 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Multimodal Explainable Artificial Intelligence: Past, Present and Future
Dec 18, 2024



Artificial intelligence (AI) has rapidly developed through advancements in computational power and the growth of massive datasets. However, this progress has also heightened challenges in interpreting the "black-box" nature of AI models. To address these concerns, eXplainable AI (XAI) has emerged with a focus on transparency and interpretability to enhance human understanding and trust in AI decision-making processes. In the context of multimodal data fusion and complex reasoning scenarios, the proposal of Multimodal eXplainable AI (MXAI) integrates multiple modalities for prediction and explanation tasks. Meanwhile, the advent of Large Language Models (LLMs) has led to remarkable breakthroughs in natural language processing, yet their complexity has further exacerbated the issue of MXAI. To gain key insights into the development of MXAI methods and provide crucial guidance for building more transparent, fair, and trustworthy AI systems, we review the MXAI methods from a historical perspective and categorize them across four eras: traditional machine learning, deep learning, discriminative foundation models, and generative LLMs. We also review evaluation metrics and datasets used in MXAI research, concluding with a discussion of future challenges and directions. A project related to this review has been created at https://github.com/ShilinSun/mxai_review.
Unleashing the Potential of Model Bias for Generalized Category Discovery
Dec 17, 2024



Generalized Category Discovery is a significant and complex task that aims to identify both known and undefined novel categories from a set of unlabeled data, leveraging another labeled dataset containing only known categories. The primary challenges stem from model bias induced by pre-training on only known categories and the lack of precise supervision for novel ones, leading to category bias towards known categories and category confusion among different novel categories, which hinders models' ability to identify novel categories effectively. To address these challenges, we propose a novel framework named Self-Debiasing Calibration (SDC). Unlike prior methods that regard model bias towards known categories as an obstacle to novel category identification, SDC provides a novel insight into unleashing the potential of the bias to facilitate novel category learning. Specifically, the output of the biased model serves two key purposes. First, it provides an accurate modeling of category bias, which can be utilized to measure the degree of bias and debias the output of the current training model. Second, it offers valuable insights for distinguishing different novel categories by transferring knowledge between similar categories. Based on these insights, SDC dynamically adjusts the output logits of the current training model using the output of the biased model. This approach produces less biased logits to effectively address the issue of category bias towards known categories, and generates more accurate pseudo labels for unlabeled data, thereby mitigating category confusion for novel categories. Experiments on three benchmark datasets show that SDC outperforms SOTA methods, especially in the identification of novel categories. Our code and data are available at \url{https://github.com/Lackel/SDC}.
Schedule Your Edit: A Simple yet Effective Diffusion Noise Schedule for Image Editing
Oct 24, 2024



Text-guided diffusion models have significantly advanced image editing, enabling high-quality and diverse modifications driven by text prompts. However, effective editing requires inverting the source image into a latent space, a process often hindered by prediction errors inherent in DDIM inversion. These errors accumulate during the diffusion process, resulting in inferior content preservation and edit fidelity, especially with conditional inputs. We address these challenges by investigating the primary contributors to error accumulation in DDIM inversion and identify the singularity problem in traditional noise schedules as a key issue. To resolve this, we introduce the Logistic Schedule, a novel noise schedule designed to eliminate singularities, improve inversion stability, and provide a better noise space for image editing. This schedule reduces noise prediction errors, enabling more faithful editing that preserves the original content of the source image. Our approach requires no additional retraining and is compatible with various existing editing methods. Experiments across eight editing tasks demonstrate the Logistic Schedule's superior performance in content preservation and edit fidelity compared to traditional noise schedules, highlighting its adaptability and effectiveness.
