 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading a Ruler in the Wild
Jul 09, 2025Accurately converting pixel measurements into absolute real-world dimensions remains a fundamental challenge in computer vision and limits progress in key applications such as biomedicine, forensics, nutritional analysis, and e-commerce. We introduce RulerNet, a deep learning framework that robustly infers scale "in the wild" by reformulating ruler reading as a unified keypoint-detection problem and by representing the ruler with geometric-progression parameters that are invariant to perspective transformations. Unlike traditional methods that rely on handcrafted thresholds or rigid, ruler-specific pipelines, RulerNet directly localizes centimeter marks using a distortion-invariant annotation and training strategy, enabling strong generalization across diverse ruler types and imaging conditions while mitigating data scarcity. We also present a scalable synthetic-data pipeline that combines graphics-based ruler generation with ControlNet to add photorealistic context, greatly increasing training diversity and improving performance. To further enhance robustness and efficiency, we propose DeepGP, a lightweight feed-forward network that regresses geometric-progression parameters from noisy marks and eliminates iterative optimization, enabling real-time scale estimation on mobile or edge devices. Experiments show that RulerNet delivers accurate, consistent, and efficient scale estimates under challenging real-world conditions. These results underscore its utility as a generalizable measurement tool and its potential for integration with other vision components for automated, scale-aware analysis in high-impact domains. A live demo is available at https://huggingface.co/spaces/ymp5078/RulerNet-Demo.
Evaluating Vision-Language Models for Emotion Recognition
Feb 08, 2025



Large Vision-Language Models (VLMs) have achieved unprecedented success in several objective multimodal reasoning tasks. However, to further enhance their capabilities of empathetic and effective communication with humans, improving how VLMs process and understand emotions is crucial. Despite significant research attention on improving affective understanding, there is a lack of detailed evaluations of VLMs for emotion-related tasks, which can potentially help inform downstream fine-tuning efforts. In this work, we present the first comprehensive evaluation of VLMs for recognizing evoked emotions from images. We create a benchmark for the task of evoked emotion recognition and study the performance of VLMs for this task, from perspectives of correctness and robustness. Through several experiments, we demonstrate important factors that emotion recognition performance depends on, and also characterize the various errors made by VLMs in the process. Finally, we pinpoint potential causes for errors through a human evaluation study. We use our experimental results to inform recommendations for the future of emotion research in the context of VLMs.
A Heterogeneous Multimodal Graph Learning Framework for Recognizing User Emotions in Social Networks
Jan 13, 2025



The rapid expansion of social media platforms has provided unprecedented access to massive amounts of multimodal user-generated content. Comprehending user emotions can provide valuable insights for improving communication and understanding of human behaviors. Despite significant advancements in Affective Computing, the diverse factors influencing user emotions in social networks remain relatively understudied. Moreover, there is a notable lack of deep learning-based methods for predicting user emotions in social networks, which could be addressed by leveraging the extensive multimodal data available. This work presents a novel formulation of personalized emotion prediction in social networks based on heterogeneous graph learning. Building upon this formulation, we design HMG-Emo, a Heterogeneous Multimodal Graph Learning Framework that utilizes deep learning-based features for user emotion recognition. Additionally, we include a dynamic context fusion module in HMG-Emo that is capable of adaptively integrating the different modalities in social media data. Through extensive experiments, we demonstrate the effectiveness of HMG-Emo and verify the superiority of adopting a graph neural network-based approach, which outperforms existing baselines that use rich hand-crafted features. To the best of our knowledge, HMG-Emo is the first multimodal and deep-learning-based approach to predict personalized emotions within online social networks. Our work highlights the significance of exploiting advanced deep learning techniques for less-explored problems in Affective Computing.
S2S2: Semantic Stacking for Robust Semantic Segmentation in Medical Imaging
Dec 17, 2024



Robustness and generalizability in medical image segmentation are often hindered by scarcity and limited diversity of training data, which stands in contrast to the variability encountered during inference. While conventional strategies -- such as domain-specific augmentation, specialized architectures, and tailored training procedures -- can alleviate these issues, they depend on the availability and reliability of domain knowledge. When such knowledge is unavailable, misleading, or improperly applied, performance may deteriorate. In response, we introduce a novel, domain-agnostic, add-on, and data-driven strategy inspired by image stacking in image denoising. Termed ``semantic stacking,'' our method estimates a denoised semantic representation that complements the conventional segmentation loss during training. This method does not depend on domain-specific assumptions, making it broadly applicable across diverse image modalities, model architectures, and augmentation techniques. Through extensive experiments, we validate the superiority of our approach in improving segmentation performance under diverse conditions. Code is available at https://github.com/ymp5078/Semantic-Stacking.
Context-driven self-supervised visual learning: Harnessing the environment as a data source
Jan 26, 2024



