 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Steering Works: Toward a Unified View of Language Model Parameter Dynamics
Feb 02, 2026Methods for controlling large language models (LLMs), including local weight fine-tuning, LoRA-based adaptation, and activation-based interventions, are often studied in isolation, obscuring their connections and making comparison difficult. In this work, we present a unified view that frames these interventions as dynamic weight updates induced by a control signal, placing them within a single conceptual framework. Building on this view, we propose a unified preference-utility analysis that separates control effects into preference, defined as the tendency toward a target concept, and utility, defined as coherent and task-valid generation, and measures both on a shared log-odds scale using polarity-paired contrastive examples. Across methods, we observe a consistent trade-off between preference and utility: stronger control increases preference while predictably reducing utility. We further explain this behavior through an activation manifold perspective, in which control shifts representations along target-concept directions to enhance preference, while utility declines primarily when interventions push representations off the model's valid-generation manifold. Finally, we introduce a new steering approach SPLIT guided by this analysis that improves preference while better preserving utility. Code is available at https://github.com/zjunlp/EasyEdit/blob/main/examples/SPLIT.md.
DuoSpaceNet: Leveraging Both Bird's-Eye-View and Perspective View Representations for 3D Object Detection
May 17, 2024



Recent advances in multi-view camera-only 3D object detection either rely on an accurate reconstruction of bird's-eye-view (BEV) 3D features or on traditional 2D perspective view (PV) image features. While both have their own pros and cons, few have found a way to stitch them together in order to benefit from "the best of both worlds". To this end, we explore a duo space (i.e., BEV and PV) 3D perception framework, in conjunction with some useful duo space fusion strategies that allow effective aggregation of the two feature representations. To the best of our knowledge, our proposed method, DuoSpaceNet, is the first to leverage two distinct feature spaces and achieves the state-of-the-art 3D object detection and BEV map segmentation results on nuScenes dataset.
Unlocking the Emotional World of Visual Media: An Overview of the Science, Research, and Impact of Understanding Emotion
Jul 25, 2023



The emergence of artificial emotional intelligence technology is revolutionizing the fields of computers and robotics, allowing for a new level of communication and understanding of human behavior that was once thought impossible. While recent advancements in deep learning have transformed the field of computer vision, automated understanding of evoked or expressed emotions in visual media remains in its infancy. This foundering stems from the absence of a universally accepted definition of "emotion", coupled with the inherently subjective nature of emotions and their intricate nuances. In this article, we provide a comprehensive, multidisciplinary overview of the field of emotion analysis in visual media, drawing on insights from psychology, engineering, and the arts. We begin by exploring the psychological foundations of emotion and the computational principles that underpin the understanding of emotions from images and videos. We then review the latest research and systems within the field, accentuating the most promising approaches. We also discuss the current technological challenges and limitations of emotion analysis, underscoring the necessity for continued investigation and innovation. We contend that this represents a "Holy Grail" research problem in computing and delineate pivotal directions for future inquiry. Finally, we examine the ethical ramifications of emotion-understanding technologies and contemplate their potential societal impacts. Overall, this article endeavors to equip readers with a deeper understanding of the domain of emotion analysis in visual media and to inspire further research and development in this captivating and rapidly evolving field.
