 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity 3D Geometric Reconstruction of Pelvic Organs from MRI: A Hybrid Deep Learning and Iterative Optimization Approach
Jun 16, 2026Patient-specific 3D reconstruction of pelvic organ geometry from MRI is important for pelvic floor modeling and downstream patient-specific analysis. However, while previous studies have focused primarily on either image segmentation or downstream use of 3D models, the reconstruction of high-fidelity, high-quality geometries remains labor-intensive and poorly standardized. The study introduced a hybrid deformable shape modeling framework that integrates deep learning prediction with iterative optimization for the reconstruction of the bladder, uterus, and rectum. The framework consists of three core components: a geometry-aware multi-level deep learning architecture that preserves topological consistency of pelvic organs; a two-stage amortized optimization training strategy that balances global shape capture and local surface refinement; and a holistic synergy mechanism--where iterative optimization provides supervision for deep learning during the training phase, and during inference, deep learning rapidly predicts the global organ morphology, followed by iterative optimization to refine local surfaces and mesh quality. This framework demonstrated marked superiority in geometric fidelity than current mainstream deep learning-based organ reconstruction models. For individual anatomical structures, the reconstructed 3D geometries for the bladder, rectum, and uterus achieved significantly lower Chamfer Distance values and higher Dice Similarity Coefficient scores. In addition, while maintaining high computational efficiency, the proposed architecture yielded superior overall volumetric mesh quality. At the patient level, the framework achieved higher mean values for the 10 worst elements for both minSICN and minSIGE compared to traditional geometric post-processing algorithms.
Disentangling History and Propagation Dependencies in Cross-Subject Knee Contact Stress Prediction Using a Shared MeshGraphNet Backbone
Jan 13, 2026Background:Subject-specific finite element analysis accurately characterizes knee joint mechanics but is computationally expensive. Deep surrogate models provide a rapid alternative, yet their generalization across subjects under limited pose and load inputs remains unclear. It remains unclear whether the dominant source of prediction uncertainty arises from temporal history dependence or spatial propagation dependence. Methods:To disentangle these factors, we employed a shared MGN backbone with a fixed mesh topology. A dataset of running trials from nine subjects was constructed using an OpenSim-FEBio workflow. We developed four model variants to isolate specific dependencies: (1) a baseline MGN; (2) CT-MGN, incorporating a Control Transformer to encode short-horizon history; (3) MsgModMGN, applying state-conditioned modulation to message passing for adaptive propagation; (4) CT-MsgModMGN, combining both mechanisms. Models were evaluated using a rigorous grouped 3-fold cross-validation on unseen subjects.Results:The models incorporating history encoding significantly outperformed the baseline MGN and MsgModMGN in global accuracy and spatial consistency. Crucially, the CT module effectively mitigated the peak-shaving defect common in deep surrogates, significantly reducing peak stress prediction errors. In contrast, the spatial propagation modulation alone yielded no significant improvement over the baseline, and combining it with CT provided no additional benefit.Conclusion:Temporal history dependence, rather than spatial propagation modulation, is the primary driver of prediction uncertainty in cross-subject knee contact mechanics. Explicitly encoding short-horizon driver sequences enables the surrogate model to recover implicit phase information, thereby achieving superior fidelity in peak-stress capture and high-risk localization compared to purely state-based approaches.
Pelvic floor MRI segmentation based on semi-supervised deep learning
Nov 06, 2023



The semantic segmentation of pelvic organs via MRI has important clinical significance. Recently, deep learning-enabled semantic segmentation has facilitated the three-dimensional geometric reconstruction of pelvic floor organs, providing clinicians with accurate and intuitive diagnostic results. However, the task of labeling pelvic floor MRI segmentation, typically performed by clinicians, is labor-intensive and costly, leading to a scarcity of labels. Insufficient segmentation labels limit the precise segmentation and reconstruction of pelvic floor organs. To address these issues, we propose a semi-supervised framework for pelvic organ segmentation. The implementation of this framework comprises two stages. In the first stage, it performs self-supervised pre-training using image restoration tasks. Subsequently, fine-tuning of the self-supervised model is performed, using labeled data to train the segmentation model. In the second stage, the self-supervised segmentation model is used to generate pseudo labels for unlabeled data. Ultimately, both labeled and unlabeled data are utilized in semi-supervised training. Upon evaluation, our method significantly enhances the performance in the semantic segmentation and geometric reconstruction of pelvic organs, Dice coefficient can increase by 2.65% averagely. Especially for organs that are difficult to segment, such as the uterus, the accuracy of semantic segmentation can be improved by up to 3.70%.
