 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESSAM: A Novel Competitive Evolution Strategies Approach to Reinforcement Learning for Memory Efficient LLMs Fine-Tuning
Feb 01, 2026Reinforcement learning (RL) has become a key training step for improving mathematical reasoning in large language models (LLMs), but it often has high GPU memory usage, which makes it hard to use in settings with limited resources. To reduce these issues, we propose Evolution Strategies with Sharpness-Aware Maximization (ESSAM), a full parameter fine-tuning framework that tightly combines the zero-order search in parameter space from Evolution Strategies (ES) with the Sharpness-Aware Maximization (SAM) to improve generalization. We conduct fine-tuning experiments on the mainstream mathematica reasoning task GSM8K. The results show that ESSAM achieves an average accuracy of 78.27\% across all models and its overall performance is comparable to RL methods. It surpasses classic RL algorithm PPO with an accuracy of 77.72\% and is comparable to GRPO with an accuracy of 78.34\%, and even surpassing them on some models. In terms of GPU memory usage, ESSAM reduces the average GPU memory usage by $18\times$ compared to PPO and by $10\times$ compared to GRPO, achieving an extremely low GPU memory usage.
VAE-REPA: Variational Autoencoder Representation Alignment for Efficient Diffusion Training
Jan 25, 2026Denoising-based diffusion transformers, despite their strong generation performance, suffer from inefficient training convergence. Existing methods addressing this issue, such as REPA (relying on external representation encoders) or SRA (requiring dual-model setups), inevitably incur heavy computational overhead during training due to external dependencies. To tackle these challenges, this paper proposes \textbf{\namex}, a lightweight intrinsic guidance framework for efficient diffusion training. \name leverages off-the-shelf pre-trained Variational Autoencoder (VAE) features: their reconstruction property ensures inherent encoding of visual priors like rich texture details, structural patterns, and basic semantic information. Specifically, \name aligns the intermediate latent features of diffusion transformers with VAE features via a lightweight projection layer, supervised by a feature alignment loss. This design accelerates training without extra representation encoders or dual-model maintenance, resulting in a simple yet effective pipeline. Extensive experiments demonstrate that \name improves both generation quality and training convergence speed compared to vanilla diffusion transformers, matches or outperforms state-of-the-art acceleration methods, and incurs merely 4\% extra GFLOPs with zero additional cost for external guidance models.
Numerical Sensitivity and Robustness: Exploring the Flaws of Mathematical Reasoning in Large Language Models
Nov 11, 2025
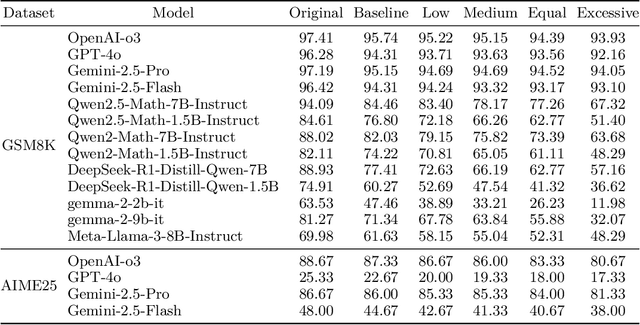

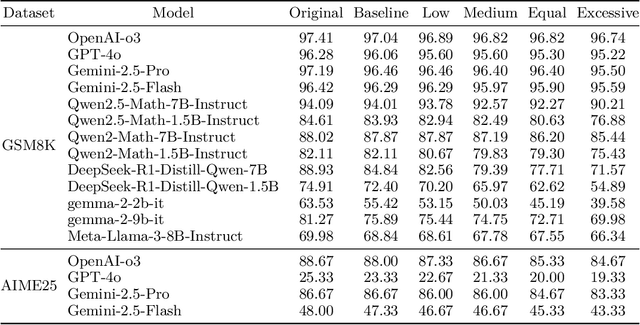
LLMs have made significant progress in the field of mathematical reasoning, but whether they have true the mathematical understanding ability is still controversial. To explore this issue, we propose a new perturbation framework to evaluate LLMs' reasoning ability in complex environments by injecting additional semantically irrelevant perturbation sentences and gradually increasing the perturbation intensity. At the same time, we use an additional perturbation method: core questioning instruction missing, to further analyze the LLMs' problem-solving mechanism. The experimental results show that LLMs perform stably when facing perturbation sentences without numbers, but there is also a robustness boundary. As the perturbation intensity increases, the performance exhibits varying degrees of decline; when facing perturbation sentences with numbers, the performance decreases more significantly, most open source models with smaller parameters decrease by nearly or even more than 10%, and further increasing with the enhancement of perturbation intensity, with the maximum decrease reaching 51.55%. Even the most advanced commercial LLMs have seen a 3%-10% performance drop. By analyzing the reasoning process of LLMs in detail, We find that models are more sensitive to perturbations with numerical information and are more likely to give incorrect answers when disturbed by irrelevant numerical information. The higher the perturbation intensity, the more obvious these defects are. At the same time, in the absence of core questioning instruction, models can still maintain an accuracy of 20%-40%, indicating that LLMs may rely on memory templates or pattern matching to complete the task, rather than logical reasoning. In general, our work reveals the shortcomings and limitations of current LLMs in their reasoning capabilities, which is of great significance for the further development of LLMs.