Bodily expressed emotion understanding through integrating Laban movement analysis
Apr 05, 2023
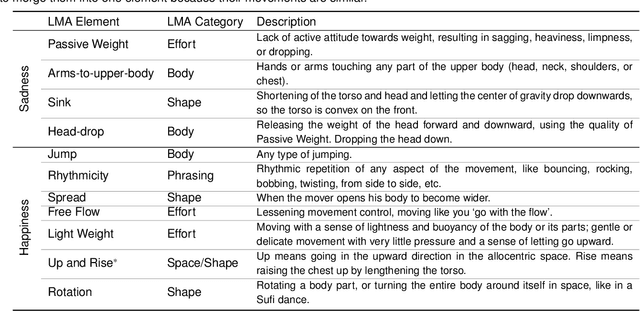
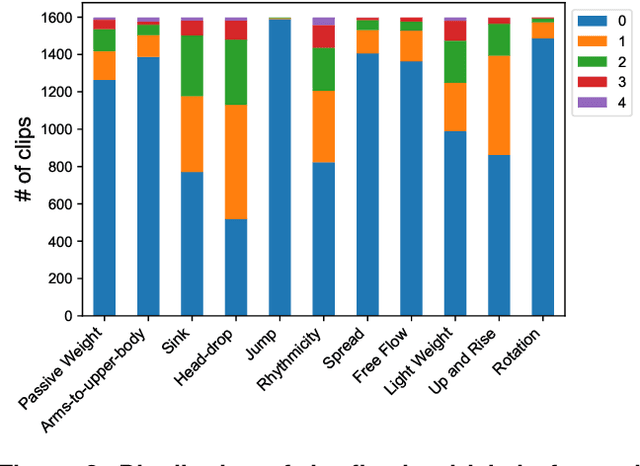
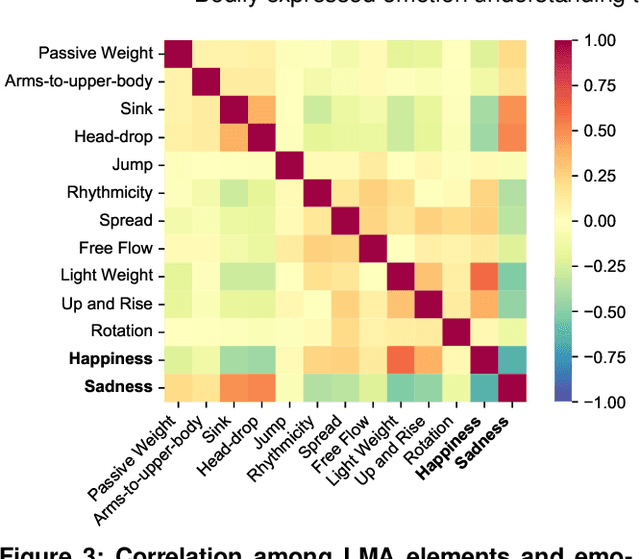
Body movements carry important information about a person's emotions or mental state and are essential in daily communication. Enhancing the ability of machines to understand emotions expressed through body language can improve the communication of assistive robots with children and elderly users, provide psychiatric professionals with quantitative diagnostic and prognostic assistance, and aid law enforcement in identifying deception. This study develops a high-quality human motor element dataset based on the Laban Movement Analysis movement coding system and utilizes that to jointly learn about motor elements and emotions. Our long-term ambition is to integrate knowledge from computing, psychology, and performing arts to enable automated understanding and analysis of emotion and mental state through body language. This work serves as a launchpad for further research into recognizing emotions through analysis of human movement.
Learning to Adapt to Online Streams with Distribution Shifts
Mar 02, 2023



Test-time adaptation (TTA) is a technique used to reduce distribution gaps between the training and testing sets by leveraging unlabeled test data during inference. In this work, we expand TTA to a more practical scenario, where the test data comes in the form of online streams that experience distribution shifts over time. Existing approaches face two challenges: reliance on a large test data batch from the same domain and the absence of explicitly modeling the continual distribution evolution process. To address both challenges, we propose a meta-learning approach that teaches the network to adapt to distribution-shifting online streams during meta-training. As a result, the trained model can perform continual adaptation to distribution shifts in testing, regardless of the batch size restriction, as it has learned during training. We conducted extensive experiments on benchmarking datasets for TTA, incorporating a broad range of online distribution-shifting settings. Our results showed consistent improvements over state-of-the-art methods, indicating the effectiveness of our approach. In addition, we achieved superior performance in the video segmentation task, highlighting the potential of our method for real-world applications.
MUG: Multi-human Graph Network for 3D Mesh Reconstruction from 2D Pose
May 25, 2022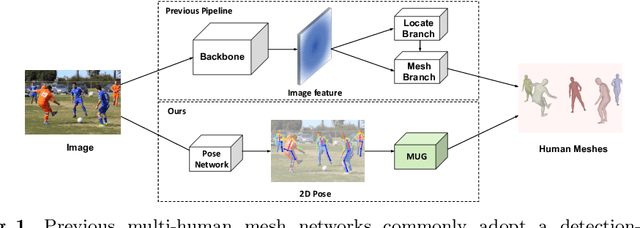
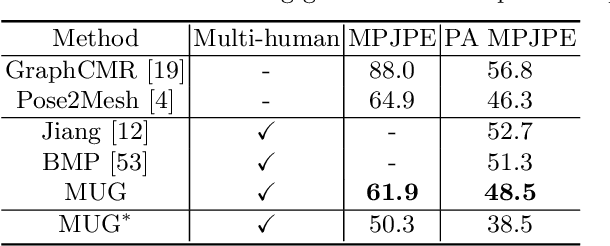
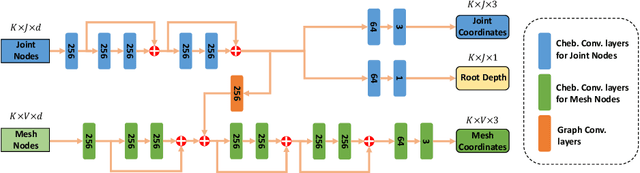
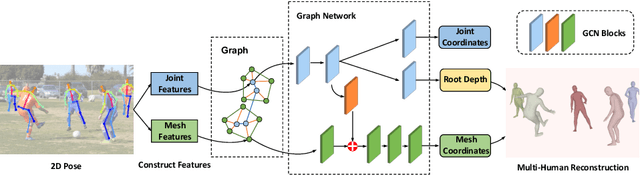
Reconstructing multi-human body mesh from a single monocular image is an important but challenging computer vision problem. In addition to the individual body mesh models, we need to estimate relative 3D positions among subjects to generate a coherent representation. In this work, through a single graph neural network, named MUG (Multi-hUman Graph network), we construct coherent multi-human meshes using only multi-human 2D pose as input. Compared with existing methods, which adopt a detection-style pipeline (i.e., extracting image features and then locating human instances and recovering body meshes from that) and suffer from the significant domain gap between lab-collected training datasets and in-the-wild testing datasets, our method benefits from the 2D pose which has a relatively consistent geometric property across datasets. Our method works like the following: First, to model the multi-human environment, it processes multi-human 2D poses and builds a novel heterogeneous graph, where nodes from different people and within one person are connected to capture inter-human interactions and draw the body geometry (i.e., skeleton and mesh structure). Second, it employs a dual-branch graph neural network structure -- one for predicting inter-human depth relation and the other one for predicting root-joint-relative mesh coordinates. Finally, the entire multi-human 3D meshes are constructed by combining the output from both branches. Extensive experiments demonstrate that MUG outperforms previous multi-human mesh estimation methods on standard 3D human benchmarks -- Panoptic, MuPoTS-3D and 3DPW.