Frequency Domain Decomposition Translation for Enhanced Medical Image Translation Using GANs
Nov 06, 2023Medical Image-to-image translation is a key task in computer vision and generative artificial intelligence, and it is highly applicable to medical image analysis. GAN-based methods are the mainstream image translation methods, but they often ignore the variation and distribution of images in the frequency domain, or only take simple measures to align high-frequency information, which can lead to distortion and low quality of the generated images. To solve these problems, we propose a novel method called frequency domain decomposition translation (FDDT). This method decomposes the original image into a high-frequency component and a low-frequency component, with the high-frequency component containing the details and identity information, and the low-frequency component containing the style information. Next, the high-frequency and low-frequency components of the transformed image are aligned with the transformed results of the high-frequency and low-frequency components of the original image in the same frequency band in the spatial domain, thus preserving the identity information of the image while destroying as little stylistic information of the image as possible. We conduct extensive experiments on MRI images and natural images with FDDT and several mainstream baseline models, and we use four evaluation metrics to assess the quality of the generated images. Compared with the baseline models, optimally, FDDT can reduce Fr\'echet inception distance by up to 24.4%, structural similarity by up to 4.4%, peak signal-to-noise ratio by up to 5.8%, and mean squared error by up to 31%. Compared with the previous method, optimally, FDDT can reduce Fr\'echet inception distance by up to 23.7%, structural similarity by up to 1.8%, peak signal-to-noise ratio by up to 6.8%, and mean squared error by up to 31.6%.
ReCLIP: Refine Contrastive Language Image Pre-Training with Source Free Domain Adaptation
Aug 04, 2023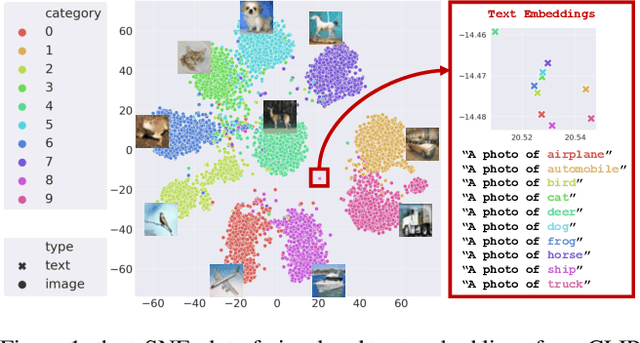
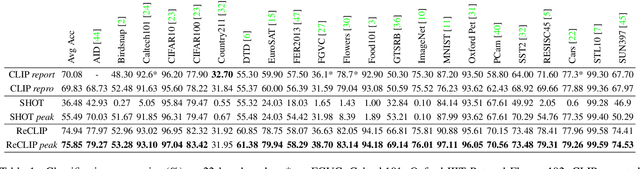
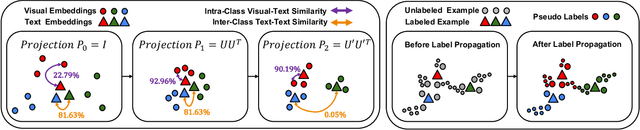
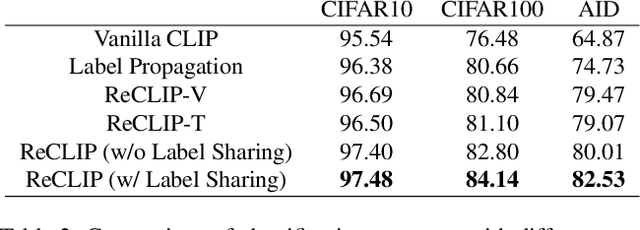
Large-scale Pre-Training Vision-Language Model such as CLIP has demonstrated outstanding performance in zero-shot classification, e.g. achieving 76.3% top-1 accuracy on ImageNet without seeing any example, which leads to potential benefits to many tasks that have no labeled data. However, while applying CLIP to a downstream target domain, the presence of visual and text domain gaps and cross-modality misalignment can greatly impact the model performance. To address such challenges, we propose ReCLIP, the first source-free domain adaptation method for vision-language models, which does not require any source data or target labeled data. ReCLIP first learns a projection space to mitigate the misaligned visual-text embeddings and learns pseudo labels, and then deploys cross-modality self-training with the pseudo labels, to update visual and text encoders, refine labels and reduce domain gaps and misalignments iteratively. With extensive experiments, we demonstrate ReCLIP reduces the average error rate of CLIP from 30.17% to 25.06% on 22 image classification benchmarks.
