 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonizing Semantic and Collaborative in LLMs: Reasoning-based Embedding Generator for Sequential Recommendation
Jun 15, 2026Sequential Recommender Systems (SRS) predict the next item of interest based on users' interaction histories and have been widely deployed, but hindered by long-tail problem. Large Language Models (LLMs), with strong semantic understanding and reasoning capabilities, offer a promising way to enrich item semantics and have recently been used as embedding generators. However, two fundamental gaps remain. First, current LLM-based embedding methods fail to exploit the model's inner reasoning capacity. Second, existing methods often inject collaborative signals implicitly via supervised fine-tuning, lacking explicit guidance for collaborative embedding alignment. In this paper, we introduce ReaEmb, a novel framework that resolves both issues via a Latent Reasoning-enhanced Contrastive Learning (LRCL) stage and a Collaborative Reward Reinforcement Learning (CRRL) stage. LRCL exploits the LLMs' inner reasoning capacity through a two-pass forward process with an additional attention module. CRRL subsequently explicitly injects collaborative signals into the LLM via a tailored reinforcement learning. Extensive experiments on three real-world datasets demonstrate superior effectiveness of ReaEmb across multiple SRS models. To ease reproducibility, we release the code online.
Exploring Knowledge Conflicts for Faithful LLM Reasoning: Benchmark and Method
Apr 13, 2026Large language models (LLMs) have achieved remarkable success across a wide range of applications especially when augmented by external knowledge through retrieval-augmented generation (RAG). Despite their widespread adoption, recent studies have shown that LLMs often struggle to perform faithful reasoning when conflicting knowledge is retrieved. However, existing work primarily focuses on conflicts between external knowledge and the parametric knowledge of LLMs, leaving conflicts across external knowledge largely unexplored. Meanwhile, modern RAG systems increasingly emphasize the integration of unstructured text and (semi-)structured data like knowledge graphs (KGs) to improve knowledge completeness and reasoning faithfulness. To address this gap, we introduce ConflictQA, a novel benchmark that systematically instantiates conflicts between textual evidence and KG evidence. Extensive evaluations across representative LLMs reveal that, facing such cross-source conflicts, LLMs often fail to identify reliable evidence for correct reasoning. Instead, LLMs become more sensitive to prompting choices and tend to rely exclusively on either KG or textual evidence, resulting in incorrect responses. Based on these findings, we further propose XoT, a two-stage explanation-based thinking framework tailored for reasoning over heterogeneous conflicting evidence, and verify its effectiveness with extensive experiments.
DMESR: Dual-view MLLM-based Enhancing Framework for Multimodal Sequential Recommendation
Feb 14, 2026Sequential Recommender Systems (SRS) aim to predict users' next interaction based on their historical behaviors, while still facing the challenge of data sparsity. With the rapid advancement of Multimodal Large Language Models (MLLMs), leveraging their multimodal understanding capabilities to enrich item semantic representation has emerged as an effective enhancement strategy for SRS. However, existing MLLM-enhanced recommendation methods still suffer from two key limitations. First, they struggle to effectively align multimodal representations, leading to suboptimal utilization of semantic information across modalities. Second, they often overly rely on MLLM-generated content while overlooking the fine-grained semantic cues contained in the original textual data of items. To address these issues, we propose a Dual-view MLLM-based Enhancing framework for multimodal Sequential Recommendation (DMESR). For the misalignment issue, we employ a contrastive learning mechanism to align the cross-modal semantic representations generated by MLLMs. For the loss of fine-grained semantics, we introduce a cross-attention fusion module that integrates the coarse-grained semantic knowledge obtained from MLLMs with the fine-grained original textual semantics. Finally, these two fused representations can be seamlessly integrated into the downstream sequential recommendation models. Extensive experiments conducted on three real-world datasets and three popular sequential recommendation architectures demonstrate the superior effectiveness and generalizability of our proposed approach.
