 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB-MSMUNet:Dual Branch Multi-scale Mamba UNet for Pancreatic CT Scans Segmentation
Jan 08, 2026Accurate segmentation of the pancreas and its lesions in CT scans is crucial for the precise diagnosis and treatment of pancreatic cancer. However, it remains a highly challenging task due to several factors such as low tissue contrast with surrounding organs, blurry anatomical boundaries, irregular organ shapes, and the small size of lesions. To tackle these issues, we propose DB-MSMUNet (Dual-Branch Multi-scale Mamba UNet), a novel encoder-decoder architecture designed specifically for robust pancreatic segmentation. The encoder is constructed using a Multi-scale Mamba Module (MSMM), which combines deformable convolutions and multi-scale state space modeling to enhance both global context modeling and local deformation adaptation. The network employs a dual-decoder design: the edge decoder introduces an Edge Enhancement Path (EEP) to explicitly capture boundary cues and refine fuzzy contours, while the area decoder incorporates a Multi-layer Decoder (MLD) to preserve fine-grained details and accurately reconstruct small lesions by leveraging multi-scale deep semantic features. Furthermore, Auxiliary Deep Supervision (ADS) heads are added at multiple scales to both decoders, providing more accurate gradient feedback and further enhancing the discriminative capability of multi-scale features. We conduct extensive experiments on three datasets: the NIH Pancreas dataset, the MSD dataset, and a clinical pancreatic tumor dataset provided by collaborating hospitals. DB-MSMUNet achieves Dice Similarity Coefficients of 89.47%, 87.59%, and 89.02%, respectively, outperforming most existing state-of-the-art methods in terms of segmentation accuracy, edge preservation, and robustness across different datasets. These results demonstrate the effectiveness and generalizability of the proposed method for real-world pancreatic CT segmentation tasks.
Tracking large chemical reaction networks and rare events by neural networks
Dec 13, 2025Chemical reaction networks are widely used to model stochastic dynamics in chemical kinetics, systems biology and epidemiology. Solving the chemical master equation that governs these systems poses a significant challenge due to the large state space exponentially growing with system sizes. The development of autoregressive neural networks offers a flexible framework for this problem; however, its efficiency is limited especially for high-dimensional systems and in scenarios with rare events. Here, we push the frontier of neural-network approach by exploiting faster optimizations such as natural gradient descent and time-dependent variational principle, achieving a 5- to 22-fold speedup, and by leveraging enhanced-sampling strategies to capture rare events. We demonstrate reduced computational cost and higher accuracy over the previous neural-network method in challenging reaction networks, including the mitogen-activated protein kinase (MAPK) cascade network, the hitherto largest biological network handled by the previous approaches of solving the chemical master equation. We further apply the approach to spatially extended reaction-diffusion systems, the Schlögl model with rare events, on two-dimensional lattices, beyond the recent tensor-network approach that handles one-dimensional lattices. The present approach thus enables efficient modeling of chemical reaction networks in general.
Quantum Flow Matching
Aug 17, 2025Flow matching has rapidly become a dominant paradigm in classical generative modeling, offering an efficient way to interpolate between two complex distributions. We extend this idea to the quantum realm and introduce Quantum Flow Matching (QFM)-a fully quantum-circuit realization that offers efficient interpolation between two density matrices. QFM offers systematic preparation of density matrices and generation of samples for accurately estimating observables, and can be realized on a quantum computer without the need for costly circuit redesigns. We validate its versatility on a set of applications: (i) generating target states with prescribed magnetization and entanglement entropy, (ii) estimating nonequilibrium free-energy differences to test the quantum Jarzynski equality, and (iii) expediting the study on superdiffusion breakdown. These results position QFM as a unifying and promising framework for generative modeling across quantum systems.