CameraPose: Weakly-Supervised Monocular 3D Human Pose Estimation by Leveraging In-the-wild 2D Annotations
Jan 08, 2023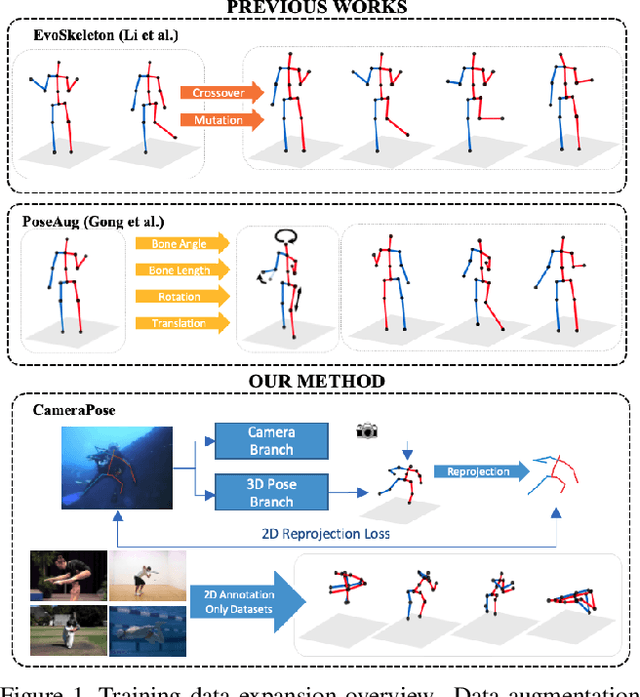
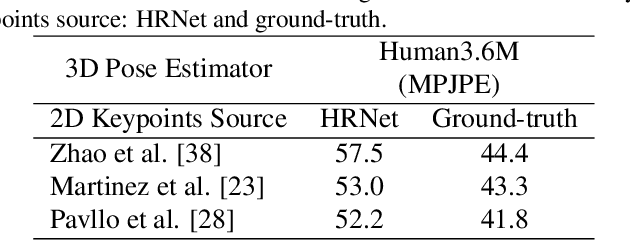
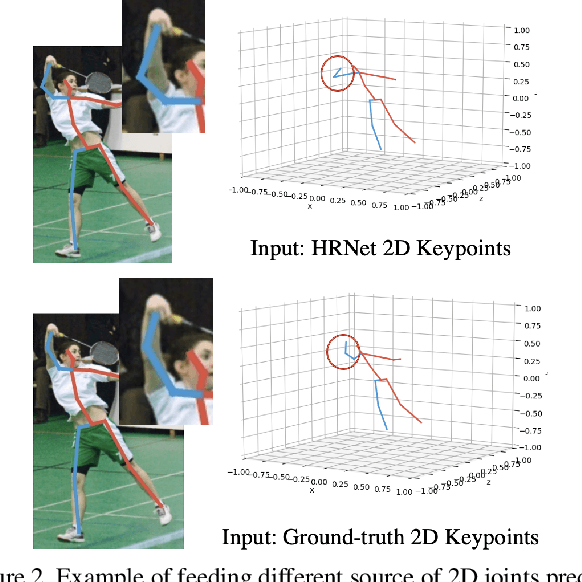

To improve the generalization of 3D human pose estimators, many existing deep learning based models focus on adding different augmentations to training poses. However, data augmentation techniques are limited to the "seen" pose combinations and hard to infer poses with rare "unseen" joint positions. To address this problem, we present CameraPose, a weakly-supervised framework for 3D human pose estimation from a single image, which can not only be applied on 2D-3D pose pairs but also on 2D alone annotations. By adding a camera parameter branch, any in-the-wild 2D annotations can be fed into our pipeline to boost the training diversity and the 3D poses can be implicitly learned by reprojecting back to 2D. Moreover, CameraPose introduces a refinement network module with confidence-guided loss to further improve the quality of noisy 2D keypoints extracted by 2D pose estimators. Experimental results demonstrate that the CameraPose brings in clear improvements on cross-scenario datasets. Notably, it outperforms the baseline method by 3mm on the most challenging dataset 3DPW. In addition, by combining our proposed refinement network module with existing 3D pose estimators, their performance can be improved in cross-scenario evaluation.