Towards Efficient and Robust Linguistic Emotion Diagnosis for Mental Health via Multi-Agent Instruction Refinement
Jan 20, 2026Linguistic expressions of emotions such as depression, anxiety, and trauma-related states are pervasive in clinical notes, counseling dialogues, and online mental health communities, and accurate recognition of these emotions is essential for clinical triage, risk assessment, and timely intervention. Although large language models (LLMs) have demonstrated strong generalization ability in emotion analysis tasks, their diagnostic reliability in high-stakes, context-intensive medical settings remains highly sensitive to prompt design. Moreover, existing methods face two key challenges: emotional comorbidity, in which multiple intertwined emotional states complicate prediction, and inefficient exploration of clinically relevant cues. To address these challenges, we propose APOLO (Automated Prompt Optimization for Linguistic Emotion Diagnosis), a framework that systematically explores a broader and finer-grained prompt space to improve diagnostic efficiency and robustness. APOLO formulates instruction refinement as a Partially Observable Markov Decision Process and adopts a multi-agent collaboration mechanism involving Planner, Teacher, Critic, Student, and Target roles. Within this closed-loop framework, the Planner defines an optimization trajectory, while the Teacher-Critic-Student agents iteratively refine prompts to enhance reasoning stability and effectiveness, and the Target agent determines whether to continue optimization based on performance evaluation. Experimental results show that APOLO consistently improves diagnostic accuracy and robustness across domain-specific and stratified benchmarks, demonstrating a scalable and generalizable paradigm for trustworthy LLM applications in mental healthcare.
LLMSeR: Enhancing Sequential Recommendation via LLM-based Data Augmentation
Mar 16, 2025Sequential Recommender Systems (SRS) have become a cornerstone of online platforms, leveraging users' historical interaction data to forecast their next potential engagement. Despite their widespread adoption, SRS often grapple with the long-tail user dilemma, resulting in less effective recommendations for individuals with limited interaction records. The advent of Large Language Models (LLMs), with their profound capability to discern semantic relationships among items, has opened new avenues for enhancing SRS through data augmentation. Nonetheless, current methodologies encounter obstacles, including the absence of collaborative signals and the prevalence of hallucination phenomena.In this work, we present LLMSeR, an innovative framework that utilizes Large Language Models (LLMs) to generate pseudo-prior items, thereby improving the efficacy of Sequential Recommender Systems (SRS). To alleviate the challenge of insufficient collaborative signals, we introduce the Semantic Interaction Augmentor (SIA), a method that integrates both semantic and collaborative information to comprehensively augment user interaction data. Moreover, to weaken the adverse effects of hallucination in SRS, we develop the Adaptive Reliability Validation (ARV), a validation technique designed to assess the reliability of the generated pseudo items. Complementing these advancements, we also devise a Dual-Channel Training strategy, ensuring seamless integration of data augmentation into the SRS training process.Extensive experiments conducted with three widely-used SRS models demonstrate the generalizability and efficacy of LLMSeR.
A Semantic Mention Graph Augmented Model for Document-Level Event Argument Extraction
Mar 12, 2024



Document-level Event Argument Extraction (DEAE) aims to identify arguments and their specific roles from an unstructured document. The advanced approaches on DEAE utilize prompt-based methods to guide pre-trained language models (PLMs) in extracting arguments from input documents. They mainly concentrate on establishing relations between triggers and entity mentions within documents, leaving two unresolved problems: a) independent modeling of entity mentions; b) document-prompt isolation. To this end, we propose a semantic mention Graph Augmented Model (GAM) to address these two problems in this paper. Firstly, GAM constructs a semantic mention graph that captures relations within and between documents and prompts, encompassing co-existence, co-reference and co-type relations. Furthermore, we introduce an ensembled graph transformer module to address mentions and their three semantic relations effectively. Later, the graph-augmented encoder-decoder module incorporates the relation-specific graph into the input embedding of PLMs and optimizes the encoder section with topology information, enhancing the relations comprehensively. Extensive experiments on the RAMS and WikiEvents datasets demonstrate the effectiveness of our approach, surpassing baseline methods and achieving a new state-of-the-art performance.
