 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoT-CQA: Graph-of-Thought Guided Compositional Reasoning for Chart Question Answering
Sep 04, 2024
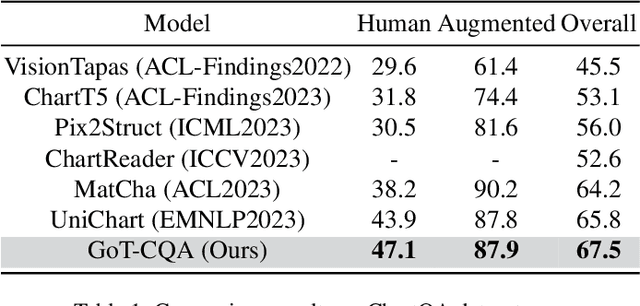
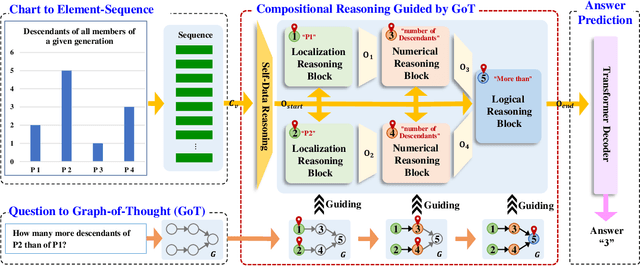
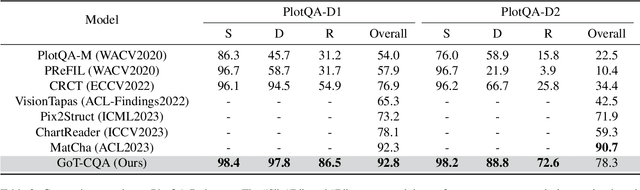
Chart Question Answering (CQA) aims at answering questions based on the visual chart content, which plays an important role in chart sumarization, business data analysis, and data report generation. CQA is a challenging multi-modal task because of the strong context dependence and complex reasoning requirement. The former refers to answering this question strictly based on the analysis of the visual content or internal data of the given chart, while the latter emphasizes the various logical and numerical reasoning involved in answer prediction process. In this paper, we pay more attention on the complex reasoning in CQA task, and propose a novel Graph-of-Thought (GoT) guided compositional reasoning model called GoT-CQA to overcome this problem. At first, we transform the chart-oriented question into a directed acyclic GoT composed of multiple operator nodes, including localization, numerical and logical operator. It intuitively reflects the human brain's solution process to this question. After that, we design an efficient auto-compositional reasoning framework guided by the GoT, to excute the multi-step reasoning operations in various types of questions. Comprehensive experiments on ChartQA and PlotQA-D datasets show that GoT-CQA achieves outstanding performance, especially in complex human-written and reasoning questions, comparing with the latest popular baselines.
Knowledge Acquisition Disentanglement for Knowledge-based Visual Question Answering with Large Language Models
Jul 22, 2024



Knowledge-based Visual Question Answering (KVQA) requires both image and world knowledge to answer questions. Current methods first retrieve knowledge from the image and external knowledge base with the original complex question, then generate answers with Large Language Models (LLMs). However, since the original question contains complex elements that require knowledge from different sources, acquiring different kinds of knowledge in a coupled manner may confuse models and hinder them from retrieving precise knowledge. Furthermore, the ``forward-only'' answering process fails to explicitly capture the knowledge needs of LLMs, which can further hurt answering quality. To cope with the above limitations, we propose DKA: Disentangled Knowledge Acquisition from LLM feedback, a training-free framework that disentangles knowledge acquisition to avoid confusion and uses LLM's feedback to specify the required knowledge. Specifically, DKA requires LLMs to specify what knowledge they need to answer the question and decompose the original complex question into two simple sub-questions: Image-based sub-question and Knowledge-based sub-question. Then we use the two sub-questions to retrieve knowledge from the image and knowledge base, respectively. In this way, two knowledge acquisition models can focus on the content that corresponds to them and avoid disturbance of irrelevant elements in the original complex question, which can help to provide more precise knowledge and better align the knowledge needs of LLMs to yield correct answers. Experiments on benchmark datasets show that DKA significantly outperforms SOTA models. To facilitate future research, our data and code are available at \url{https://github.com/Lackel/DKA}.