De-Noising of Photoacoustic Microscopy Images by Deep Learning
Jan 12, 2022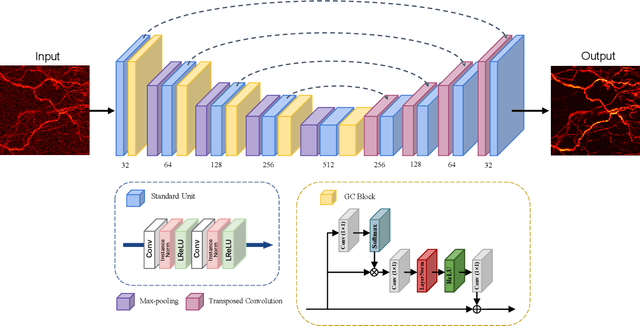
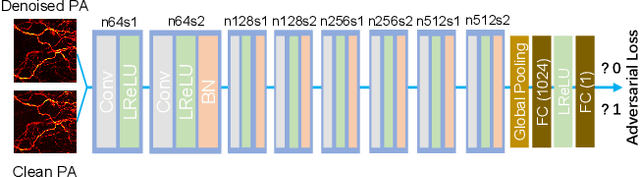
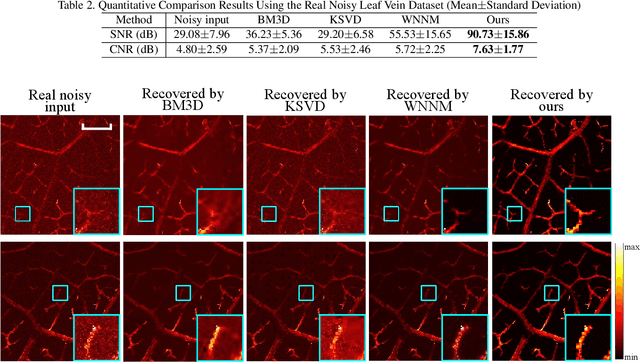
As a hybrid imaging technology, photoacoustic microscopy (PAM) imaging suffers from noise due to the maximum permissible exposure of laser intensity, attenuation of ultrasound in the tissue, and the inherent noise of the transducer. De-noising is a post-processing method to reduce noise, and PAM image quality can be recovered. However, previous de-noising techniques usually heavily rely on mathematical priors as well as manually selected parameters, resulting in unsatisfactory and slow de-noising performance for different noisy images, which greatly hinders practical and clinical applications. In this work, we propose a deep learning-based method to remove complex noise from PAM images without mathematical priors and manual selection of settings for different input images. An attention enhanced generative adversarial network is used to extract image features and remove various noises. The proposed method is demonstrated on both synthetic and real datasets, including phantom (leaf veins) and in vivo (mouse ear blood vessels and zebrafish pigment) experiments. The results show that compared with previous PAM de-noising methods, our method exhibits good performance in recovering images qualitatively and quantitatively. In addition, the de-noising speed of 0.016 s is achieved for an image with $256\times256$ pixels. Our approach is effective and practical for the de-noising of PAM images.
