 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB-MSMUNet:Dual Branch Multi-scale Mamba UNet for Pancreatic CT Scans Segmentation
Jan 08, 2026Accurate segmentation of the pancreas and its lesions in CT scans is crucial for the precise diagnosis and treatment of pancreatic cancer. However, it remains a highly challenging task due to several factors such as low tissue contrast with surrounding organs, blurry anatomical boundaries, irregular organ shapes, and the small size of lesions. To tackle these issues, we propose DB-MSMUNet (Dual-Branch Multi-scale Mamba UNet), a novel encoder-decoder architecture designed specifically for robust pancreatic segmentation. The encoder is constructed using a Multi-scale Mamba Module (MSMM), which combines deformable convolutions and multi-scale state space modeling to enhance both global context modeling and local deformation adaptation. The network employs a dual-decoder design: the edge decoder introduces an Edge Enhancement Path (EEP) to explicitly capture boundary cues and refine fuzzy contours, while the area decoder incorporates a Multi-layer Decoder (MLD) to preserve fine-grained details and accurately reconstruct small lesions by leveraging multi-scale deep semantic features. Furthermore, Auxiliary Deep Supervision (ADS) heads are added at multiple scales to both decoders, providing more accurate gradient feedback and further enhancing the discriminative capability of multi-scale features. We conduct extensive experiments on three datasets: the NIH Pancreas dataset, the MSD dataset, and a clinical pancreatic tumor dataset provided by collaborating hospitals. DB-MSMUNet achieves Dice Similarity Coefficients of 89.47%, 87.59%, and 89.02%, respectively, outperforming most existing state-of-the-art methods in terms of segmentation accuracy, edge preservation, and robustness across different datasets. These results demonstrate the effectiveness and generalizability of the proposed method for real-world pancreatic CT segmentation tasks.
VisAlgae 2023: A Dataset and Challenge for Algae Detection in Microscopy Images
May 27, 2025Microalgae, vital for ecological balance and economic sectors, present challenges in detection due to their diverse sizes and conditions. This paper summarizes the second "Vision Meets Algae" (VisAlgae 2023) Challenge, aiming to enhance high-throughput microalgae cell detection. The challenge, which attracted 369 participating teams, includes a dataset of 1000 images across six classes, featuring microalgae of varying sizes and distinct features. Participants faced tasks such as detecting small targets, handling motion blur, and complex backgrounds. The top 10 methods, outlined here, offer insights into overcoming these challenges and maximizing detection accuracy. This intersection of algae research and computer vision offers promise for ecological understanding and technological advancement. The dataset can be accessed at: https://github.com/juntaoJianggavin/Visalgae2023/.
MHAF-YOLO: Multi-Branch Heterogeneous Auxiliary Fusion YOLO for accurate object detection
Feb 07, 2025Due to the effective multi-scale feature fusion capabilities of the Path Aggregation FPN (PAFPN), it has become a widely adopted component in YOLO-based detectors. However, PAFPN struggles to integrate high-level semantic cues with low-level spatial details, limiting its performance in real-world applications, especially with significant scale variations. In this paper, we propose MHAF-YOLO, a novel detection framework featuring a versatile neck design called the Multi-Branch Auxiliary FPN (MAFPN), which consists of two key modules: the Superficial Assisted Fusion (SAF) and Advanced Assisted Fusion (AAF). The SAF bridges the backbone and the neck by fusing shallow features, effectively transferring crucial low-level spatial information with high fidelity. Meanwhile, the AAF integrates multi-scale feature information at deeper neck layers, delivering richer gradient information to the output layer and further enhancing the model learning capacity. To complement MAFPN, we introduce the Global Heterogeneous Flexible Kernel Selection (GHFKS) mechanism and the Reparameterized Heterogeneous Multi-Scale (RepHMS) module to enhance feature fusion. RepHMS is globally integrated into the network, utilizing GHFKS to select larger convolutional kernels for various feature layers, expanding the vertical receptive field and capturing contextual information across spatial hierarchies. Locally, it optimizes convolution by processing both large and small kernels within the same layer, broadening the lateral receptive field and preserving crucial details for detecting smaller targets. The source code of this work is available at: https://github.com/yang0201/MHAF-YOLO.