Generalized Category Discovery with Large Language Models in the Loop
Dec 18, 2023
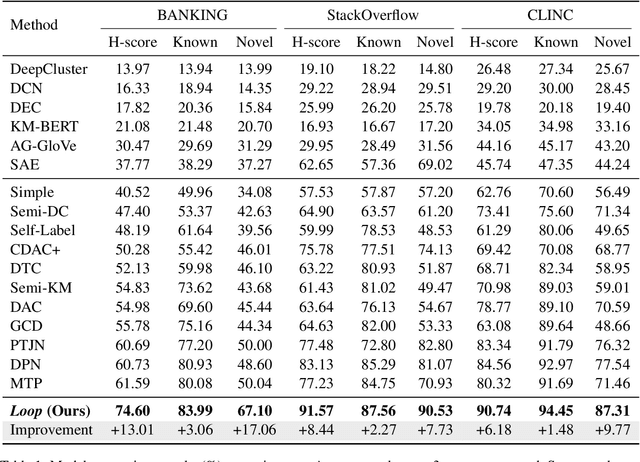

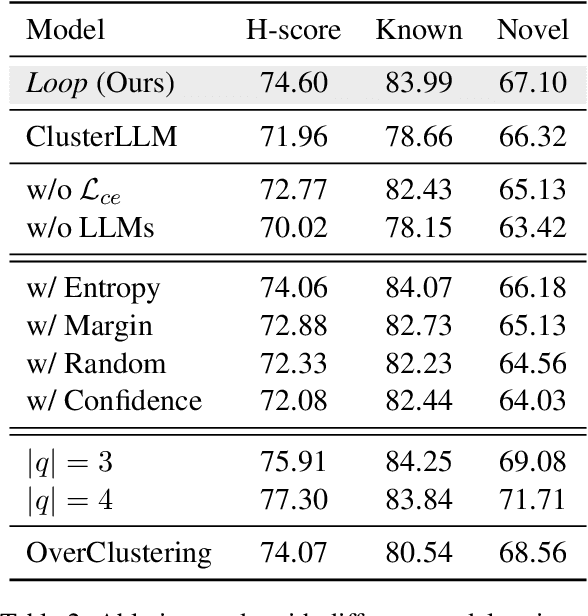
Generalized Category Discovery (GCD) is a crucial task that aims to recognize both known and novel categories from a set of unlabeled data by utilizing a few labeled data with only known categories. Due to the lack of supervision and category information, current methods usually perform poorly on novel categories and struggle to reveal semantic meanings of the discovered clusters, which limits their applications in the real world. To mitigate above issues, we propose Loop, an end-to-end active-learning framework that introduces Large Language Models (LLMs) into the training loop, which can boost model performance and generate category names without relying on any human efforts. Specifically, we first propose Local Inconsistent Sampling (LIS) to select samples that have a higher probability of falling to wrong clusters, based on neighborhood prediction consistency and entropy of cluster assignment probabilities. Then we propose a Scalable Query strategy to allow LLMs to choose true neighbors of the selected samples from multiple candidate samples. Based on the feedback from LLMs, we perform Refined Neighborhood Contrastive Learning (RNCL) to pull samples and their neighbors closer to learn clustering-friendly representations. Finally, we select representative samples from clusters corresponding to novel categories to allow LLMs to generate category names for them. Extensive experiments on three benchmark datasets show that Loop outperforms SOTA models by a large margin and generates accurate category names for the discovered clusters. We will release our code and data after publication.