AGLA: Mitigating Object Hallucinations in Large Vision-Language Models with Assembly of Global and Local Attention
Jun 18, 2024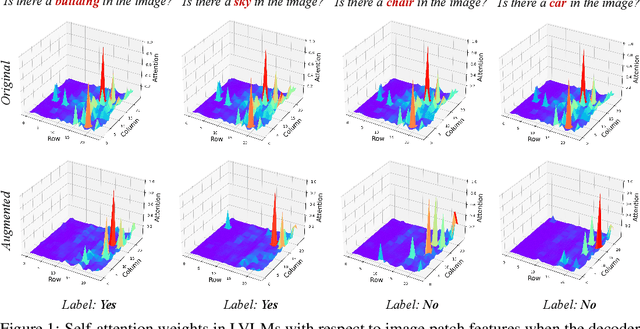
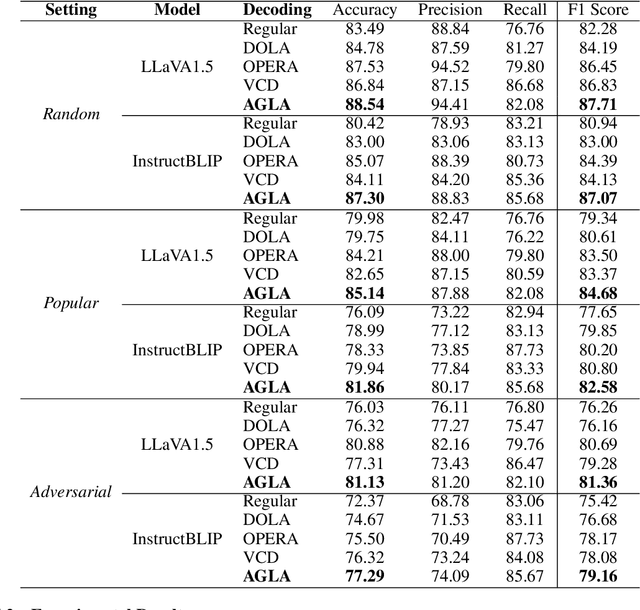
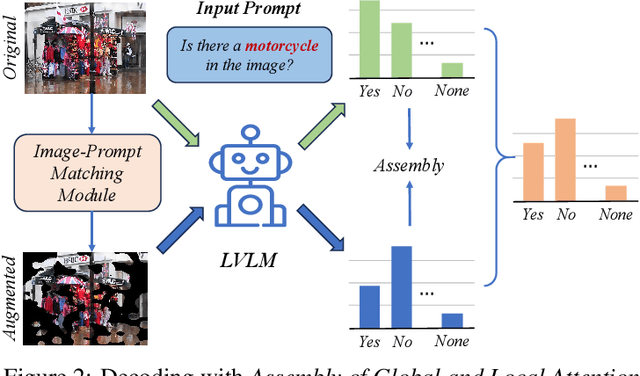
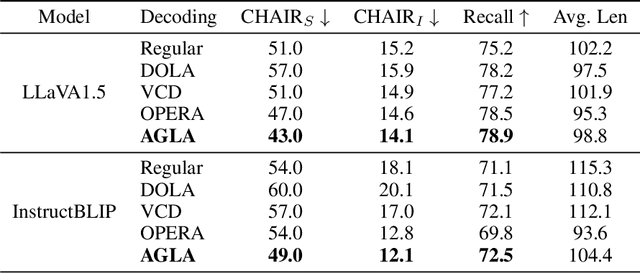
Despite their great success across various multimodal tasks, Large Vision-Language Models (LVLMs) are facing a prevalent problem with object hallucinations, where the generated textual responses are inconsistent with ground-truth objects in the given image. This paper investigates various LVLMs and pinpoints attention deficiency toward discriminative local image features as one root cause of object hallucinations. Specifically, LVLMs predominantly attend to prompt-independent global image features, while failing to capture prompt-relevant local features, consequently undermining the visual grounding capacity of LVLMs and leading to hallucinations. To this end, we propose Assembly of Global and Local Attention (AGLA), a training-free and plug-and-play approach that mitigates object hallucinations by exploring an ensemble of global features for response generation and local features for visual discrimination simultaneously. Our approach exhibits an image-prompt matching scheme that captures prompt-relevant local features from images, leading to an augmented view of the input image where prompt-relevant content is reserved while irrelevant distractions are masked. With the augmented view, a calibrated decoding distribution can be derived by integrating generative global features from the original image and discriminative local features from the augmented image. Extensive experiments show that AGLA consistently mitigates object hallucinations and enhances general perception capability for LVLMs across various discriminative and generative benchmarks. Our code will be released at https://github.com/Lackel/AGLA.