MEBOW: Monocular Estimation of Body Orientation In the Wild
Nov 27, 2020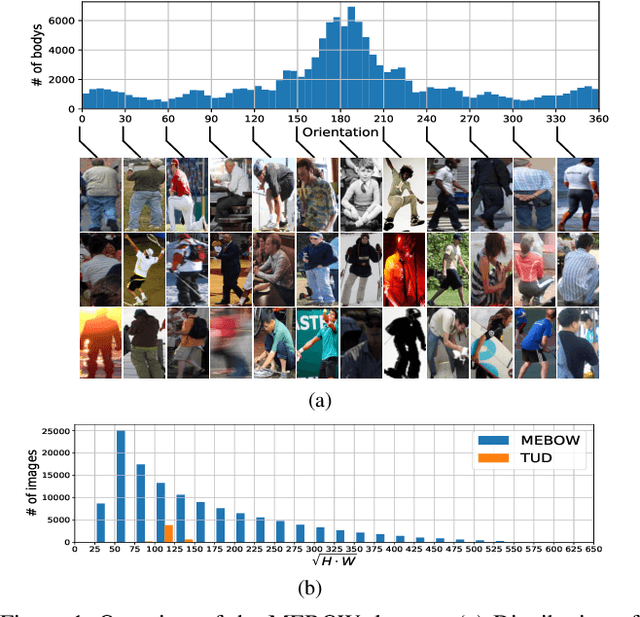
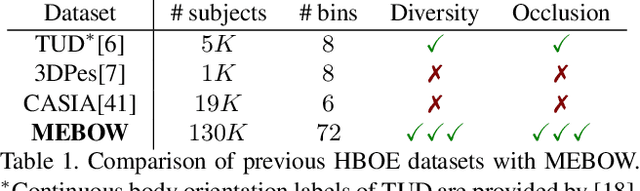
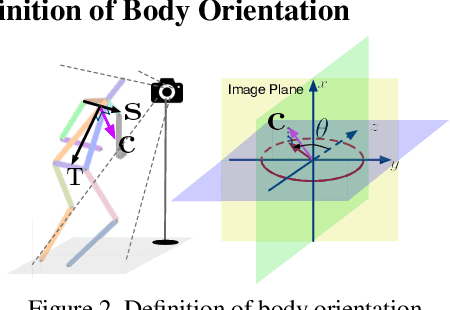
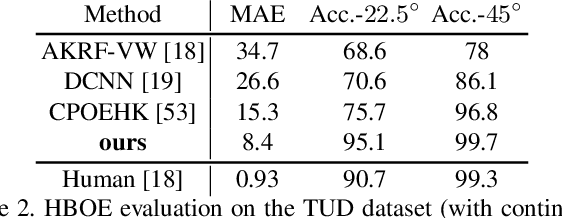
Body orientation estimation provides crucial visual cues in many applications, including robotics and autonomous driving. It is particularly desirable when 3-D pose estimation is difficult to infer due to poor image resolution, occlusion or indistinguishable body parts. We present COCO-MEBOW (Monocular Estimation of Body Orientation in the Wild), a new large-scale dataset for orientation estimation from a single in-the-wild image. The body-orientation labels for around 130K human bodies within 55K images from the COCO dataset have been collected using an efficient and high-precision annotation pipeline. We also validated the benefits of the dataset. First, we show that our dataset can substantially improve the performance and the robustness of a human body orientation estimation model, the development of which was previously limited by the scale and diversity of the available training data. Additionally, we present a novel triple-source solution for 3-D human pose estimation, where 3-D pose labels, 2-D pose labels, and our body-orientation labels are all used in joint training. Our model significantly outperforms state-of-the-art dual-source solutions for monocular 3-D human pose estimation, where training only uses 3-D pose labels and 2-D pose labels. This substantiates an important advantage of MEBOW for 3-D human pose estimation, which is particularly appealing because the per-instance labeling cost for body orientations is far less than that for 3-D poses. The work demonstrates high potential of MEBOW in addressing real-world challenges involving understanding human behaviors. Further information of this work is available at https://chenyanwu.github.io/MEBOW/.