IAFI-FCOS: Intra- and across-layer feature interaction FCOS model for lesion detection of CT images
Sep 01, 2024Effective lesion detection in medical image is not only rely on the features of lesion region,but also deeply relative to the surrounding information.However,most current methods have not fully utilize it.What is more,multi-scale feature fusion mechanism of most traditional detectors are unable to transmit detail information without loss,which makes it hard to detect small and boundary ambiguous lesion in early stage disease.To address the above issues,we propose a novel intra- and across-layer feature interaction FCOS model (IAFI-FCOS) with a multi-scale feature fusion mechanism ICAF-FPN,which is a network structure with intra-layer context augmentation (ICA) block and across-layer feature weighting (AFW) block.Therefore,the traditional FCOS detector is optimized by enriching the feature representation from two perspectives.Specifically,the ICA block utilizes dilated attention to augment the context information in order to capture long-range dependencies between the lesion region and the surrounding.The AFW block utilizes dual-axis attention mechanism and weighting operation to obtain the efficient across-layer interaction features,enhancing the representation of detailed features.Our approach has been extensively experimented on both the private pancreatic lesion dataset and the public DeepLesion dataset,our model achieves SOTA results on the pancreatic lesion dataset.
LSM-YOLO: A Compact and Effective ROI Detector for Medical Detection
Aug 26, 2024In existing medical Region of Interest (ROI) detection, there lacks an algorithm that can simultaneously satisfy both real-time performance and accuracy, not meeting the growing demand for automatic detection in medicine. Although the basic YOLO framework ensures real-time detection due to its fast speed, it still faces challenges in maintaining precision concurrently. To alleviate the above problems, we propose a novel model named Lightweight Shunt Matching-YOLO (LSM-YOLO), with Lightweight Adaptive Extraction (LAE) and Multipath Shunt Feature Matching (MSFM). Firstly, by using LAE to refine feature extraction, the model can obtain more contextual information and high-resolution details from multiscale feature maps, thereby extracting detailed features of ROI in medical images while reducing the influence of noise. Secondly, MSFM is utilized to further refine the fusion of high-level semantic features and low-level visual features, enabling better fusion between ROI features and neighboring features, thereby improving the detection rate for better diagnostic assistance. Experimental results demonstrate that LSM-YOLO achieves 48.6% AP on a private dataset of pancreatic tumors, 65.1% AP on the BCCD blood cell detection public dataset, and 73.0% AP on the Br35h brain tumor detection public dataset. Our model achieves state-of-the-art performance with minimal parameter cost on the above three datasets. The source codes are at: https://github.com/VincentYuuuuuu/LSM-YOLO.
Multi-Branch Auxiliary Fusion YOLO with Re-parameterization Heterogeneous Convolutional for accurate object detection
Jul 05, 2024


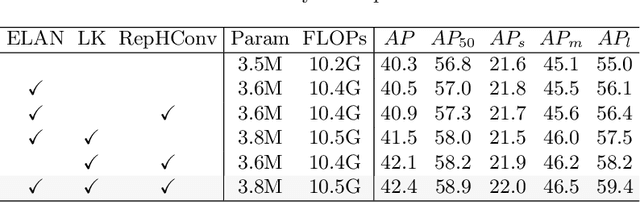
Due to the effective performance of multi-scale feature fusion, Path Aggregation FPN (PAFPN) is widely employed in YOLO detectors. However, it cannot efficiently and adaptively integrate high-level semantic information with low-level spatial information simultaneously. We propose a new model named MAF-YOLO in this paper, which is a novel object detection framework with a versatile neck named Multi-Branch Auxiliary FPN (MAFPN). Within MAFPN, the Superficial Assisted Fusion (SAF) module is designed to combine the output of the backbone with the neck, preserving an optimal level of shallow information to facilitate subsequent learning. Meanwhile, the Advanced Assisted Fusion (AAF) module deeply embedded within the neck conveys a more diverse range of gradient information to the output layer. Furthermore, our proposed Re-parameterized Heterogeneous Efficient Layer Aggregation Network (RepHELAN) module ensures that both the overall model architecture and convolutional design embrace the utilization of heterogeneous large convolution kernels. Therefore, this guarantees the preservation of information related to small targets while simultaneously achieving the multi-scale receptive field. Finally, taking the nano version of MAF-YOLO for example, it can achieve 42.4% AP on COCO with only 3.76M learnable parameters and 10.51G FLOPs, and approximately outperforms YOLOv8n by about 5.1%. The source code of this work is available at: https://github.com/yang-0201/MAF-YOLO.