Visual learning often occurs in a specific context, where an agent acquires skills through exploration and tracking of its location in a consistent environment. The historical spatial context of the agent provides a similarity signal for self-supervised contrastive learning. We present a unique approach, termed Environmental Spatial Similarity (ESS), that complements existing contrastive learning methods. Using images from simulated, photorealistic environments as an experimental setting, we demonstrate that ESS outperforms traditional instance discrimination approaches. Moreover, sampling additional data from the same environment substantially improves accuracy and provides new augmentations. ESS allows remarkable proficiency in room classification and spatial prediction tasks, especially in unfamiliar environments. This learning paradigm has the potential to enable rapid visual learning in agents operating in new environments with unique visual characteristics. Potentially transformative applications span from robotics to space exploration. Our proof of concept demonstrates improved efficiency over methods that rely on extensive, disconnected datasets.
AI-SAM: Automatic and Interactive Segment Anything Model
Dec 05, 2023



Semantic segmentation is a core task in computer vision. Existing methods are generally divided into two categories: automatic and interactive. Interactive approaches, exemplified by the Segment Anything Model (SAM), have shown promise as pre-trained models. However, current adaptation strategies for these models tend to lean towards either automatic or interactive approaches. Interactive methods depend on prompts user input to operate, while automatic ones bypass the interactive promptability entirely. Addressing these limitations, we introduce a novel paradigm and its first model: the Automatic and Interactive Segment Anything Model (AI-SAM). In this paradigm, we conduct a comprehensive analysis of prompt quality and introduce the pioneering Automatic and Interactive Prompter (AI-Prompter) that automatically generates initial point prompts while accepting additional user inputs. Our experimental results demonstrate AI-SAM's effectiveness in the automatic setting, achieving state-of-the-art performance. Significantly, it offers the flexibility to incorporate additional user prompts, thereby further enhancing its performance. The project page is available at https://github.com/ymp5078/AI-SAM.
Unlocking the Emotional World of Visual Media: An Overview of the Science, Research, and Impact of Understanding Emotion
Jul 25, 2023



The emergence of artificial emotional intelligence technology is revolutionizing the fields of computers and robotics, allowing for a new level of communication and understanding of human behavior that was once thought impossible. While recent advancements in deep learning have transformed the field of computer vision, automated understanding of evoked or expressed emotions in visual media remains in its infancy. This foundering stems from the absence of a universally accepted definition of "emotion", coupled with the inherently subjective nature of emotions and their intricate nuances. In this article, we provide a comprehensive, multidisciplinary overview of the field of emotion analysis in visual media, drawing on insights from psychology, engineering, and the arts. We begin by exploring the psychological foundations of emotion and the computational principles that underpin the understanding of emotions from images and videos. We then review the latest research and systems within the field, accentuating the most promising approaches. We also discuss the current technological challenges and limitations of emotion analysis, underscoring the necessity for continued investigation and innovation. We contend that this represents a "Holy Grail" research problem in computing and delineate pivotal directions for future inquiry. Finally, we examine the ethical ramifications of emotion-understanding technologies and contemplate their potential societal impacts. Overall, this article endeavors to equip readers with a deeper understanding of the domain of emotion analysis in visual media and to inspire further research and development in this captivating and rapidly evolving field.
Learning Emotion Representations from Verbal and Nonverbal Communication
May 22, 2023