MHAF-YOLO: Multi-Branch Heterogeneous Auxiliary Fusion YOLO for accurate object detection
Feb 07, 2025Due to the effective multi-scale feature fusion capabilities of the Path Aggregation FPN (PAFPN), it has become a widely adopted component in YOLO-based detectors. However, PAFPN struggles to integrate high-level semantic cues with low-level spatial details, limiting its performance in real-world applications, especially with significant scale variations. In this paper, we propose MHAF-YOLO, a novel detection framework featuring a versatile neck design called the Multi-Branch Auxiliary FPN (MAFPN), which consists of two key modules: the Superficial Assisted Fusion (SAF) and Advanced Assisted Fusion (AAF). The SAF bridges the backbone and the neck by fusing shallow features, effectively transferring crucial low-level spatial information with high fidelity. Meanwhile, the AAF integrates multi-scale feature information at deeper neck layers, delivering richer gradient information to the output layer and further enhancing the model learning capacity. To complement MAFPN, we introduce the Global Heterogeneous Flexible Kernel Selection (GHFKS) mechanism and the Reparameterized Heterogeneous Multi-Scale (RepHMS) module to enhance feature fusion. RepHMS is globally integrated into the network, utilizing GHFKS to select larger convolutional kernels for various feature layers, expanding the vertical receptive field and capturing contextual information across spatial hierarchies. Locally, it optimizes convolution by processing both large and small kernels within the same layer, broadening the lateral receptive field and preserving crucial details for detecting smaller targets. The source code of this work is available at: https://github.com/yang0201/MHAF-YOLO.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
EdgeOAR: Real-time Online Action Recognition On Edge Devices
Dec 02, 2024



This paper addresses the challenges of Online Action Recognition (OAR), a framework that involves instantaneous analysis and classification of behaviors in video streams. OAR must operate under stringent latency constraints, making it an indispensable component for real-time feedback for edge computing. Existing methods, which typically rely on the processing of entire video clips, fall short in scenarios requiring immediate recognition. To address this, we designed EdgeOAR, a novel framework specifically designed for OAR on edge devices. EdgeOAR includes the Early Exit-oriented Task-specific Feature Enhancement Module (TFEM), which comprises lightweight submodules to optimize features in both temporal and spatial dimensions. We design an iterative training method to enable TFEM learning features from the beginning of the video. Additionally, EdgeOAR includes an Inverse Information Entropy (IIE) and Modality Consistency (MC)-driven fusion module to fuse features and make better exit decisions. This design overcomes the two main challenges: robust modeling of spatio-temporal action representations with limited initial frames in online video streams and balancing accuracy and efficiency on resource-constrained edge devices. Experiments show that on the UCF-101 dataset, our method EdgeOAR reduces latency by 99.23% and energy consumption by 99.28% compared to state-of-the-art (SOTA) method. And achieves an adequate accuracy on edge devices.
The Evolution and Future Perspectives of Artificial Intelligence Generated Content
Dec 02, 2024



Artificial intelligence generated content (AIGC), a rapidly advancing technology, is transforming content creation across domains, such as text, images, audio, and video. Its growing potential has attracted more and more researchers and investors to explore and expand its possibilities. This review traces AIGC's evolution through four developmental milestones-ranging from early rule-based systems to modern transfer learning models-within a unified framework that highlights how each milestone contributes uniquely to content generation. In particular, the paper employs a common example across all milestones to illustrate the capabilities and limitations of methods within each phase, providing a consistent evaluation of AIGC methodologies and their development. Furthermore, this paper addresses critical challenges associated with AIGC and proposes actionable strategies to mitigate them. This study aims to guide researchers and practitioners in selecting and optimizing AIGC models to enhance the quality and efficiency of content creation across diverse domains.
Autogenic Language Embedding for Coherent Point Tracking
Jul 30, 2024
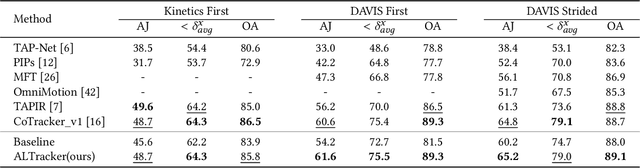


Point tracking is a challenging task in computer vision, aiming to establish point-wise correspondence across long video sequences. Recent advancements have primarily focused on temporal modeling techniques to improve local feature similarity, often overlooking the valuable semantic consistency inherent in tracked points. In this paper, we introduce a novel approach leveraging language embeddings to enhance the coherence of frame-wise visual features related to the same object. Our proposed method, termed autogenic language embedding for visual feature enhancement, strengthens point correspondence in long-term sequences. Unlike existing visual-language schemes, our approach learns text embeddings from visual features through a dedicated mapping network, enabling seamless adaptation to various tracking tasks without explicit text annotations. Additionally, we introduce a consistency decoder that efficiently integrates text tokens into visual features with minimal computational overhead. Through enhanced visual consistency, our approach significantly improves tracking trajectories in lengthy videos with substantial appearance variations. Extensive experiments on widely-used tracking benchmarks demonstrate the superior performance of our method, showcasing notable enhancements compared to trackers relying solely on visual cues.