Meta Ordinal Regression Forest for Medical Image Classification with Ordinal Labels
Mar 15, 2022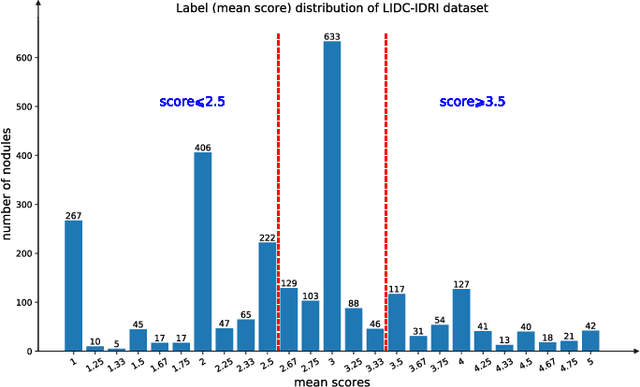
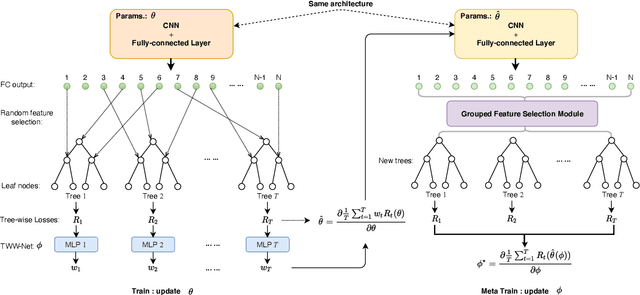
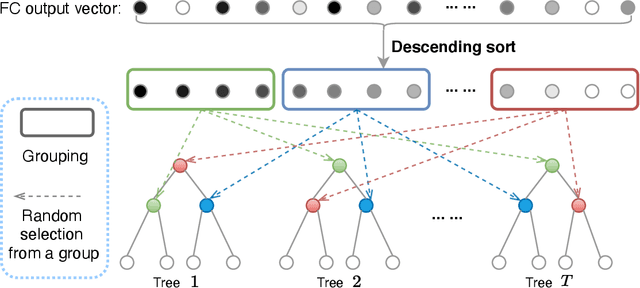
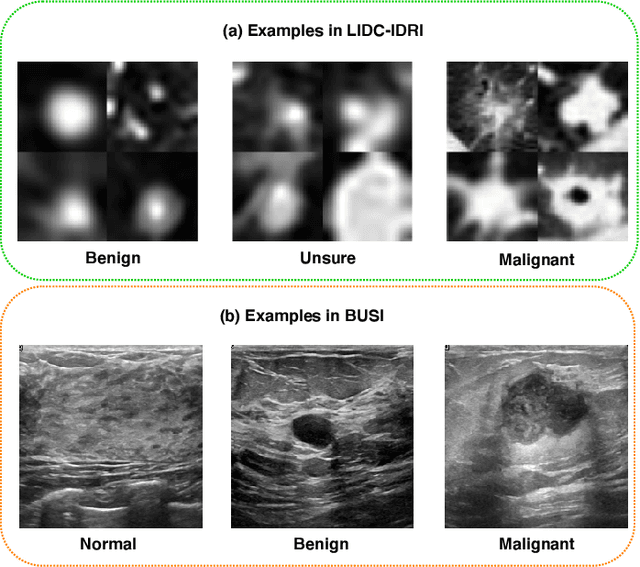
The performance of medical image classification has been enhanced by deep convolutional neural networks (CNNs), which are typically trained with cross-entropy (CE) loss. However, when the label presents an intrinsic ordinal property in nature, e.g., the development from benign to malignant tumor, CE loss cannot take into account such ordinal information to allow for better generalization. To improve model generalization with ordinal information, we propose a novel meta ordinal regression forest (MORF) method for medical image classification with ordinal labels, which learns the ordinal relationship through the combination of convolutional neural network and differential forest in a meta-learning framework. The merits of the proposed MORF come from the following two components: a tree-wise weighting net (TWW-Net) and a grouped feature selection (GFS) module. First, the TWW-Net assigns each tree in the forest with a specific weight that is mapped from the classification loss of the corresponding tree. Hence, all the trees possess varying weights, which is helpful for alleviating the tree-wise prediction variance. Second, the GFS module enables a dynamic forest rather than a fixed one that was previously used, allowing for random feature perturbation. During training, we alternatively optimize the parameters of the CNN backbone and TWW-Net in the meta-learning framework through calculating the Hessian matrix. Experimental results on two medical image classification datasets with ordinal labels, i.e., LIDC-IDRI and Breast Ultrasound Dataset, demonstrate the superior performances of our MORF method over existing state-of-the-art methods.