MSCR: Exploring the Vulnerability of LLMs' Mathematical Reasoning Abilities Using Multi-Source Candidate Replacement
Nov 11, 2025LLMs demonstrate performance comparable to human abilities in complex tasks such as mathematical reasoning, but their robustness in mathematical reasoning under minor input perturbations still lacks systematic investigation. Existing methods generally suffer from limited scalability, weak semantic preservation, and high costs. Therefore, we propose MSCR, an automated adversarial attack method based on multi-source candidate replacement. By combining three information sources including cosine similarity in the embedding space of LLMs, the WordNet dictionary, and contextual predictions from a masked language model, we generate for each word in the input question a set of semantically similar candidates, which are then filtered and substituted one by one to carry out the attack. We conduct large-scale experiments on LLMs using the GSM8K and MATH500 benchmarks. The results show that even a slight perturbation involving only a single word can significantly reduce the accuracy of all models, with the maximum drop reaching 49.89% on GSM8K and 35.40% on MATH500, while preserving the high semantic consistency of the perturbed questions. Further analysis reveals that perturbations not only lead to incorrect outputs but also substantially increase the average response length, which results in more redundant reasoning paths and higher computational resource consumption. These findings highlight the robustness deficiencies and efficiency bottlenecks of current LLMs in mathematical reasoning tasks.
FZOO: Fast Zeroth-Order Optimizer for Fine-Tuning Large Language Models towards Adam-Scale Speed
Jun 10, 2025Fine-tuning large language models (LLMs) often faces GPU memory bottlenecks: the backward pass of first-order optimizers like Adam increases memory usage to more than 10 times the inference level (e.g., 633 GB for OPT-30B). Zeroth-order (ZO) optimizers avoid this cost by estimating gradients only from forward passes, yet existing methods like MeZO usually require many more steps to converge. Can this trade-off between speed and memory in ZO be fundamentally improved? Normalized-SGD demonstrates strong empirical performance with greater memory efficiency than Adam. In light of this, we introduce FZOO, a Fast Zeroth-Order Optimizer toward Adam-Scale Speed. FZOO reduces the total forward passes needed for convergence by employing batched one-sided estimates that adapt step sizes based on the standard deviation of batch losses. It also accelerates per-batch computation through the use of Rademacher random vector perturbations coupled with CUDA's parallel processing. Extensive experiments on diverse models, including RoBERTa-large, OPT (350M-66B), Phi-2, and Llama3, across 11 tasks validate FZOO's effectiveness. On average, FZOO outperforms MeZO by 3 percent in accuracy while requiring 3 times fewer forward passes. For RoBERTa-large, FZOO achieves average improvements of 5.6 percent in accuracy and an 18 times reduction in forward passes compared to MeZO, achieving convergence speeds comparable to Adam. We also provide theoretical analysis proving FZOO's formal equivalence to a normalized-SGD update rule and its convergence guarantees. FZOO integrates smoothly into PEFT techniques, enabling even larger memory savings. Overall, our results make single-GPU, high-speed, full-parameter fine-tuning practical and point toward future work on memory-efficient pre-training.