Ontology-driven Reinforcement Learning for Personalized Student Support
Jul 14, 2024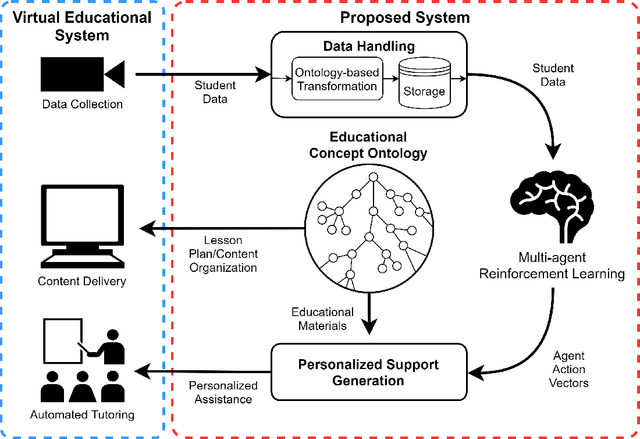
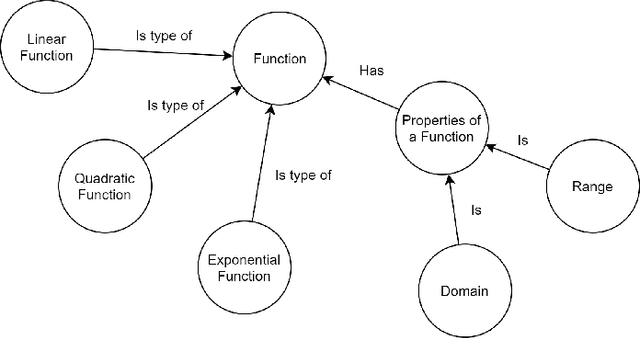
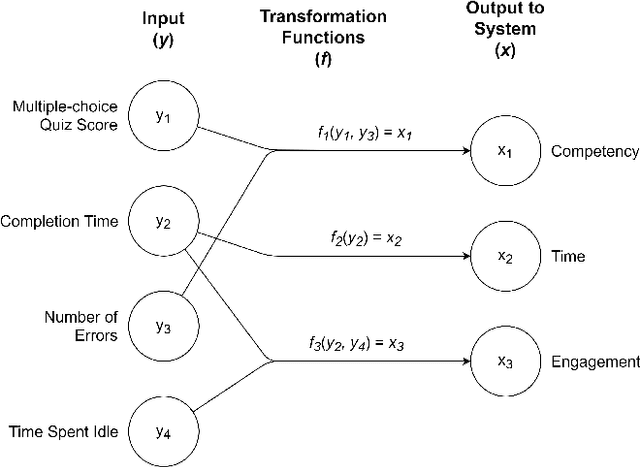
In the search for more effective education, there is a widespread effort to develop better approaches to personalize student education. Unassisted, educators often do not have time or resources to personally support every student in a given classroom. Motivated by this issue, and by recent advancements in artificial intelligence, this paper presents a general-purpose framework for personalized student support, applicable to any virtual educational system such as a serious game or an intelligent tutoring system. To fit any educational situation, we apply ontologies for their semantic organization, combining them with data collection considerations and multi-agent reinforcement learning. The result is a modular system that can be adapted to any virtual educational software to provide useful personalized assistance to students.
Multi-Branch Auxiliary Fusion YOLO with Re-parameterization Heterogeneous Convolutional for accurate object detection
Jul 05, 2024


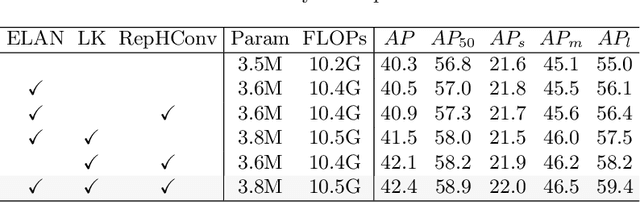
Due to the effective performance of multi-scale feature fusion, Path Aggregation FPN (PAFPN) is widely employed in YOLO detectors. However, it cannot efficiently and adaptively integrate high-level semantic information with low-level spatial information simultaneously. We propose a new model named MAF-YOLO in this paper, which is a novel object detection framework with a versatile neck named Multi-Branch Auxiliary FPN (MAFPN). Within MAFPN, the Superficial Assisted Fusion (SAF) module is designed to combine the output of the backbone with the neck, preserving an optimal level of shallow information to facilitate subsequent learning. Meanwhile, the Advanced Assisted Fusion (AAF) module deeply embedded within the neck conveys a more diverse range of gradient information to the output layer. Furthermore, our proposed Re-parameterized Heterogeneous Efficient Layer Aggregation Network (RepHELAN) module ensures that both the overall model architecture and convolutional design embrace the utilization of heterogeneous large convolution kernels. Therefore, this guarantees the preservation of information related to small targets while simultaneously achieving the multi-scale receptive field. Finally, taking the nano version of MAF-YOLO for example, it can achieve 42.4% AP on COCO with only 3.76M learnable parameters and 10.51G FLOPs, and approximately outperforms YOLOv8n by about 5.1%. The source code of this work is available at: https://github.com/yang-0201/MAF-YOLO.