 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-driven self-supervised visual learning: Harnessing the environment as a data source
Jan 26, 2024



Visual learning often occurs in a specific context, where an agent acquires skills through exploration and tracking of its location in a consistent environment. The historical spatial context of the agent provides a similarity signal for self-supervised contrastive learning. We present a unique approach, termed Environmental Spatial Similarity (ESS), that complements existing contrastive learning methods. Using images from simulated, photorealistic environments as an experimental setting, we demonstrate that ESS outperforms traditional instance discrimination approaches. Moreover, sampling additional data from the same environment substantially improves accuracy and provides new augmentations. ESS allows remarkable proficiency in room classification and spatial prediction tasks, especially in unfamiliar environments. This learning paradigm has the potential to enable rapid visual learning in agents operating in new environments with unique visual characteristics. Potentially transformative applications span from robotics to space exploration. Our proof of concept demonstrates improved efficiency over methods that rely on extensive, disconnected datasets.
Using Navigational Information to Learn Visual Representations
Feb 10, 2022
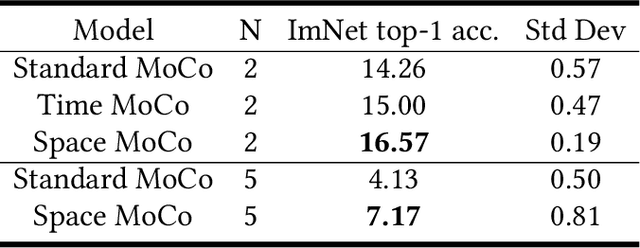
Children learn to build a visual representation of the world from unsupervised exploration and we hypothesize that a key part of this learning ability is the use of self-generated navigational information as a similarity label to drive a learning objective for self-supervised learning. The goal of this work is to exploit navigational information in a visual environment to provide performance in training that exceeds the state-of-the-art self-supervised training. Here, we show that using spatial and temporal information in the pretraining stage of contrastive learning can improve the performance of downstream classification relative to conventional contrastive learning approaches that use instance discrimination to discriminate between two alterations of the same image or two different images. We designed a pipeline to generate egocentric-vision images from a photorealistic ray-tracing environment (ThreeDWorld) and record relevant navigational information for each image. Modifying the Momentum Contrast (MoCo) model, we introduced spatial and temporal information to evaluate the similarity of two views in the pretraining stage instead of instance discrimination. This work reveals the effectiveness and efficiency of contextual information for improving representation learning. The work informs our understanding of the means by which children might learn to see the world without external supervision.