Generalized Category Discovery with Large Language Models in the Loop
Dec 18, 2023
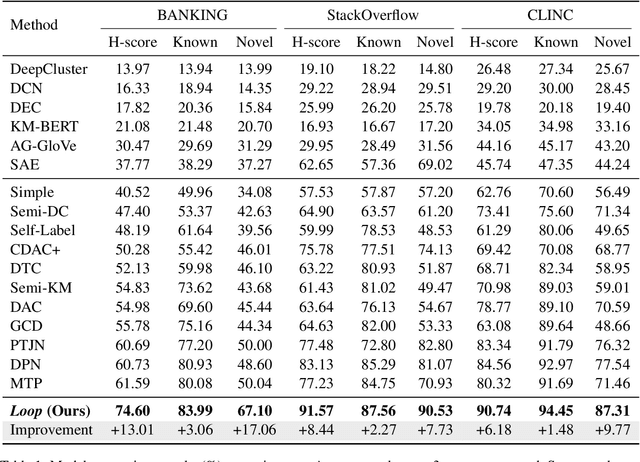

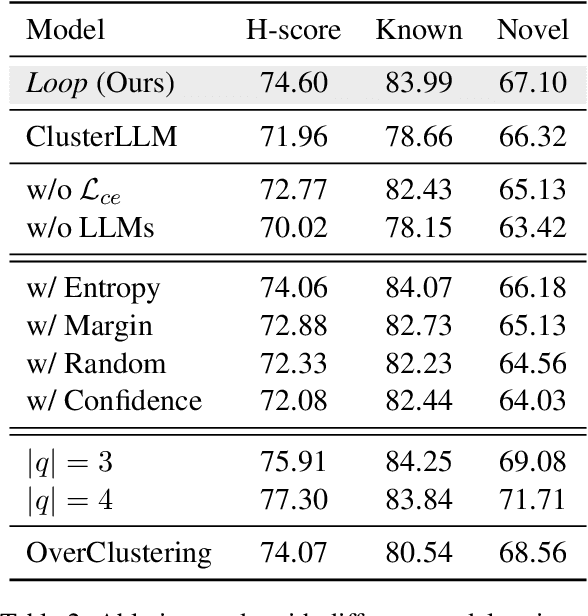
Generalized Category Discovery (GCD) is a crucial task that aims to recognize both known and novel categories from a set of unlabeled data by utilizing a few labeled data with only known categories. Due to the lack of supervision and category information, current methods usually perform poorly on novel categories and struggle to reveal semantic meanings of the discovered clusters, which limits their applications in the real world. To mitigate above issues, we propose Loop, an end-to-end active-learning framework that introduces Large Language Models (LLMs) into the training loop, which can boost model performance and generate category names without relying on any human efforts. Specifically, we first propose Local Inconsistent Sampling (LIS) to select samples that have a higher probability of falling to wrong clusters, based on neighborhood prediction consistency and entropy of cluster assignment probabilities. Then we propose a Scalable Query strategy to allow LLMs to choose true neighbors of the selected samples from multiple candidate samples. Based on the feedback from LLMs, we perform Refined Neighborhood Contrastive Learning (RNCL) to pull samples and their neighbors closer to learn clustering-friendly representations. Finally, we select representative samples from clusters corresponding to novel categories to allow LLMs to generate category names for them. Extensive experiments on three benchmark datasets show that Loop outperforms SOTA models by a large margin and generates accurate category names for the discovered clusters. We will release our code and data after publication.