Flipped Classroom: Aligning Teacher Attention with Student in Generalized Category Discovery
Sep 29, 2024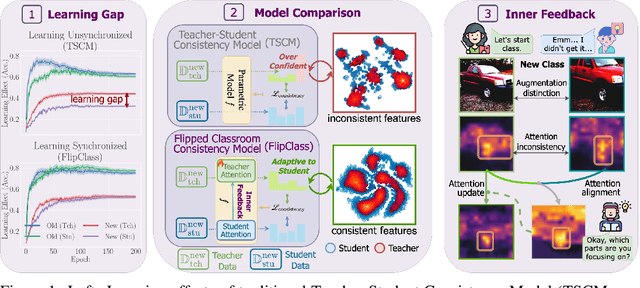
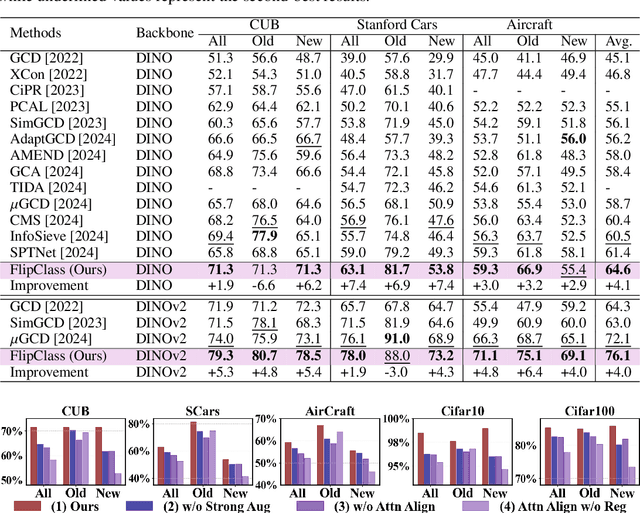


Recent advancements have shown promise in applying traditional Semi-Supervised Learning strategies to the task of Generalized Category Discovery (GCD). Typically, this involves a teacher-student framework in which the teacher imparts knowledge to the student to classify categories, even in the absence of explicit labels. Nevertheless, GCD presents unique challenges, particularly the absence of priors for new classes, which can lead to the teacher's misguidance and unsynchronized learning with the student, culminating in suboptimal outcomes. In our work, we delve into why traditional teacher-student designs falter in open-world generalized category discovery as compared to their success in closed-world semi-supervised learning. We identify inconsistent pattern learning across attention layers as the crux of this issue and introduce FlipClass, a method that dynamically updates the teacher to align with the student's attention, instead of maintaining a static teacher reference. Our teacher-student attention alignment strategy refines the teacher's focus based on student feedback from an energy perspective, promoting consistent pattern recognition and synchronized learning across old and new classes. Extensive experiments on a spectrum of benchmarks affirm that FlipClass significantly surpasses contemporary GCD methods, establishing new standards for the field.
Knowledge Acquisition Disentanglement for Knowledge-based Visual Question Answering with Large Language Models
Jul 22, 2024



Knowledge-based Visual Question Answering (KVQA) requires both image and world knowledge to answer questions. Current methods first retrieve knowledge from the image and external knowledge base with the original complex question, then generate answers with Large Language Models (LLMs). However, since the original question contains complex elements that require knowledge from different sources, acquiring different kinds of knowledge in a coupled manner may confuse models and hinder them from retrieving precise knowledge. Furthermore, the ``forward-only'' answering process fails to explicitly capture the knowledge needs of LLMs, which can further hurt answering quality. To cope with the above limitations, we propose DKA: Disentangled Knowledge Acquisition from LLM feedback, a training-free framework that disentangles knowledge acquisition to avoid confusion and uses LLM's feedback to specify the required knowledge. Specifically, DKA requires LLMs to specify what knowledge they need to answer the question and decompose the original complex question into two simple sub-questions: Image-based sub-question and Knowledge-based sub-question. Then we use the two sub-questions to retrieve knowledge from the image and knowledge base, respectively. In this way, two knowledge acquisition models can focus on the content that corresponds to them and avoid disturbance of irrelevant elements in the original complex question, which can help to provide more precise knowledge and better align the knowledge needs of LLMs to yield correct answers. Experiments on benchmark datasets show that DKA significantly outperforms SOTA models. To facilitate future research, our data and code are available at \url{https://github.com/Lackel/DKA}.