DuEDL: Dual-Branch Evidential Deep Learning for Scribble-Supervised Medical Image Segmentation
May 23, 2024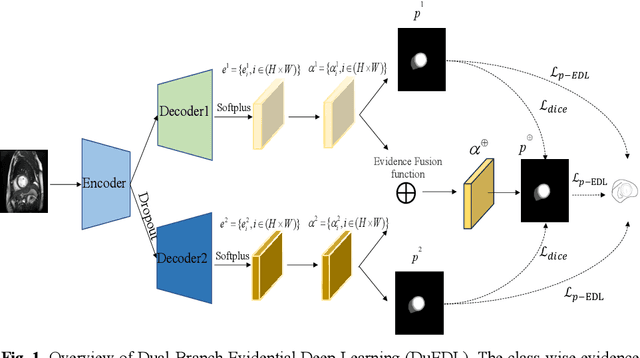
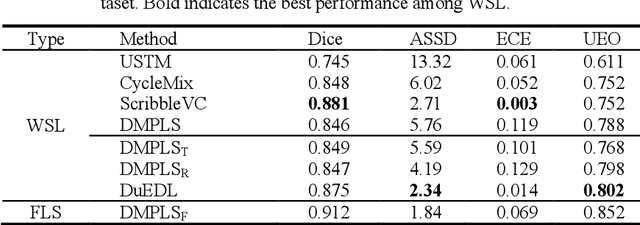
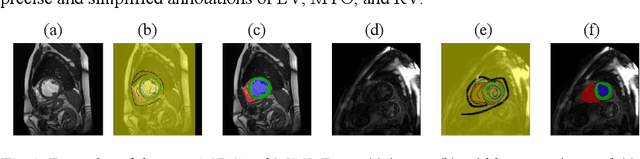
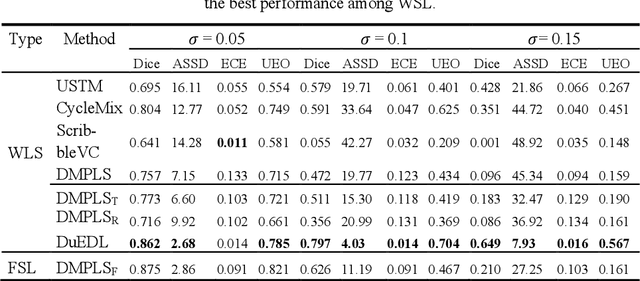
Despite the recent progress in medical image segmentation with scribble-based annotations, the segmentation results of most models are still not ro-bust and generalizable enough in open environments. Evidential deep learn-ing (EDL) has recently been proposed as a promising solution to model predictive uncertainty and improve the reliability of medical image segmen-tation. However directly applying EDL to scribble-supervised medical im-age segmentation faces a tradeoff between accuracy and reliability. To ad-dress the challenge, we propose a novel framework called Dual-Branch Evi-dential Deep Learning (DuEDL). Firstly, the decoder of the segmentation network is changed to two different branches, and the evidence of the two branches is fused to generate high-quality pseudo-labels. Then the frame-work applies partial evidence loss and two-branch consistent loss for joint training of the model to adapt to the scribble supervision learning. The pro-posed method was tested on two cardiac datasets: ACDC and MSCMRseg. The results show that our method significantly enhances the reliability and generalization ability of the model without sacrificing accuracy, outper-forming state-of-the-art baselines. The code is available at https://github.com/Gardnery/DuEDL.