A Diffusion Weighted Graph Framework for New Intent Discovery
Oct 24, 2023New Intent Discovery (NID) aims to recognize both new and known intents from unlabeled data with the aid of limited labeled data containing only known intents. Without considering structure relationships between samples, previous methods generate noisy supervisory signals which cannot strike a balance between quantity and quality, hindering the formation of new intent clusters and effective transfer of the pre-training knowledge. To mitigate this limitation, we propose a novel Diffusion Weighted Graph Framework (DWGF) to capture both semantic similarities and structure relationships inherent in data, enabling more sufficient and reliable supervisory signals. Specifically, for each sample, we diffuse neighborhood relationships along semantic paths guided by the nearest neighbors for multiple hops to characterize its local structure discriminately. Then, we sample its positive keys and weigh them based on semantic similarities and local structures for contrastive learning. During inference, we further propose Graph Smoothing Filter (GSF) to explicitly utilize the structure relationships to filter high-frequency noise embodied in semantically ambiguous samples on the cluster boundary. Extensive experiments show that our method outperforms state-of-the-art models on all evaluation metrics across multiple benchmark datasets. Code and data are available at https://github.com/yibai-shi/DWGF.
DNA: Denoised Neighborhood Aggregation for Fine-grained Category Discovery
Oct 16, 2023Discovering fine-grained categories from coarsely labeled data is a practical and challenging task, which can bridge the gap between the demand for fine-grained analysis and the high annotation cost. Previous works mainly focus on instance-level discrimination to learn low-level features, but ignore semantic similarities between data, which may prevent these models learning compact cluster representations. In this paper, we propose Denoised Neighborhood Aggregation (DNA), a self-supervised framework that encodes semantic structures of data into the embedding space. Specifically, we retrieve k-nearest neighbors of a query as its positive keys to capture semantic similarities between data and then aggregate information from the neighbors to learn compact cluster representations, which can make fine-grained categories more separatable. However, the retrieved neighbors can be noisy and contain many false-positive keys, which can degrade the quality of learned embeddings. To cope with this challenge, we propose three principles to filter out these false neighbors for better representation learning. Furthermore, we theoretically justify that the learning objective of our framework is equivalent to a clustering loss, which can capture semantic similarities between data to form compact fine-grained clusters. Extensive experiments on three benchmark datasets show that our method can retrieve more accurate neighbors (21.31% accuracy improvement) and outperform state-of-the-art models by a large margin (average 9.96% improvement on three metrics). Our code and data are available at https://github.com/Lackel/DNA.
Generalized Category Discovery with Decoupled Prototypical Network
Nov 28, 2022Generalized Category Discovery (GCD) aims to recognize both known and novel categories from a set of unlabeled data, based on another dataset labeled with only known categories. Without considering differences between known and novel categories, current methods learn about them in a coupled manner, which can hurt model's generalization and discriminative ability. Furthermore, the coupled training approach prevents these models transferring category-specific knowledge explicitly from labeled data to unlabeled data, which can lose high-level semantic information and impair model performance. To mitigate above limitations, we present a novel model called Decoupled Prototypical Network (DPN). By formulating a bipartite matching problem for category prototypes, DPN can not only decouple known and novel categories to achieve different training targets effectively, but also align known categories in labeled and unlabeled data to transfer category-specific knowledge explicitly and capture high-level semantics. Furthermore, DPN can learn more discriminative features for both known and novel categories through our proposed Semantic-aware Prototypical Learning (SPL). Besides capturing meaningful semantic information, SPL can also alleviate the noise of hard pseudo labels through semantic-weighted soft assignment. Extensive experiments show that DPN outperforms state-of-the-art models by a large margin on all evaluation metrics across multiple benchmark datasets. Code and data are available at https://github.com/Lackel/DPN.
Fine-grained Category Discovery under Coarse-grained supervision with Hierarchical Weighted Self-contrastive Learning
Oct 14, 2022


Novel category discovery aims at adapting models trained on known categories to novel categories. Previous works only focus on the scenario where known and novel categories are of the same granularity. In this paper, we investigate a new practical scenario called Fine-grained Category Discovery under Coarse-grained supervision (FCDC). FCDC aims at discovering fine-grained categories with only coarse-grained labeled data, which can adapt models to categories of different granularity from known ones and reduce significant labeling cost. It is also a challenging task since supervised training on coarse-grained categories tends to focus on inter-class distance (distance between coarse-grained classes) but ignore intra-class distance (distance between fine-grained sub-classes) which is essential for separating fine-grained categories. Considering most current methods cannot transfer knowledge from coarse-grained level to fine-grained level, we propose a hierarchical weighted self-contrastive network by building a novel weighted self-contrastive module and combining it with supervised learning in a hierarchical manner. Extensive experiments on public datasets show both effectiveness and efficiency of our model over compared methods. Code and data are available at https://github.com/Lackel/Hierarchical_Weighted_SCL.