AGLA: Mitigating Object Hallucinations in Large Vision-Language Models with Assembly of Global and Local Attention
Jun 18, 2024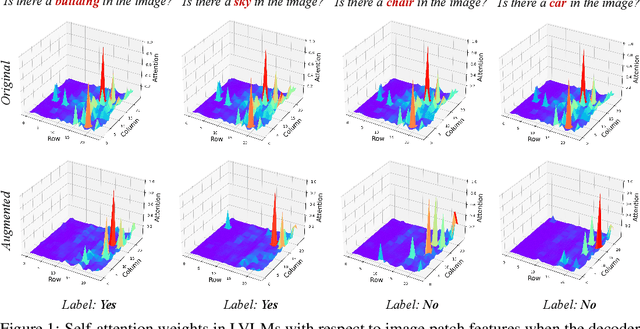
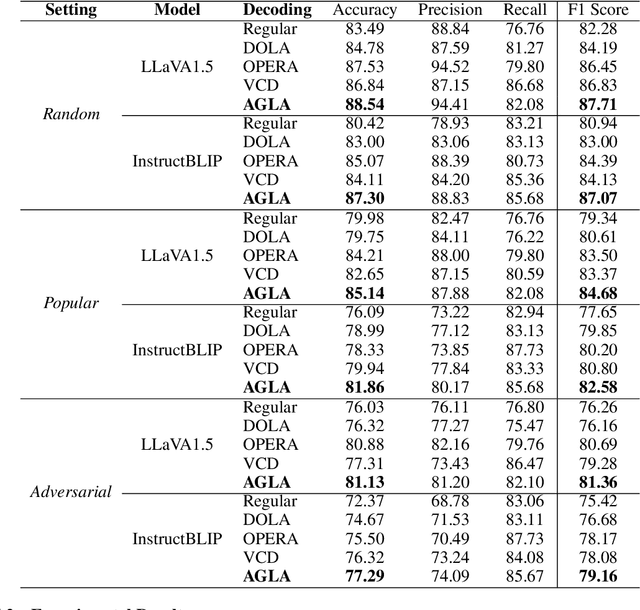
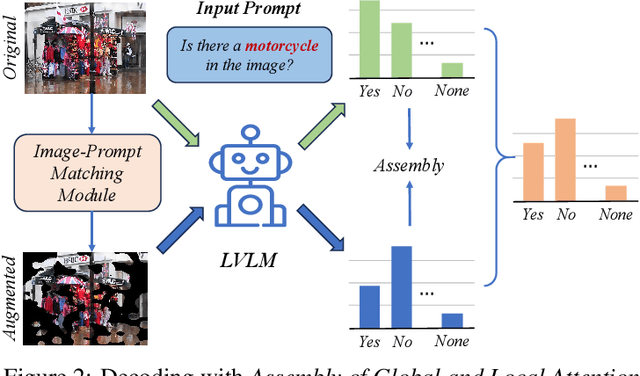
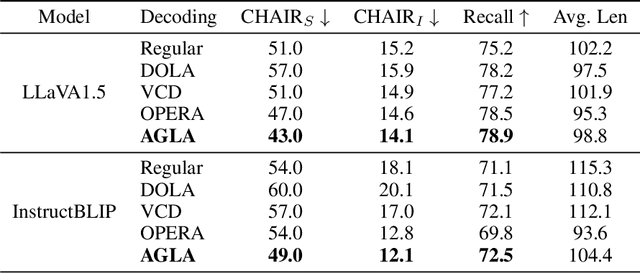
Despite their great success across various multimodal tasks, Large Vision-Language Models (LVLMs) are facing a prevalent problem with object hallucinations, where the generated textual responses are inconsistent with ground-truth objects in the given image. This paper investigates various LVLMs and pinpoints attention deficiency toward discriminative local image features as one root cause of object hallucinations. Specifically, LVLMs predominantly attend to prompt-independent global image features, while failing to capture prompt-relevant local features, consequently undermining the visual grounding capacity of LVLMs and leading to hallucinations. To this end, we propose Assembly of Global and Local Attention (AGLA), a training-free and plug-and-play approach that mitigates object hallucinations by exploring an ensemble of global features for response generation and local features for visual discrimination simultaneously. Our approach exhibits an image-prompt matching scheme that captures prompt-relevant local features from images, leading to an augmented view of the input image where prompt-relevant content is reserved while irrelevant distractions are masked. With the augmented view, a calibrated decoding distribution can be derived by integrating generative global features from the original image and discriminative local features from the augmented image. Extensive experiments show that AGLA consistently mitigates object hallucinations and enhances general perception capability for LVLMs across various discriminative and generative benchmarks. Our code will be released at https://github.com/Lackel/AGLA.