Deep Co-supervision and Attention Fusion Strategy for Automatic COVID-19 Lung Infection Segmentation on CT Images
Dec 20, 2021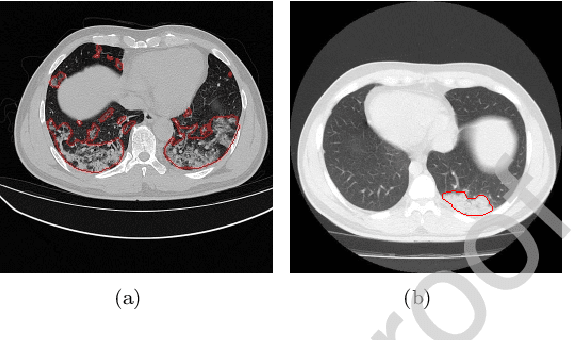
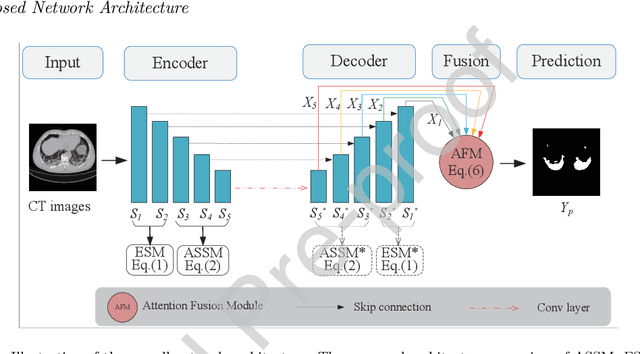
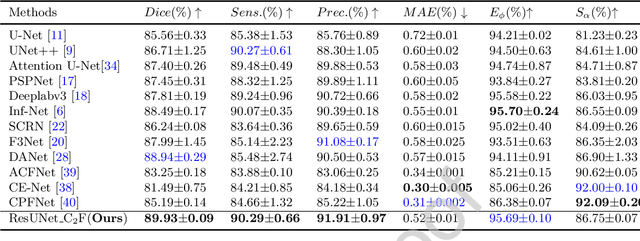
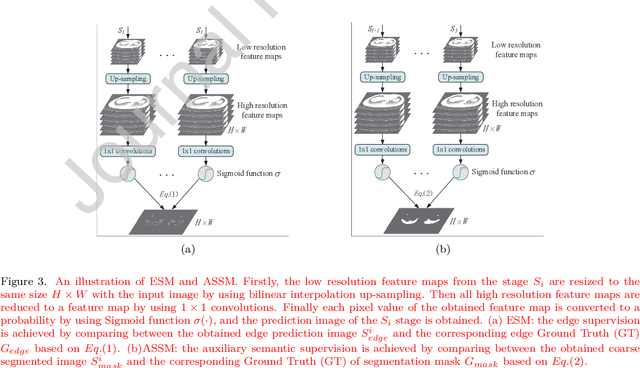
Due to the irregular shapes,various sizes and indistinguishable boundaries between the normal and infected tissues, it is still a challenging task to accurately segment the infected lesions of COVID-19 on CT images. In this paper, a novel segmentation scheme is proposed for the infections of COVID-19 by enhancing supervised information and fusing multi-scale feature maps of different levels based on the encoder-decoder architecture. To this end, a deep collaborative supervision (Co-supervision) scheme is proposed to guide the network learning the features of edges and semantics. More specifically, an Edge Supervised Module (ESM) is firstly designed to highlight low-level boundary features by incorporating the edge supervised information into the initial stage of down-sampling. Meanwhile, an Auxiliary Semantic Supervised Module (ASSM) is proposed to strengthen high-level semantic information by integrating mask supervised information into the later stage. Then an Attention Fusion Module (AFM) is developed to fuse multiple scale feature maps of different levels by using an attention mechanism to reduce the semantic gaps between high-level and low-level feature maps. Finally, the effectiveness of the proposed scheme is demonstrated on four various COVID-19 CT datasets. The results show that the proposed three modules are all promising. Based on the baseline (ResUnet), using ESM, ASSM, or AFM alone can respectively increase Dice metric by 1.12\%, 1.95\%,1.63\% in our dataset, while the integration by incorporating three models together can rise 3.97\%. Compared with the existing approaches in various datasets, the proposed method can obtain better segmentation performance in some main metrics, and can achieve the best generalization and comprehensive performance.
