 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECAFormer: Low-light Image Enhancement using Cross Attention
Jun 19, 2024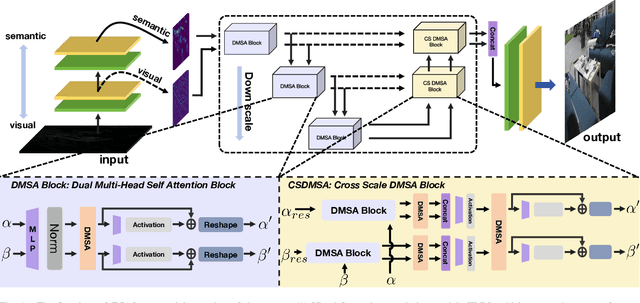

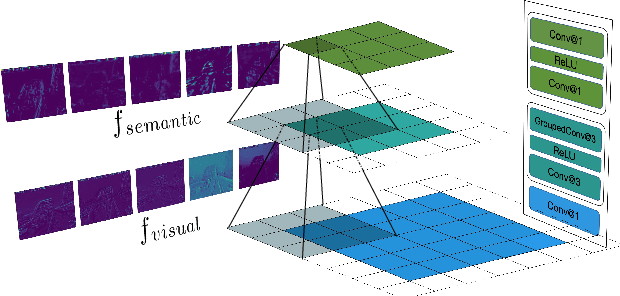

Low-light image enhancement (LLIE) is vital for autonomous driving. Despite the importance, existing LLIE methods often prioritize robustness in overall brightness adjustment, which can come at the expense of detail preservation. To overcome this limitation,we propose the Hierarchical Mutual Enhancement via Cross-Attention transformer (ECAFormer), a novel network that utilizes Dual Multi-head Self Attention (DMSA) to enhance both visual and semantic features across scales, significantly preserving details during the process. The cross-attention mechanism in ECAFormer not only improves upon traditional enhancement techniques but also excels in maintaining a balance between global brightness adjustment and local detail retention. Our extensive experimental validation on renowned low-illumination datasets, including SID and LOL, and additional tests on dark road scenarios. or performance over existing methods in terms of illumination enhancement and noise reduction, while also optimizing computational complexity and parameter count, further boosting SSIM and PSNR metrics. Our project is available at https://github.com/ruanyudi/ECAFormer.
TIDE: Test Time Few Shot Object Detection
Nov 30, 2023Few-shot object detection (FSOD) aims to extract semantic knowledge from limited object instances of novel categories within a target domain. Recent advances in FSOD focus on fine-tuning the base model based on a few objects via meta-learning or data augmentation. Despite their success, the majority of them are grounded with parametric readjustment to generalize on novel objects, which face considerable challenges in Industry 5.0, such as (i) a certain amount of fine-tuning time is required, and (ii) the parameters of the constructed model being unavailable due to the privilege protection, making the fine-tuning fail. Such constraints naturally limit its application in scenarios with real-time configuration requirements or within black-box settings. To tackle the challenges mentioned above, we formalize a novel FSOD task, referred to as Test TIme Few Shot DEtection (TIDE), where the model is un-tuned in the configuration procedure. To that end, we introduce an asymmetric architecture for learning a support-instance-guided dynamic category classifier. Further, a cross-attention module and a multi-scale resizer are provided to enhance the model performance. Experimental results on multiple few-shot object detection platforms reveal that the proposed TIDE significantly outperforms existing contemporary methods. The implementation codes are available at https://github.com/deku-0621/TIDE
Boosting Few-shot Action Recognition with Graph-guided Hybrid Matching
Aug 18, 2023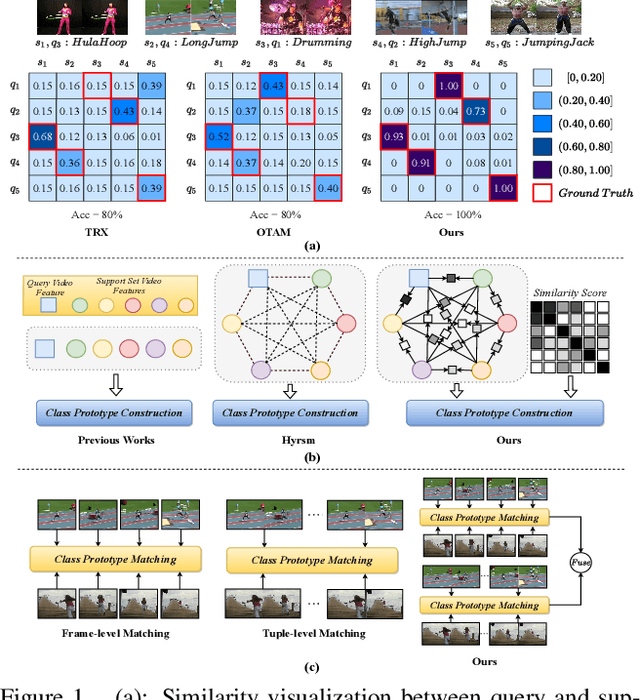
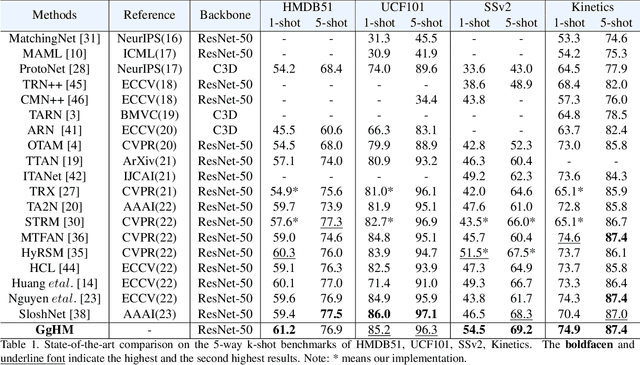

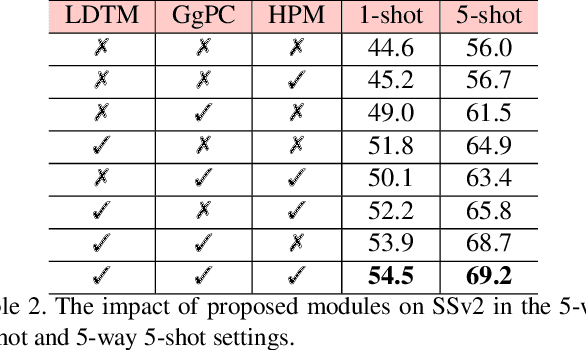
Class prototype construction and matching are core aspects of few-shot action recognition. Previous methods mainly focus on designing spatiotemporal relation modeling modules or complex temporal alignment algorithms. Despite the promising results, they ignored the value of class prototype construction and matching, leading to unsatisfactory performance in recognizing similar categories in every task. In this paper, we propose GgHM, a new framework with Graph-guided Hybrid Matching. Concretely, we learn task-oriented features by the guidance of a graph neural network during class prototype construction, optimizing the intra- and inter-class feature correlation explicitly. Next, we design a hybrid matching strategy, combining frame-level and tuple-level matching to classify videos with multivariate styles. We additionally propose a learnable dense temporal modeling module to enhance the video feature temporal representation to build a more solid foundation for the matching process. GgHM shows consistent improvements over other challenging baselines on several few-shot datasets, demonstrating the effectiveness of our method. The code will be publicly available at https://github.com/jiazheng-xing/GgHM.