Meta Ordinal Regression Forest For Learning with Unsure Lung Nodules
Dec 07, 2020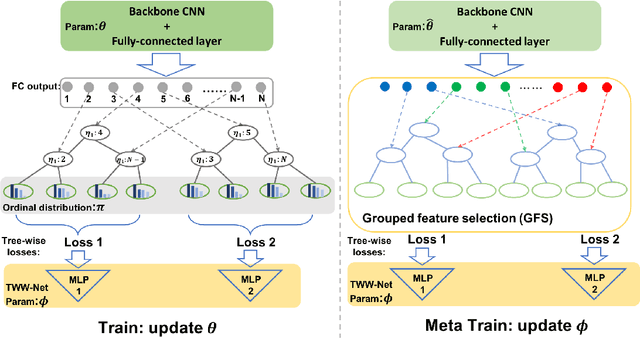

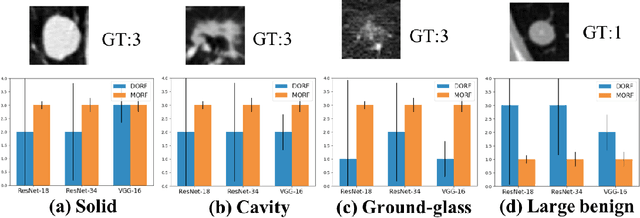
Deep learning-based methods have achieved promising performance in early detection and classification of lung nodules, most of which discard unsure nodules and simply deal with a binary classification -- malignant vs benign. Recently, an unsure data model (UDM) was proposed to incorporate those unsure nodules by formulating this problem as an ordinal regression, showing better performance over traditional binary classification. To further explore the ordinal relationship for lung nodule classification, this paper proposes a meta ordinal regression forest (MORF), which improves upon the state-of-the-art ordinal regression method, deep ordinal regression forest (DORF), in three major ways. First, MORF can alleviate the biases of the predictions by making full use of deep features while DORF needs to fix the composition of decision trees before training. Second, MORF has a novel grouped feature selection (GFS) module to re-sample the split nodes of decision trees. Last, combined with GFS, MORF is equipped with a meta learning-based weighting scheme to map the features selected by GFS to tree-wise weights while DORF assigns equal weights for all trees. Experimental results on the LIDC-IDRI dataset demonstrate superior performance over existing methods, including the state-of-the-art DORF.
Deep Ordinal Regression Forests
Aug 07, 2020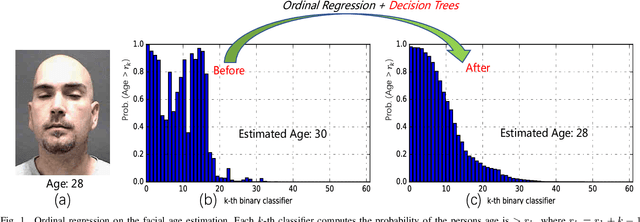
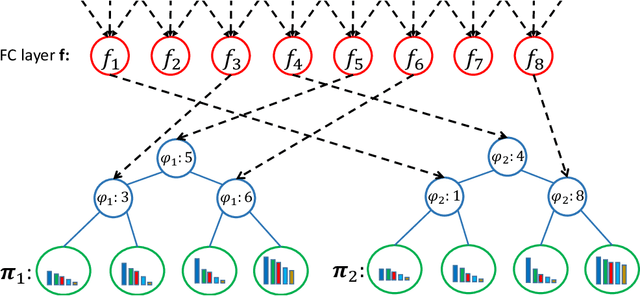


Ordinal regression is a type of regression techniques used for predicting an ordinal variable. Recent methods formulate an ordinal regression problem as a series of binary classification problems. Such methods cannot ensure the global ordinal relationship is preserved since the relationships among different binary classifiers are neglected. We propose a novel ordinal regression approach called Deep Ordinal Regression Forests (DORFs), which is constructed with the differentiable decision trees for obtaining precise and stable global ordinal relationships. The advantages of the proposed DORFs are twofold. First, instead of learning a series of binary classifiers independently, the proposed method learns an ordinal distribution for ordinal regression. Second, the differentiable decision trees can be trained together with the ordinal distribution in an end-to-end manner. The effectiveness of the proposed DORFs is verified on two ordinal regression tasks, i.e., facial age estimation and image aesthetic assessment, showing significant improvements and better stability over the state-of-the-art ordinal regression methods.