Adaptively Customizing Activation Functions for Various Layers
Dec 17, 2021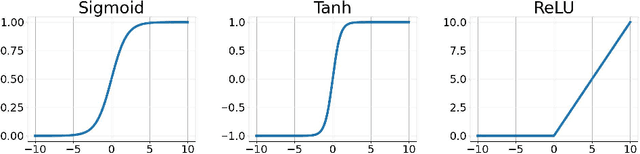



To enhance the nonlinearity of neural networks and increase their mapping abilities between the inputs and response variables, activation functions play a crucial role to model more complex relationships and patterns in the data. In this work, a novel methodology is proposed to adaptively customize activation functions only by adding very few parameters to the traditional activation functions such as Sigmoid, Tanh, and ReLU. To verify the effectiveness of the proposed methodology, some theoretical and experimental analysis on accelerating the convergence and improving the performance is presented, and a series of experiments are conducted based on various network models (such as AlexNet, VGGNet, GoogLeNet, ResNet and DenseNet), and various datasets (such as CIFAR10, CIFAR100, miniImageNet, PASCAL VOC and COCO) . To further verify the validity and suitability in various optimization strategies and usage scenarios, some comparison experiments are also implemented among different optimization strategies (such as SGD, Momentum, AdaGrad, AdaDelta and ADAM) and different recognition tasks like classification and detection. The results show that the proposed methodology is very simple but with significant performance in convergence speed, precision and generalization, and it can surpass other popular methods like ReLU and adaptive functions like Swish in almost all experiments in terms of overall performance.The code is publicly available at https://github.com/HuHaigen/Adaptively-Customizing-Activation-Functions. The package includes the proposed three adaptive activation functions for reproducibility purposes.