Emotion understanding is an essential but highly challenging component of artificial general intelligence. The absence of extensively annotated datasets has significantly impeded advancements in this field. We present EmotionCLIP, the first pre-training paradigm to extract visual emotion representations from verbal and nonverbal communication using only uncurated data. Compared to numerical labels or descriptions used in previous methods, communication naturally contains emotion information. Furthermore, acquiring emotion representations from communication is more congruent with the human learning process. We guide EmotionCLIP to attend to nonverbal emotion cues through subject-aware context encoding and verbal emotion cues using sentiment-guided contrastive learning. Extensive experiments validate the effectiveness and transferability of EmotionCLIP. Using merely linear-probe evaluation protocol, EmotionCLIP outperforms the state-of-the-art supervised visual emotion recognition methods and rivals many multimodal approaches across various benchmarks. We anticipate that the advent of EmotionCLIP will address the prevailing issue of data scarcity in emotion understanding, thereby fostering progress in related domains. The code and pre-trained models are available at https://github.com/Xeaver/EmotionCLIP.
Bodily expressed emotion understanding through integrating Laban movement analysis
Apr 05, 2023
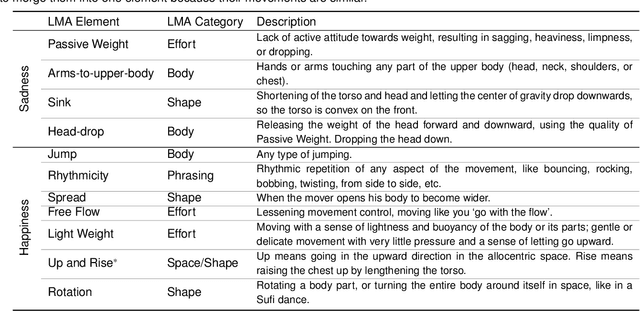
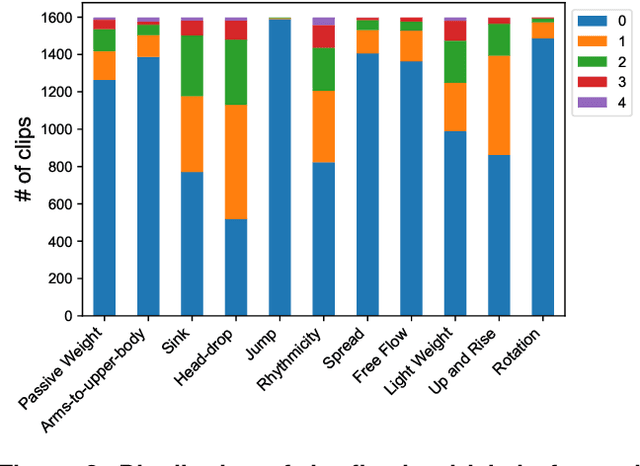
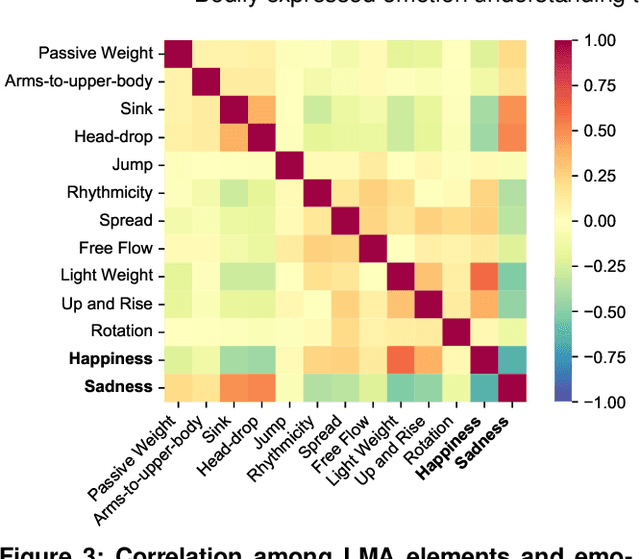
Body movements carry important information about a person's emotions or mental state and are essential in daily communication. Enhancing the ability of machines to understand emotions expressed through body language can improve the communication of assistive robots with children and elderly users, provide psychiatric professionals with quantitative diagnostic and prognostic assistance, and aid law enforcement in identifying deception. This study develops a high-quality human motor element dataset based on the Laban Movement Analysis movement coding system and utilizes that to jointly learn about motor elements and emotions. Our long-term ambition is to integrate knowledge from computing, psychology, and performing arts to enable automated understanding and analysis of emotion and mental state through body language. This work serves as a launchpad for further research into recognizing emotions through analysis of human movement.
Learning to Adapt to Online Streams with Distribution Shifts
Mar 02, 2023



Test-time adaptation (TTA) is a technique used to reduce distribution gaps between the training and testing sets by leveraging unlabeled test data during inference. In this work, we expand TTA to a more practical scenario, where the test data comes in the form of online streams that experience distribution shifts over time. Existing approaches face two challenges: reliance on a large test data batch from the same domain and the absence of explicitly modeling the continual distribution evolution process. To address both challenges, we propose a meta-learning approach that teaches the network to adapt to distribution-shifting online streams during meta-training. As a result, the trained model can perform continual adaptation to distribution shifts in testing, regardless of the batch size restriction, as it has learned during training. We conducted extensive experiments on benchmarking datasets for TTA, incorporating a broad range of online distribution-shifting settings. Our results showed consistent improvements over state-of-the-art methods, indicating the effectiveness of our approach. In addition, we achieved superior performance in the video segmentation task, highlighting the potential of our method for real-world applications.