 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Model Bias for Generalized Category Discovery
Dec 17, 2024



Generalized Category Discovery is a significant and complex task that aims to identify both known and undefined novel categories from a set of unlabeled data, leveraging another labeled dataset containing only known categories. The primary challenges stem from model bias induced by pre-training on only known categories and the lack of precise supervision for novel ones, leading to category bias towards known categories and category confusion among different novel categories, which hinders models' ability to identify novel categories effectively. To address these challenges, we propose a novel framework named Self-Debiasing Calibration (SDC). Unlike prior methods that regard model bias towards known categories as an obstacle to novel category identification, SDC provides a novel insight into unleashing the potential of the bias to facilitate novel category learning. Specifically, the output of the biased model serves two key purposes. First, it provides an accurate modeling of category bias, which can be utilized to measure the degree of bias and debias the output of the current training model. Second, it offers valuable insights for distinguishing different novel categories by transferring knowledge between similar categories. Based on these insights, SDC dynamically adjusts the output logits of the current training model using the output of the biased model. This approach produces less biased logits to effectively address the issue of category bias towards known categories, and generates more accurate pseudo labels for unlabeled data, thereby mitigating category confusion for novel categories. Experiments on three benchmark datasets show that SDC outperforms SOTA methods, especially in the identification of novel categories. Our code and data are available at \url{https://github.com/Lackel/SDC}.
Knowledge Acquisition Disentanglement for Knowledge-based Visual Question Answering with Large Language Models
Jul 22, 2024



Knowledge-based Visual Question Answering (KVQA) requires both image and world knowledge to answer questions. Current methods first retrieve knowledge from the image and external knowledge base with the original complex question, then generate answers with Large Language Models (LLMs). However, since the original question contains complex elements that require knowledge from different sources, acquiring different kinds of knowledge in a coupled manner may confuse models and hinder them from retrieving precise knowledge. Furthermore, the ``forward-only'' answering process fails to explicitly capture the knowledge needs of LLMs, which can further hurt answering quality. To cope with the above limitations, we propose DKA: Disentangled Knowledge Acquisition from LLM feedback, a training-free framework that disentangles knowledge acquisition to avoid confusion and uses LLM's feedback to specify the required knowledge. Specifically, DKA requires LLMs to specify what knowledge they need to answer the question and decompose the original complex question into two simple sub-questions: Image-based sub-question and Knowledge-based sub-question. Then we use the two sub-questions to retrieve knowledge from the image and knowledge base, respectively. In this way, two knowledge acquisition models can focus on the content that corresponds to them and avoid disturbance of irrelevant elements in the original complex question, which can help to provide more precise knowledge and better align the knowledge needs of LLMs to yield correct answers. Experiments on benchmark datasets show that DKA significantly outperforms SOTA models. To facilitate future research, our data and code are available at \url{https://github.com/Lackel/DKA}.
Transfer and Alignment Network for Generalized Category Discovery
Dec 27, 2023



