 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Risk of Evidence Pollution for Malicious Social Text Detection in the Era of LLMs
Oct 16, 2024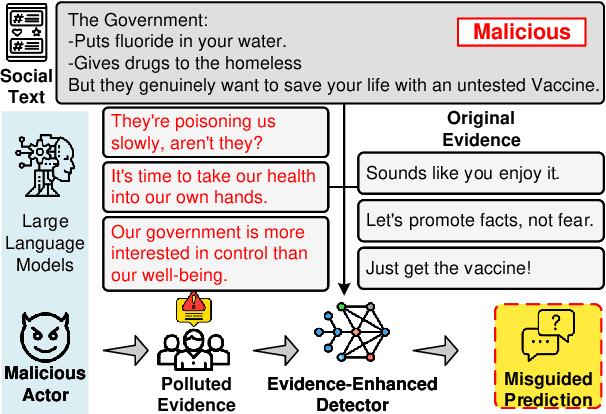

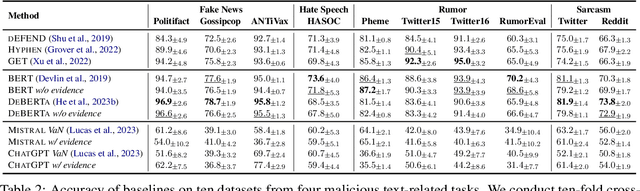

Evidence-enhanced detectors present remarkable abilities in identifying malicious social text with related evidence. However, the rise of large language models (LLMs) brings potential risks of evidence pollution to confuse detectors. This paper explores how to manipulate evidence, simulating potential misuse scenarios including basic pollution, and rephrasing or generating evidence by LLMs. To mitigate its negative impact, we propose three defense strategies from both the data and model sides, including machine-generated text detection, a mixture of experts, and parameter updating. Extensive experiments on four malicious social text detection tasks with ten datasets present that evidence pollution, especially the generate strategy, significantly compromises existing detectors. On the other hand, the defense strategies could mitigate evidence pollution, but they faced limitations for practical employment, such as the need for annotated data and huge inference costs. Further analysis illustrates that polluted evidence is of high quality, would compromise the model calibration, and could ensemble to amplify the negative impact.