Image Denoising Using Sparsifying Transform Learning and Weighted Singular Values Minimization
Apr 02, 2020
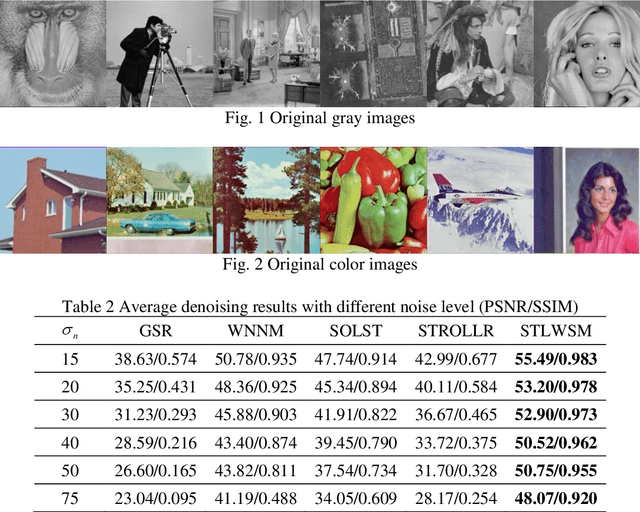
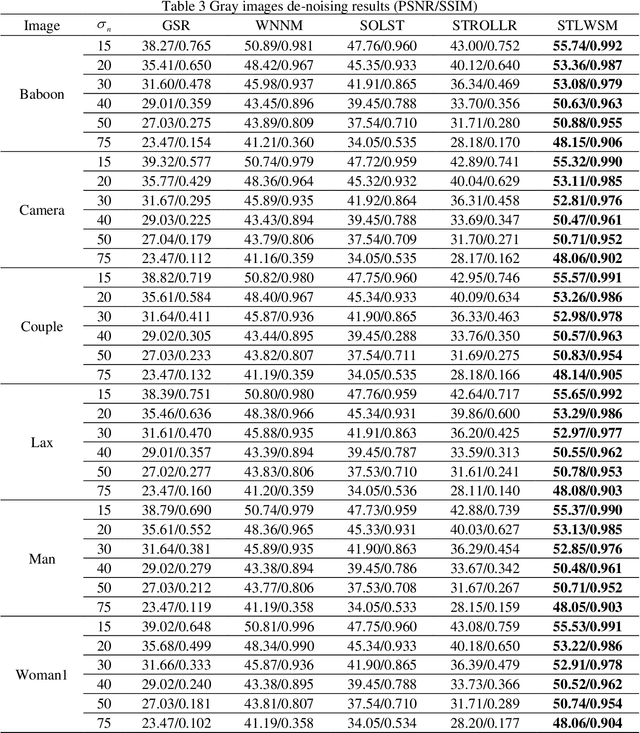
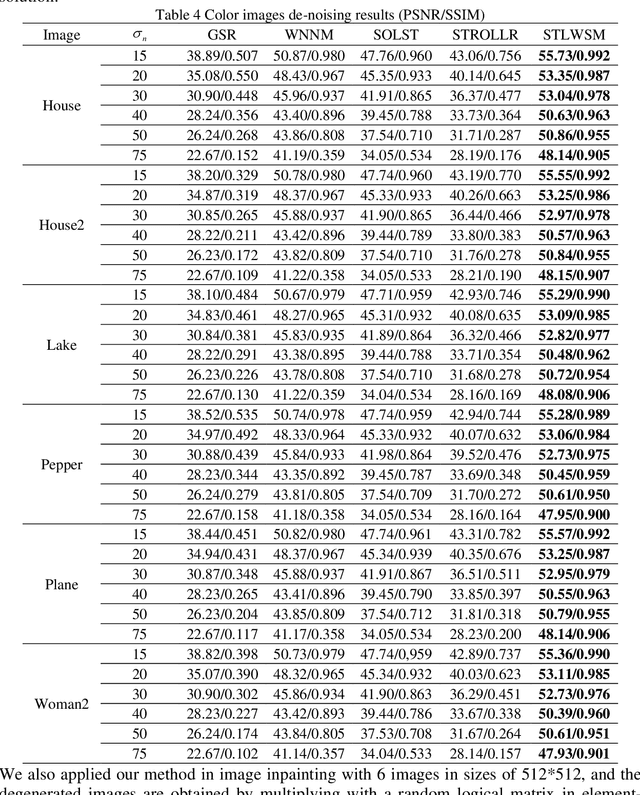
In image denoising (IDN) processing, the low-rank property is usually considered as an important image prior. As a convex relaxation approximation of low rank, nuclear norm based algorithms and their variants have attracted significant attention. These algorithms can be collectively called image domain based methods, whose common drawback is the requirement of great number of iterations for some acceptable solution. Meanwhile, the sparsity of images in a certain transform domain has also been exploited in image denoising problems. Sparsity transform learning algorithms can achieve extremely fast computations as well as desirable performance. By taking both advantages of image domain and transform domain in a general framework, we propose a sparsity transform learning and weighted singular values minimization method (STLWSM) for IDN problems. The proposed method can make full use of the preponderance of both domains. For solving the non-convex cost function, we also present an efficient alternative solution for acceleration. Experimental results show that the proposed STLWSM achieves improvement both visually and quantitatively with a large margin over state-of-the-art approaches based on an alternatively single domain. It also needs much less iteration than all the image domain algorithms.