MEBOW: Monocular Estimation of Body Orientation In the Wild
Nov 27, 2020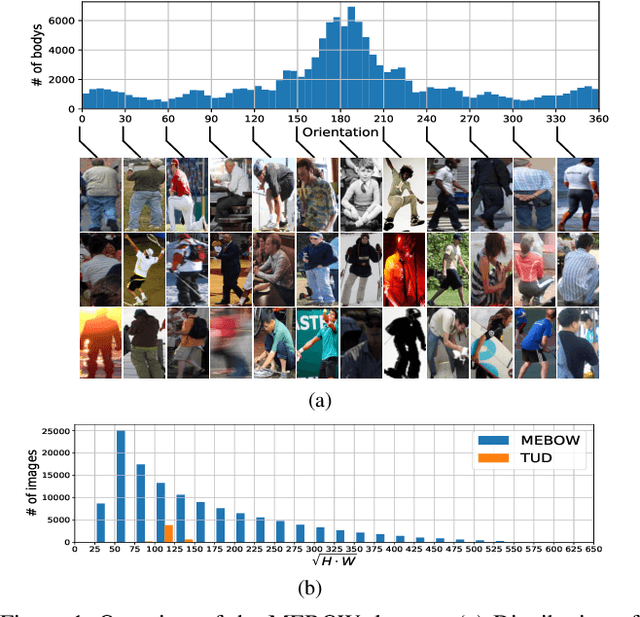
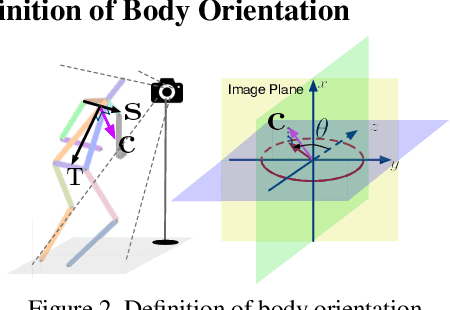
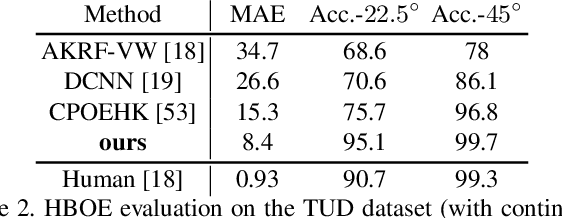
Body orientation estimation provides crucial visual cues in many applications, including robotics and autonomous driving. It is particularly desirable when 3-D pose estimation is difficult to infer due to poor image resolution, occlusion or indistinguishable body parts. We present COCO-MEBOW (Monocular Estimation of Body Orientation in the Wild), a new large-scale dataset for orientation estimation from a single in-the-wild image. The body-orientation labels for around 130K human bodies within 55K images from the COCO dataset have been collected using an efficient and high-precision annotation pipeline. We also validated the benefits of the dataset. First, we show that our dataset can substantially improve the performance and the robustness of a human body orientation estimation model, the development of which was previously limited by the scale and diversity of the available training data. Additionally, we present a novel triple-source solution for 3-D human pose estimation, where 3-D pose labels, 2-D pose labels, and our body-orientation labels are all used in joint training. Our model significantly outperforms state-of-the-art dual-source solutions for monocular 3-D human pose estimation, where training only uses 3-D pose labels and 2-D pose labels. This substantiates an important advantage of MEBOW for 3-D human pose estimation, which is particularly appealing because the per-instance labeling cost for body orientations is far less than that for 3-D poses. The work demonstrates high potential of MEBOW in addressing real-world challenges involving understanding human behaviors. Further information of this work is available at https://chenyanwu.github.io/MEBOW/.