Generalized Category Discovery is a crucial real-world task. Despite the improved performance on known categories, current methods perform poorly on novel categories. We attribute the poor performance to two reasons: biased knowledge transfer between labeled and unlabeled data and noisy representation learning on the unlabeled data. To mitigate these two issues, we propose a Transfer and Alignment Network (TAN), which incorporates two knowledge transfer mechanisms to calibrate the biased knowledge and two feature alignment mechanisms to learn discriminative features. Specifically, we model different categories with prototypes and transfer the prototypes in labeled data to correct model bias towards known categories. On the one hand, we pull instances with known categories in unlabeled data closer to these prototypes to form more compact clusters and avoid boundary overlap between known and novel categories. On the other hand, we use these prototypes to calibrate noisy prototypes estimated from unlabeled data based on category similarities, which allows for more accurate estimation of prototypes for novel categories that can be used as reliable learning targets later. After knowledge transfer, we further propose two feature alignment mechanisms to acquire both instance- and category-level knowledge from unlabeled data by aligning instance features with both augmented features and the calibrated prototypes, which can boost model performance on both known and novel categories with less noise. Experiments on three benchmark datasets show that our model outperforms SOTA methods, especially on novel categories. Theoretical analysis is provided for an in-depth understanding of our model in general. Our code and data are available at https://github.com/Lackel/TAN.
Generalized Category Discovery with Large Language Models in the Loop
Dec 18, 2023
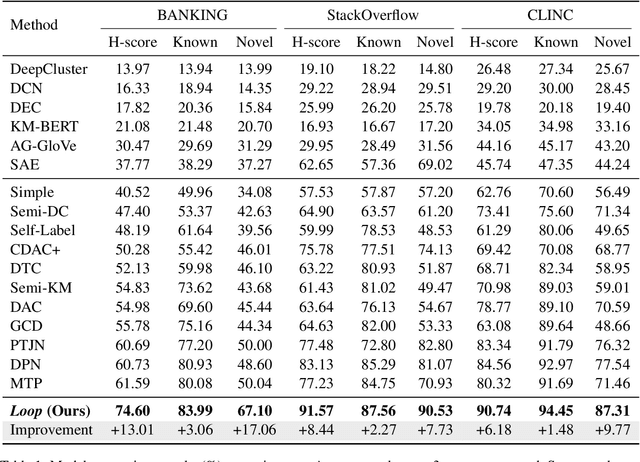

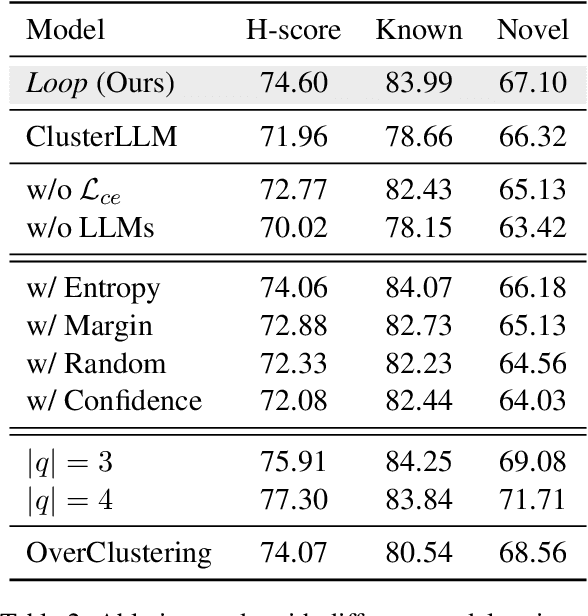
Generalized Category Discovery (GCD) is a crucial task that aims to recognize both known and novel categories from a set of unlabeled data by utilizing a few labeled data with only known categories. Due to the lack of supervision and category information, current methods usually perform poorly on novel categories and struggle to reveal semantic meanings of the discovered clusters, which limits their applications in the real world. To mitigate above issues, we propose Loop, an end-to-end active-learning framework that introduces Large Language Models (LLMs) into the training loop, which can boost model performance and generate category names without relying on any human efforts. Specifically, we first propose Local Inconsistent Sampling (LIS) to select samples that have a higher probability of falling to wrong clusters, based on neighborhood prediction consistency and entropy of cluster assignment probabilities. Then we propose a Scalable Query strategy to allow LLMs to choose true neighbors of the selected samples from multiple candidate samples. Based on the feedback from LLMs, we perform Refined Neighborhood Contrastive Learning (RNCL) to pull samples and their neighbors closer to learn clustering-friendly representations. Finally, we select representative samples from clusters corresponding to novel categories to allow LLMs to generate category names for them. Extensive experiments on three benchmark datasets show that Loop outperforms SOTA models by a large margin and generates accurate category names for the discovered clusters. We will release our code and data after publication.
A Diffusion Weighted Graph Framework for New Intent Discovery
Oct 24, 2023New Intent Discovery (NID) aims to recognize both new and known intents from unlabeled data with the aid of limited labeled data containing only known intents. Without considering structure relationships between samples, previous methods generate noisy supervisory signals which cannot strike a balance between quantity and quality, hindering the formation of new intent clusters and effective transfer of the pre-training knowledge. To mitigate this limitation, we propose a novel Diffusion Weighted Graph Framework (DWGF) to capture both semantic similarities and structure relationships inherent in data, enabling more sufficient and reliable supervisory signals. Specifically, for each sample, we diffuse neighborhood relationships along semantic paths guided by the nearest neighbors for multiple hops to characterize its local structure discriminately. Then, we sample its positive keys and weigh them based on semantic similarities and local structures for contrastive learning. During inference, we further propose Graph Smoothing Filter (GSF) to explicitly utilize the structure relationships to filter high-frequency noise embodied in semantically ambiguous samples on the cluster boundary. Extensive experiments show that our method outperforms state-of-the-art models on all evaluation metrics across multiple benchmark datasets. Code and data are available at https://github.com/yibai-shi/DWGF.
DNA: Denoised Neighborhood Aggregation for Fine-grained Category Discovery
Oct 16, 2023Discovering fine-grained categories from coarsely labeled data is a practical and challenging task, which can bridge the gap between the demand for fine-grained analysis and the high annotation cost. Previous works mainly focus on instance-level discrimination to learn low-level features, but ignore semantic similarities between data, which may prevent these models learning compact cluster representations. In this paper, we propose Denoised Neighborhood Aggregation (DNA), a self-supervised framework that encodes semantic structures of data into the embedding space. Specifically, we retrieve k-nearest neighbors of a query as its positive keys to capture semantic similarities between data and then aggregate information from the neighbors to learn compact cluster representations, which can make fine-grained categories more separatable. However, the retrieved neighbors can be noisy and contain many false-positive keys, which can degrade the quality of learned embeddings. To cope with this challenge, we propose three principles to filter out these false neighbors for better representation learning. Furthermore, we theoretically justify that the learning objective of our framework is equivalent to a clustering loss, which can capture semantic similarities between data to form compact fine-grained clusters. Extensive experiments on three benchmark datasets show that our method can retrieve more accurate neighbors (21.31% accuracy improvement) and outperform state-of-the-art models by a large margin (average 9.96% improvement on three metrics). Our code and data are available at https://github.com/Lackel/DNA.
Point-GCC: Universal Self-supervised 3D Scene Pre-training via Geometry-Color Contrast
Jun 01, 2023