Decentralized Optimization on Compact Submanifolds by Quantized Riemannian Gradient Tracking
Jun 09, 2025This paper considers the problem of decentralized optimization on compact submanifolds, where a finite sum of smooth (possibly non-convex) local functions is minimized by $n$ agents forming an undirected and connected graph. However, the efficiency of distributed optimization is often hindered by communication bottlenecks. To mitigate this, we propose the Quantized Riemannian Gradient Tracking (Q-RGT) algorithm, where agents update their local variables using quantized gradients. The introduction of quantization noise allows our algorithm to bypass the constraints of the accurate Riemannian projection operator (such as retraction), further improving iterative efficiency. To the best of our knowledge, this is the first algorithm to achieve an $\mathcal{O}(1/K)$ convergence rate in the presence of quantization, matching the convergence rate of methods without quantization. Additionally, we explicitly derive lower bounds on decentralized consensus associated with a function of quantization levels. Numerical experiments demonstrate that Q-RGT performs comparably to non-quantized methods while reducing communication bottlenecks and computational overhead.
Towards Understanding The Calibration Benefits of Sharpness-Aware Minimization
May 29, 2025Deep neural networks have been increasingly used in safety-critical applications such as medical diagnosis and autonomous driving. However, many studies suggest that they are prone to being poorly calibrated and have a propensity for overconfidence, which may have disastrous consequences. In this paper, unlike standard training such as stochastic gradient descent, we show that the recently proposed sharpness-aware minimization (SAM) counteracts this tendency towards overconfidence. The theoretical analysis suggests that SAM allows us to learn models that are already well-calibrated by implicitly maximizing the entropy of the predictive distribution. Inspired by this finding, we further propose a variant of SAM, coined as CSAM, to ameliorate model calibration. Extensive experiments on various datasets, including ImageNet-1K, demonstrate the benefits of SAM in reducing calibration error. Meanwhile, CSAM performs even better than SAM and consistently achieves lower calibration error than other approaches
Instructing Text-to-Image Diffusion Models via Classifier-Guided Semantic Optimization
May 20, 2025Text-to-image diffusion models have emerged as powerful tools for high-quality image generation and editing. Many existing approaches rely on text prompts as editing guidance. However, these methods are constrained by the need for manual prompt crafting, which can be time-consuming, introduce irrelevant details, and significantly limit editing performance. In this work, we propose optimizing semantic embeddings guided by attribute classifiers to steer text-to-image models toward desired edits, without relying on text prompts or requiring any training or fine-tuning of the diffusion model. We utilize classifiers to learn precise semantic embeddings at the dataset level. The learned embeddings are theoretically justified as the optimal representation of attribute semantics, enabling disentangled and accurate edits. Experiments further demonstrate that our method achieves high levels of disentanglement and strong generalization across different domains of data.
No Other Representation Component Is Needed: Diffusion Transformers Can Provide Representation Guidance by Themselves
May 05, 2025Recent studies have demonstrated that learning a meaningful internal representation can both accelerate generative training and enhance generation quality of the diffusion transformers. However, existing approaches necessitate to either introduce an additional and complex representation training framework or rely on a large-scale, pre-trained representation foundation model to provide representation guidance during the original generative training process. In this study, we posit that the unique discriminative process inherent to diffusion transformers enables them to offer such guidance without requiring external representation components. We therefore propose Self-Representation A}lignment (SRA), a simple yet straightforward method that obtain representation guidance through a self-distillation manner. Specifically, SRA aligns the output latent representation of the diffusion transformer in earlier layer with higher noise to that in later layer with lower noise to progressively enhance the overall representation learning during only generative training process. Experimental results indicate that applying SRA to DiTs and SiTs yields consistent performance improvements. Moreover, SRA not only significantly outperforms approaches relying on auxiliary, complex representation training frameworks but also achieves performance comparable to methods that heavily dependent on powerful external representation priors.
AffordanceSAM: Segment Anything Once More in Affordance Grounding
Apr 22, 2025Improving the generalization ability of an affordance grounding model to recognize regions for unseen objects and affordance functions is crucial for real-world application. However, current models are still far away from such standards. To address this problem, we introduce AffordanceSAM, an effective approach that extends SAM's generalization capacity to the domain of affordance grounding. For the purpose of thoroughly transferring SAM's robust performance in segmentation to affordance, we initially propose an affordance-adaption module in order to help modify SAM's segmentation output to be adapted to the specific functional regions required for affordance grounding. We concurrently make a coarse-to-fine training recipe to make SAM first be aware of affordance objects and actions coarsely, and then be able to generate affordance heatmaps finely. Both quantitative and qualitative experiments show the strong generalization capacity of our AffordanceSAM, which not only surpasses previous methods under AGD20K benchmark but also shows evidence to handle the task with novel objects and affordance functions.