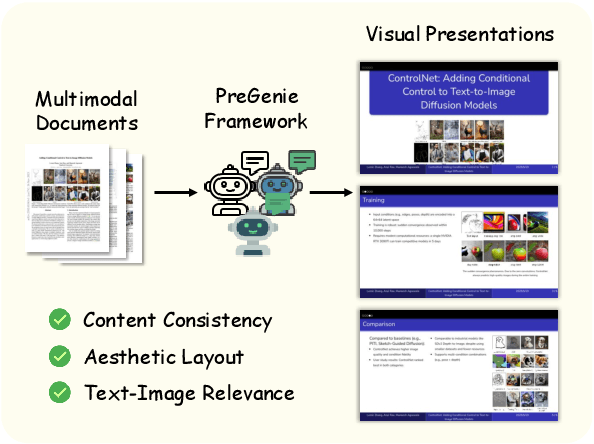



Visual presentations are vital for effective communication. Early attempts to automate their creation using deep learning often faced issues such as poorly organized layouts, inaccurate text summarization, and a lack of image understanding, leading to mismatched visuals and text. These limitations restrict their application in formal contexts like business and scientific research. To address these challenges, we propose PreGenie, an agentic and modular framework powered by multimodal large language models (MLLMs) for generating high-quality visual presentations. PreGenie is built on the Slidev presentation framework, where slides are rendered from Markdown code. It operates in two stages: (1) Analysis and Initial Generation, which summarizes multimodal input and generates initial code, and (2) Review and Re-generation, which iteratively reviews intermediate code and rendered slides to produce final, high-quality presentations. Each stage leverages multiple MLLMs that collaborate and share information. Comprehensive experiments demonstrate that PreGenie excels in multimodal understanding, outperforming existing models in both aesthetics and content consistency, while aligning more closely with human design preferences.
ComfyMind: Toward General-Purpose Generation via Tree-Based Planning and Reactive Feedback
May 23, 2025With the rapid advancement of generative models, general-purpose generation has gained increasing attention as a promising approach to unify diverse tasks across modalities within a single system. Despite this progress, existing open-source frameworks often remain fragile and struggle to support complex real-world applications due to the lack of structured workflow planning and execution-level feedback. To address these limitations, we present ComfyMind, a collaborative AI system designed to enable robust and scalable general-purpose generation, built on the ComfyUI platform. ComfyMind introduces two core innovations: Semantic Workflow Interface (SWI) that abstracts low-level node graphs into callable functional modules described in natural language, enabling high-level composition and reducing structural errors; Search Tree Planning mechanism with localized feedback execution, which models generation as a hierarchical decision process and allows adaptive correction at each stage. Together, these components improve the stability and flexibility of complex generative workflows. We evaluate ComfyMind on three public benchmarks: ComfyBench, GenEval, and Reason-Edit, which span generation, editing, and reasoning tasks. Results show that ComfyMind consistently outperforms existing open-source baselines and achieves performance comparable to GPT-Image-1. ComfyMind paves a promising path for the development of open-source general-purpose generative AI systems. Project page: https://github.com/LitaoGuo/ComfyMind
Long-Video Audio Synthesis with Multi-Agent Collaboration
Mar 17, 2025Video-to-audio synthesis, which generates synchronized audio for visual content, critically enhances viewer immersion and narrative coherence in film and interactive media. However, video-to-audio dubbing for long-form content remains an unsolved challenge due to dynamic semantic shifts, temporal misalignment, and the absence of dedicated datasets. While existing methods excel in short videos, they falter in long scenarios (e.g., movies) due to fragmented synthesis and inadequate cross-scene consistency. We propose LVAS-Agent, a novel multi-agent framework that emulates professional dubbing workflows through collaborative role specialization. Our approach decomposes long-video synthesis into four steps including scene segmentation, script generation, sound design and audio synthesis. Central innovations include a discussion-correction mechanism for scene/script refinement and a generation-retrieval loop for temporal-semantic alignment. To enable systematic evaluation, we introduce LVAS-Bench, the first benchmark with 207 professionally curated long videos spanning diverse scenarios. Experiments demonstrate superior audio-visual alignment over baseline methods. Project page: https://lvas-agent.github.io
Kiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
Mar 03, 2025Diffusion models have achieved great success in generating 2D images. However, the quality and generalizability of 3D content generation remain limited. State-of-the-art methods often require large-scale 3D assets for training, which are challenging to collect. In this work, we introduce Kiss3DGen (Keep It Simple and Straightforward in 3D Generation), an efficient framework for generating, editing, and enhancing 3D objects by repurposing a well-trained 2D image diffusion model for 3D generation. Specifically, we fine-tune a diffusion model to generate ''3D Bundle Image'', a tiled representation composed of multi-view images and their corresponding normal maps. The normal maps are then used to reconstruct a 3D mesh, and the multi-view images provide texture mapping, resulting in a complete 3D model. This simple method effectively transforms the 3D generation problem into a 2D image generation task, maximizing the utilization of knowledge in pretrained diffusion models. Furthermore, we demonstrate that our Kiss3DGen model is compatible with various diffusion model techniques, enabling advanced features such as 3D editing, mesh and texture enhancement, etc. Through extensive experiments, we demonstrate the effectiveness of our approach, showcasing its ability to produce high-quality 3D models efficiently.