MMRel: A Relation Understanding Dataset and Benchmark in the MLLM Era
Jun 13, 2024



Despite the recent advancements in Multi-modal Large Language Models (MLLMs), understanding inter-object relations, i.e., interactions or associations between distinct objects, remains a major challenge for such models. This issue significantly hinders their advanced reasoning capabilities and is primarily due to the lack of large-scale, high-quality, and diverse multi-modal data essential for training and evaluating MLLMs. In this paper, we provide a taxonomy of inter-object relations and introduce Multi-Modal Relation Understanding (MMRel), a comprehensive dataset designed to bridge this gap by providing large-scale, high-quality and diverse data for studying inter-object relations with MLLMs. MMRel features three distinctive attributes: (i) It includes over 15K question-answer pairs, which are sourced from three distinct domains, ensuring large scale and high diversity; (ii) It contains a subset featuring highly unusual relations, on which MLLMs often fail due to hallucinations, thus are very challenging; (iii) It provides manually verified high-quality labels for inter-object relations. Thanks to these features, MMRel is ideal for evaluating MLLMs on relation understanding, as well as being used to fine-tune MLLMs to enhance relation understanding and even benefit overall performance in various vision-language tasks. Extensive experiments on various popular MLLMs validate the effectiveness of MMRel. Both MMRel dataset and the complete labeling scripts have been made publicly available.
DreamSalon: A Staged Diffusion Framework for Preserving Identity-Context in Editable Face Generation
Mar 28, 2024While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centered images, novel challenges arise with a nuanced task of "identity fine editing": precisely modifying specific features of a subject while maintaining its inherent identity and context. Existing personalization methods either require time-consuming optimization or learning additional encoders, adept in "identity re-contextualization". However, they often struggle with detailed and sensitive tasks like human face editing. To address these challenges, we introduce DreamSalon, a noise-guided, staged-editing framework, uniquely focusing on detailed image manipulations and identity-context preservation. By discerning editing and boosting stages via the frequency and gradient of predicted noises, DreamSalon first performs detailed manipulations on specific features in the editing stage, guided by high-frequency information, and then employs stochastic denoising in the boosting stage to improve image quality. For more precise editing, DreamSalon semantically mixes source and target textual prompts, guided by differences in their embedding covariances, to direct the model's focus on specific manipulation areas. Our experiments demonstrate DreamSalon's ability to efficiently and faithfully edit fine details on human faces, outperforming existing methods both qualitatively and quantitatively.
Transfer and Alignment Network for Generalized Category Discovery
Dec 27, 2023



Generalized Category Discovery is a crucial real-world task. Despite the improved performance on known categories, current methods perform poorly on novel categories. We attribute the poor performance to two reasons: biased knowledge transfer between labeled and unlabeled data and noisy representation learning on the unlabeled data. To mitigate these two issues, we propose a Transfer and Alignment Network (TAN), which incorporates two knowledge transfer mechanisms to calibrate the biased knowledge and two feature alignment mechanisms to learn discriminative features. Specifically, we model different categories with prototypes and transfer the prototypes in labeled data to correct model bias towards known categories. On the one hand, we pull instances with known categories in unlabeled data closer to these prototypes to form more compact clusters and avoid boundary overlap between known and novel categories. On the other hand, we use these prototypes to calibrate noisy prototypes estimated from unlabeled data based on category similarities, which allows for more accurate estimation of prototypes for novel categories that can be used as reliable learning targets later. After knowledge transfer, we further propose two feature alignment mechanisms to acquire both instance- and category-level knowledge from unlabeled data by aligning instance features with both augmented features and the calibrated prototypes, which can boost model performance on both known and novel categories with less noise. Experiments on three benchmark datasets show that our model outperforms SOTA methods, especially on novel categories. Theoretical analysis is provided for an in-depth understanding of our model in general. Our code and data are available at https://github.com/Lackel/TAN.