Adherent Mist and Raindrop Removal from a Single Image Using Attentive Convolutional Network
Sep 03, 2020

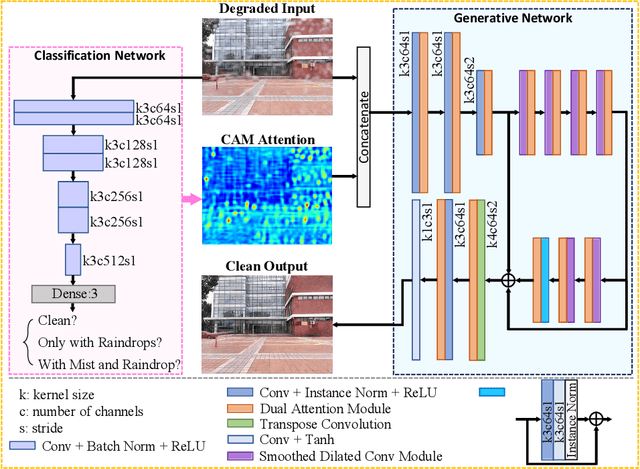

Temperature difference-induced mist adhered to the windshield, camera lens, etc. are often inhomogeneous and obscure, which can easily obstruct the vision and degrade the image severely. Together with adherent raindrops, they bring considerable challenges to various vision systems but without enough attention. Recent methods for similar problems typically use hand-crafted priors to generate spatial attention maps. In this work, we propose to visually remove the adherent mist and raindrop jointly from a single image using attentive convolutional neural networks. We apply classification activation map attention to our model to strengthen the spatial attention without hand-crafted priors. In addition, the smoothed dilated convolution is adopted to obtain a large receptive field without spatial information loss, and the dual attention module is utilized for efficiently selecting channels and spatial features. Our experiments show our method achieves state-of-the-art performance, and demonstrate that this underrated practical problem is critical to high-level vision scenes.
Photoacoustic Microscopy with Sparse Data Enabled by Convolutional Neural Networks for Fast Imaging
Jun 08, 2020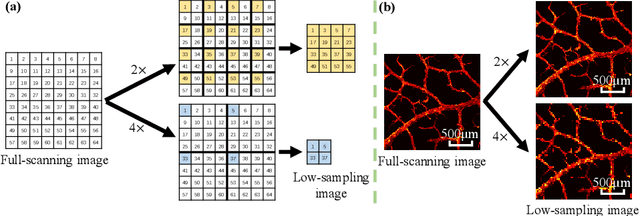
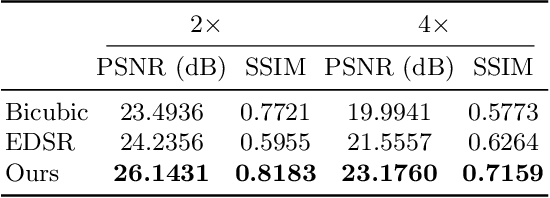
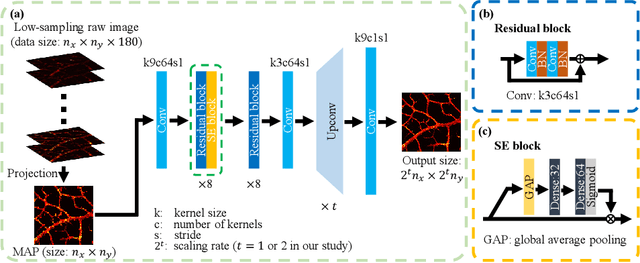

Photoacoustic microscopy (PAM) has been a promising biomedical imaging technology in recent years. However, the point-by-point scanning mechanism results in low-speed imaging, which limits the application of PAM. Reducing sampling density can naturally shorten image acquisition time, which is at the cost of image quality. In this work, we propose a method using convolutional neural networks (CNNs) to improve the quality of sparse PAM images, thereby speeding up image acquisition while keeping good image quality. The CNN model utilizes both squeeze-and-excitation blocks and residual blocks to achieve the enhancement, which is a mapping from a 1/4 or 1/16 low-sampling sparse PAM image to a latent fully-sampled image. The perceptual loss function is applied to keep the fidelity of images. The model is mainly trained and validated on PAM images of leaf veins. The experiments show the effectiveness of our proposed method, which significantly outperforms existing methods quantitatively and qualitatively. Our model is also tested using in vivo PAM images of blood vessels of mouse ears and eyes. The results show that the model can enhance the image quality of the sparse PAM image of blood vessels from several aspects, which may help fast PAM and facilitate its clinical applications.