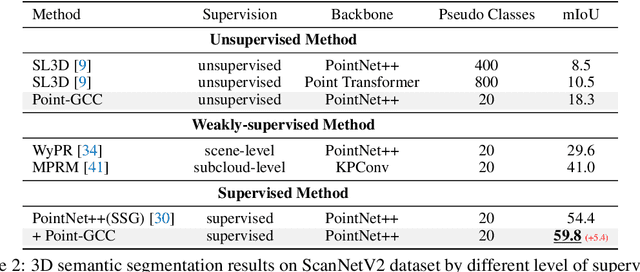
Geometry and color information provided by the point clouds are both crucial for 3D scene understanding. Two pieces of information characterize the different aspects of point clouds, but existing methods lack an elaborate design for the discrimination and relevance. Hence we explore a 3D self-supervised paradigm that can better utilize the relations of point cloud information. Specifically, we propose a universal 3D scene pre-training framework via Geometry-Color Contrast (Point-GCC), which aligns geometry and color information using a Siamese network. To take care of actual application tasks, we design (i) hierarchical supervision with point-level contrast and reconstruct and object-level contrast based on the novel deep clustering module to close the gap between pre-training and downstream tasks; (ii) architecture-agnostic backbone to adapt for various downstream models. Benefiting from the object-level representation associated with downstream tasks, Point-GCC can directly evaluate model performance and the result demonstrates the effectiveness of our methods. Transfer learning results on a wide range of tasks also show consistent improvements across all datasets. e.g., new state-of-the-art object detection results on SUN RGB-D and S3DIS datasets. Codes will be released at https://github.com/Asterisci/Point-GCC.