Generalized Category Discovery with Large Language Models in the Loop
Dec 18, 2023
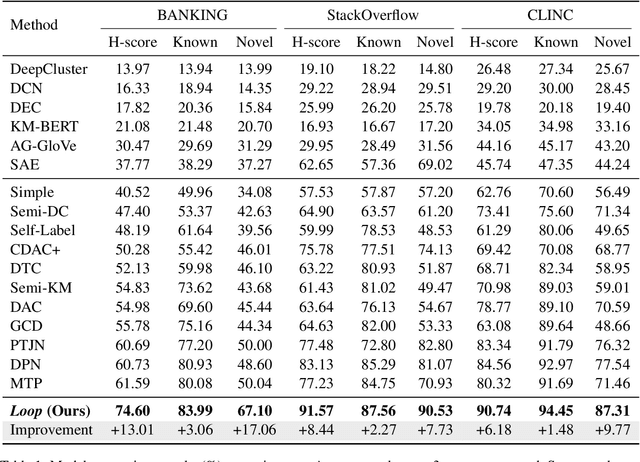

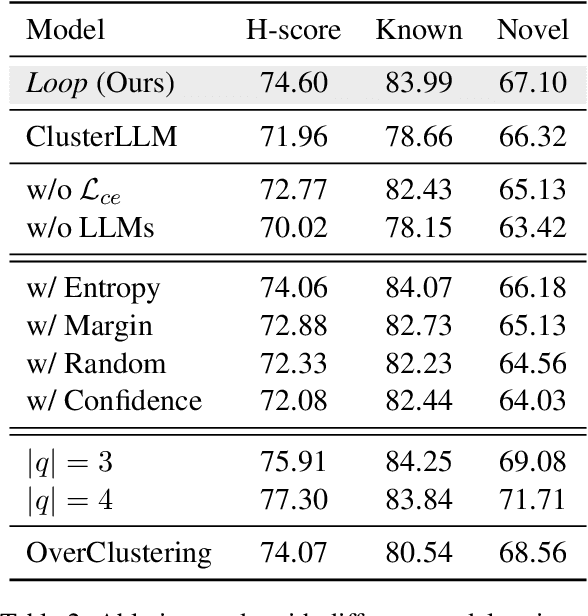
Generalized Category Discovery (GCD) is a crucial task that aims to recognize both known and novel categories from a set of unlabeled data by utilizing a few labeled data with only known categories. Due to the lack of supervision and category information, current methods usually perform poorly on novel categories and struggle to reveal semantic meanings of the discovered clusters, which limits their applications in the real world. To mitigate above issues, we propose Loop, an end-to-end active-learning framework that introduces Large Language Models (LLMs) into the training loop, which can boost model performance and generate category names without relying on any human efforts. Specifically, we first propose Local Inconsistent Sampling (LIS) to select samples that have a higher probability of falling to wrong clusters, based on neighborhood prediction consistency and entropy of cluster assignment probabilities. Then we propose a Scalable Query strategy to allow LLMs to choose true neighbors of the selected samples from multiple candidate samples. Based on the feedback from LLMs, we perform Refined Neighborhood Contrastive Learning (RNCL) to pull samples and their neighbors closer to learn clustering-friendly representations. Finally, we select representative samples from clusters corresponding to novel categories to allow LLMs to generate category names for them. Extensive experiments on three benchmark datasets show that Loop outperforms SOTA models by a large margin and generates accurate category names for the discovered clusters. We will release our code and data after publication.