MHAF-YOLO: Multi-Branch Heterogeneous Auxiliary Fusion YOLO for accurate object detection
Feb 07, 2025Due to the effective multi-scale feature fusion capabilities of the Path Aggregation FPN (PAFPN), it has become a widely adopted component in YOLO-based detectors. However, PAFPN struggles to integrate high-level semantic cues with low-level spatial details, limiting its performance in real-world applications, especially with significant scale variations. In this paper, we propose MHAF-YOLO, a novel detection framework featuring a versatile neck design called the Multi-Branch Auxiliary FPN (MAFPN), which consists of two key modules: the Superficial Assisted Fusion (SAF) and Advanced Assisted Fusion (AAF). The SAF bridges the backbone and the neck by fusing shallow features, effectively transferring crucial low-level spatial information with high fidelity. Meanwhile, the AAF integrates multi-scale feature information at deeper neck layers, delivering richer gradient information to the output layer and further enhancing the model learning capacity. To complement MAFPN, we introduce the Global Heterogeneous Flexible Kernel Selection (GHFKS) mechanism and the Reparameterized Heterogeneous Multi-Scale (RepHMS) module to enhance feature fusion. RepHMS is globally integrated into the network, utilizing GHFKS to select larger convolutional kernels for various feature layers, expanding the vertical receptive field and capturing contextual information across spatial hierarchies. Locally, it optimizes convolution by processing both large and small kernels within the same layer, broadening the lateral receptive field and preserving crucial details for detecting smaller targets. The source code of this work is available at: https://github.com/yang0201/MHAF-YOLO.
GaussianProperty: Integrating Physical Properties to 3D Gaussians with LMMs
Dec 15, 2024Estimating physical properties for visual data is a crucial task in computer vision, graphics, and robotics, underpinning applications such as augmented reality, physical simulation, and robotic grasping. However, this area remains under-explored due to the inherent ambiguities in physical property estimation. To address these challenges, we introduce GaussianProperty, a training-free framework that assigns physical properties of materials to 3D Gaussians. Specifically, we integrate the segmentation capability of SAM with the recognition capability of GPT-4V(ision) to formulate a global-local physical property reasoning module for 2D images. Then we project the physical properties from multi-view 2D images to 3D Gaussians using a voting strategy. We demonstrate that 3D Gaussians with physical property annotations enable applications in physics-based dynamic simulation and robotic grasping. For physics-based dynamic simulation, we leverage the Material Point Method (MPM) for realistic dynamic simulation. For robot grasping, we develop a grasping force prediction strategy that estimates a safe force range required for object grasping based on the estimated physical properties. Extensive experiments on material segmentation, physics-based dynamic simulation, and robotic grasping validate the effectiveness of our proposed method, highlighting its crucial role in understanding physical properties from visual data. Online demo, code, more cases and annotated datasets are available on \href{https://Gaussian-Property.github.io}{this https URL}.